







目录
引言
本篇文章主要是关于内置函数和一些函数的进阶用法,除此之外,还有一些基础的内置模块的使用
4. 内置函数和推导式
4.1. 匿名函数
传统的函数的定义包括了:函数名 + 函数体。
def send_email():
pass
# 1. 执行
send_email()
# 2. 当做列表元素
data_list = [send_email, send_email, send_email ]
# 3. 当做参数传递
other_function(send_email)匿名函数,则是基于lambda表达式实现定义一个可以没有名字的函数,例如:
a = lambda x:x+100
print(a)a = lambda x: x + 100
print(a)
print(a(10))
#
<function <lambda> at 0x000001CA528461F0>
110基于Lambda定义的函数格式为:lambda 参数:函数体
- 参数,支持任意参数。
lambda x: 函数体
lambda x1,x2: 函数体
lambda *args, **kwargs: 函数体- 函数体,只能支持单行的代码。
def xxx(x):
return x + 100
lambda x: x + 100- 返回值,默认将函数体单行代码执行的结果返回给函数的执行这。
func = lambda x: x + 100
v1 = func(10)
print(v1) # 110匿名函数适用于简单的业务处理,可以快速并简单的创建函数。
4.1.2. 扩展:三元运算
简单的函数,可以基于lambda表达式实现。
简单的条件语句,可以基于三元运算实现,例如:
num = input("请写入内容")
data = "帅哥" if "jiaoxingk" in num else "吊毛"
print(data)
# 结果 = 条件成立时 if 条件 else 不成立lambda表达式和三元运算没有任何关系,属于两个独立的知识点。
掌握三元运算之后,以后再编写匿名函数时,就可以处理再稍微复杂点的情况了,例如:
func = lambda x: "大了" if x > 66 else "小了"
v1 = func(1)
print(v1) # "小了"
v2 = func(100)
print(v2) # "大了"4.2. 生成器
生成器是由函数+yield关键字创造出来的写法,在特定情况下,用他可以帮助我们节省内存。
- 生成器函数,但函数中有yield存在时,这个函数就是生产生成器函数。
def func():
print(111)
yield 1- 生成器对象,执行生成器函数时,会返回一个生成器对象。
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
print(444)
data = func()
# 执行生成器函数func,返回的生成器对象。
# 注意:执行生成器函数时,函数内部代码不会执行。生成器的特点是,记录在函数中的执行位置,下次执行next时,会从上一次的位置基础上再继续向下执行。
也就是在运行程序的时候,遇到了yield就是停下来不执行了,并且返回来,当你执行一次next的时候,他就会继续往下面执行
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
print(444)
data = func()
print(data.__next__())
print(data.__next__())
print(data.__next__())
data.__next__()
# 执行生成器函数func,返回的生成器对象。
# 注意:执行生成器函数时,函数内部代码不会执行。
其中,x.__next__() , 和next(x)的功能是一样的,都是继续执行生成器函数
4.2.1. 应用场景
- 假设要让你生成 300w个随机的4位数,并打印出来。
-
- 在内存中一次性创建300w个
- 动态创建,用一个创建一个。
import random
data_list = []
for i in range(300000000):
val = random.randint(1000, 9999)
data_list.append(val)
# 再使用时,去 data_list 中获取即可。
# ...import random
def gen_random_num(max_count):
counter = 0
while counter < max_count:
yield random.randint(1000, 9999)
counter += 1
data_list = gen_random_num(3000000)
# 再使用时,去 data_list 中获取即可。所以,当以后需要我们在内存中创建很多数据时,可以想着用基于生成器来实现一点一点生成(用一点生产一点),以节省内存的开销。
4.2.2. 扩展
send(): 发送一个值到函数内部,并且执行,从下面的案例,可以看出,send的值传给了上一个返回的yiled里面
def func():
print(111)
v1 = yield 1
print(v1)
print(222)
v2 = yield 2
print(v2)
print(333)
v3 = yield 3
print(v3)
print(444)
data = func()
n1 = data.send(None)
print(n1)
n2 = data.send(666)
print(n2)
n3 = data.send(777)
