






1.数据库同步ES常见设计方案
| 序号 | 同步方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 同步双写 | 业务逻辑简单 | ①硬编码:有写入mysql的地方都需要添加写入ES的代码;业务强耦合; ②存在双写失败丢失数据的风险; ③性能较差:本来mysql的性能就不是很高,再加上一个ES,系统的性能必然会下降 |
| 2 | 异步双写(MQ) | ①性能高; ②不存在数据丢失问题 | ①硬编码问题:依然存在业务强耦合; ②复杂度增加:系统中增加了mq的代码; ③可能存在延时的问题:程序的写入性能提高了,但是由于MQ的消费可能由于网络或其他原因导致用户写入的数据不一定马上看到,造成延时 |
| 3 | 定时增量同步 | ①不改变原来的代码,没有侵入性、没有硬编码; ②没有业务强耦合; ③Worker代码编写简单不需要考虑增删改查 | ①时效性较差,由于定时器工作周期不可能设置在秒级,所以实时性不是很好; ②对数据库有一定轮询压力; ③业务每次更新都需要将更新时间写入 |
| 4 | 开源同步插件 | ①无侵入代码无感知; ②接入相对比较简单,只需配置即可 | ①每次处理单表,聚合能力太差; ②业务每次更新都需要将更新时间写入 |
| 5 | 基于binlog数据同步 | ①无代码侵入;原有系统不需要任何改变,没有感知; ②性能高; ③业务解耦,不需要关注原来系统的业务逻辑 | ①构建Binlog系统复杂; ②存在延时风险。 |
2、同步数据方案选型
2.1第1种方案
第一种方案跟第二种方案没有优势,放弃
2.2第2种方案
1.项目场景复杂,存在初始数据需刷入和后面每天每天一次的数据定时更新,可考虑
2.技术选型
- 选型1:pgsql + SpringBoot + kafka + es
- 选型2:pgsql + SpringBoot + kafka + logstash + es
2.3第三种方案
1.根据项目历史数据,每天都是定时定点同步数据,可考虑
2.技术选型
- pgsql + springboot + quatz + es
2.4第4种方案
1.根据项目一期项目设及二期对象而言,项目目前是都是单表,可考虑
2.技术选型
- pgsql + logstash + es
2.5第五种方案
同步中间件有比较成熟的方案使用canal。因为项目使用的postgresql,目前找到一款中间件,但是该方案需要修改pgsql配置,并且需要配置服务器,暂不考虑
