






1.本次需求为同库分表
1.1 引入pom依赖
<!-- sharding-jdbc分库分表 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
1.2 DruidConfig修改
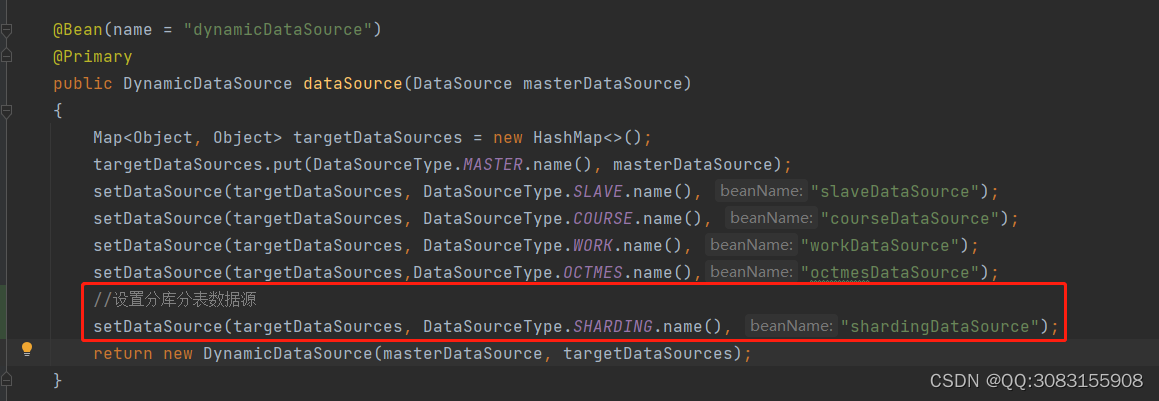
1.3 新增ShardingDataSourceConfig
package com.ruoyi.framework.config;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.shardingsphere.api.config.sharding.KeyGeneratorConfiguration;
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import com.ruoyi.framework.config.properties.DruidProperties;
/**
* sharding 配置信息
*
* @author ruoyi
*/
@Configuration
public class ShardingDataSourceConfig
{
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
/*@Bean
@ConfigurationProperties("spring.datasource.druid.order1")
@ConditionalOnProperty(prefix = "spring.datasource.druid.order1", name = "enabled", havingValue = "true")
public DataSource order1DataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean
@ConfigurationProperties("spring.datasource.druid.order2")
@ConditionalOnProperty(prefix = "spring.datasource.druid.order2", name = "enabled", havingValue = "true")
public DataSource order2DataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}*/
@Bean(name = "shardingDataSource")
public DataSource shardingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource) throws SQLException
{
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("master", masterDataSource);
// sys_order 表规则配置
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("oct_hr_user_clock", "master.oct_hr_user_clock_$->{0..4}");
// 配置分库策略
//orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "order$->{user_id % 2 + 1}"));
// 配置分表策略
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "oct_hr_user_clock_$->{id % 5}"));
// 分布式主键
orderTableRuleConfig.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "id"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, getProperties());
return dataSource;
}
/**
* 系统参数配置
*/
private Properties getProperties()
{
Properties shardingProperties = new Properties();
shardingProperties.put("sql.show", true);
return shardingProperties;
}
}1.4 application.yml配置
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://192.168.1.86:3306/octv_hr_prod?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8&allowMultiQueries=true
username: root
password: root
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
webStatFilter:
enabled: true
statViewServlet:
enabled: true
# 设置白名单,不填则允许所有访问
allow:
url-pattern: /druid/*
# 控制台管理用户名和密码
login-username:
login-password:
filter:
stat:
enabled: true
# 慢SQL记录
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: true
wall:
config:
multi-statement-allow: true
1.5在分表的方法上加上切换数据源注解

1.6测试

前提:
1)手动创建表oct_hr_user_clock_0到oct_hr_user_clock_4














 3187
3187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