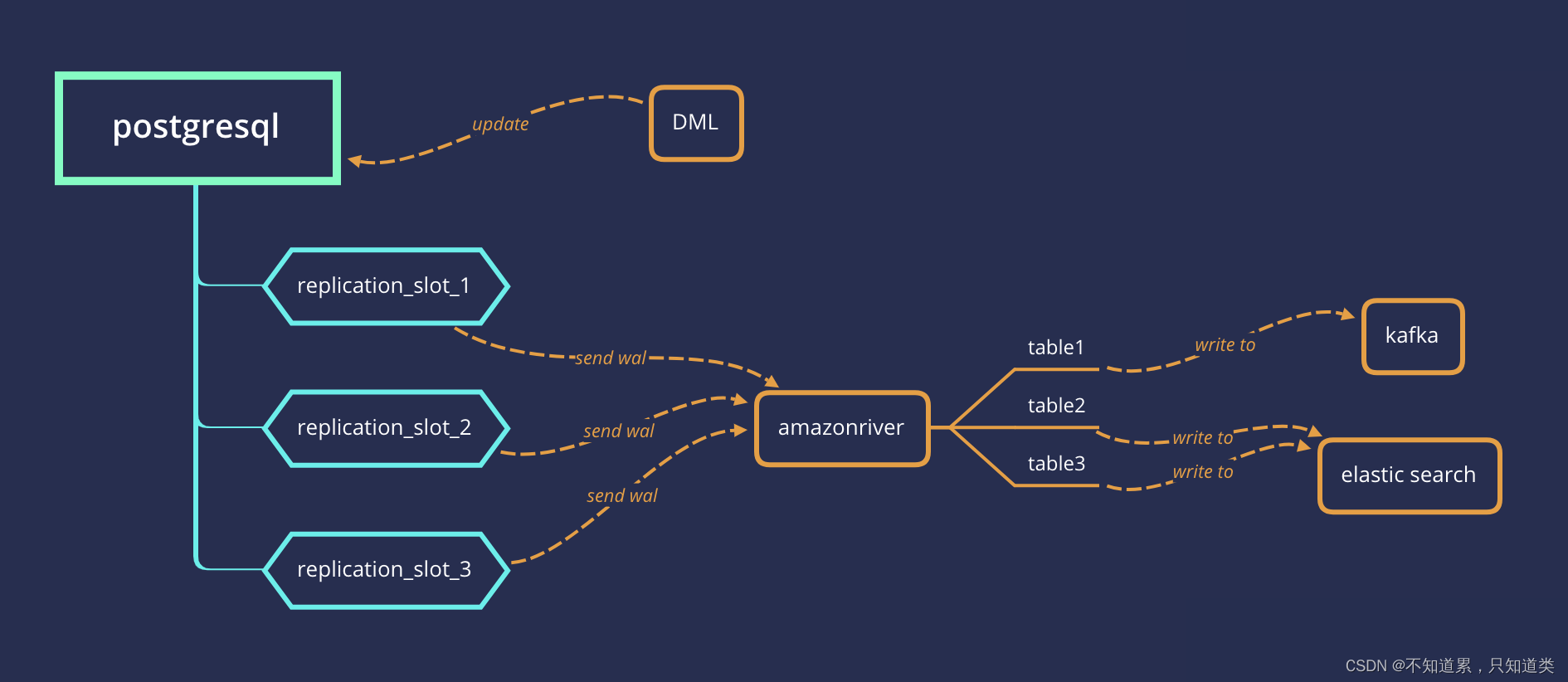
- 参考连接:https://github.com/hellobike/amazonriver
3.流程思路
3.1同步数据
1.选择符合项目的整体设计
2.根据同步的数据,判断是新增、更新、删除
3.根据不同类型的数据分别整合之后写入到数据库,并将处理完的数据整合到list进行发送
4.如果发送失败则记录操作日志,包括数据ID,失败时间,失败原因,方便定位问题
5.消费端监听到推数后,对不同数据调用ES不同API根据ID,将es数据覆盖
6.如果覆盖es数据失败,记录操作日志,同第4点
7.对数据增删改操作都使用update_time作为是否同步es标记,也就是将更新时间设计为当前时间
3.2查询数据
1.用户在调用查询接口是,在网关层对相关接口进行限流校验
2.如果流量单位时间内未满,则继续调用查询接口直接查询ES
3.如果流量单位时间内已满,则提示用户请稍后再操作
4.如果ES查询数据失败,则启用原接口查询数据库
5.如果成功,则返回结果
3.3定时任务扫描
1.定时扫描数据库数据与es有效数据条数是否相等
2.如果相等,则记录扫描成功记录,当做成功tag
3.如果不相等,拿最后一次成功时间作为起始点再次校验数据条数是否相等
4.如果相等,则记录扫描成功记录
5.如果不相等,则取出不相等的数据重新推到kafka
4.安全考虑
4.1系统安全
1.查询方面,增加限流控制,防止人为机刷
|-目前考虑针对接口层面加入限流
1.1 ng根据url和IP进行对应限流 - 入口限流
1.2 Google Guava库ateLimiter - 节点限流
1.3 com.baidubce.formula - 节点限流
1.4 redis lua脚本限流 - 分布式
4.2数据安全
1.kafka相应的ack级别需要设置为0
2.新建一张fulsthDataToEs记录表(或者用redis),每往kafka中推送成功一条数据,则插入一条数据
3.消费者每消费成功后,将数据库数据逻辑删除(或在redis中delete)
4.定时任务定时扫描记录表,查询是否有存活的数据,有则重新推送(注意避开其他定时任务)
5.需要注意重复推送问题















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