print(n3)
n4 = data.send(888)
print(n4)
#
111
1
222
2
777
333
3
888
4444.3. 内置函数
Python内部为我们提供了很多方便的内置函数,在此整理出来36个给大家来讲解。
- abs,绝对值
v = abs(-10)- pow,指数
v1 = pow(2,5) # 2的5次方 2**5
print(v1)- sum,求和
v1 = sum([-11, 22, 33, 44, 55]) # 可以被迭代-for循环
print(v1)- divmod,求商和余数
v1, v2 = divmod(9, 2)
print(v1, v2)- round,小数点后n位(四舍五入)
v1 = round(4.11786, 2)
print(v1) # 4.12- min,最小值
v1 = min(11, 2, 3, 4, 5, 56)
print(v1) # 2- max,最大值
v1 = max(11, 2, 3, 4, 5, 56)
print(v1)
v2 = max([11, 22, 33, 44, 55])
print(v2)- all,是否全部为True
v1 = all( [11,22,44,""] ) # False- any,是否存在True
v2 = any([11,22,44,""]) # True
- bin,十进制转二进制
- oct,十进制转八进制
- hex,十进制转十六进制
- ord,获取字符对应的unicode码点(十进制)
v1 = ord("荒")
print(v1, hex(v1))- chr,根据码点(十进制)获取对应字符
v1 = chr(27494)
print(v1)- bytes,utf-8、gbk编码
v1 = "jiaoxingk" # str类型
v2 = v1.encode('utf-8') # bytes类型
v3 = bytes(v1,encoding="utf-8") # bytes类型- tuple
- set
- type,获取数据类型
v1 = "123"
if type(v1) == str:
pass
else:
pass- range 生成0-9的列表
range(10)
# range(0, 10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]- enumerate
v1 = ["jiaoxingk", "jiaoxingk", 'root']
for num, value in enumerate(v1, 1):
print(num, value)- hash
v1 = hash("jiaoxingk")- zip
v1 = [11, 22, 33, 44, 55, 66]
v2 = [55, 66, 77, 88]
v3 = [10, 20, 30, 40, 50]
result = zip(v1, v2, v3)
for item in result:
print(item)
# (11, 55, 10)
(22, 66, 20)
(33, 77, 30)
(44, 88, 40)- sorted,排序
v1 = sorted([11,22,33,44,55])4.4. 推导式
推导式是Python中提供了一个非常方便的功能,可以让我们通过一行代码实现创建list、dict、tuple、set 的同时初始化一些值。
请创建一个列表,并在列表中初始化:0、1、2、3、4、5、6、7、8、9...299 整数元素。
data = []
for i in range(300):
data.append(i)- 列表
num_list = [ i for i in range(10)]
num_list = [ [i,i] for i in range(10)]
num_list = [ [i,i] for i in range(10) if i > 6 ]- 集合
num_set = { i for i in range(10)}
num_set = { (i,i,i) for i in range(10)}
num_set = { (i,i,i) for i in range(10) if i>3}- 字典
num_dict = { i:i for i in range(10)}
num_dict = { i:(i,11) for i in range(10)}
num_dict = { i:(i,11) for i in range(10) if i>7}- 元组,不同于其他类型。
# 不会立即执行内部循环去生成数据,而是得到一个生成器。
data = (i for i in range(10))
print(data)
for item in data:
print(item)5. 模块
掌握Python中常用模块的使用方法。
5.1. 自定义模块
5.1.1. 模块和包
如果一个程序只有100行代码,那肯定一个py文件就能写,但是当你有10w行代码的时候,全部放在一个py文件肯定是不适合的,这个时候就需要做一些分配,每个py文件代表单独一个功能
在Python中一般对文件称呼也就是模块
- 一个py文件,模块(module)。
- 含多个py文件的文件夹,包(package)。
注意:在包(文件夹)中有一个默认内容为空的__init__.py的文件,一般用于描述当前包的信息(在导入他下面的模块时,也会自动加载)。
5.1.2. 导入
当定义好一个模块或包之后,如果想要使用其中定义的功能,必须要先导入,然后再能使用。
导入,其实就是将模块或包加载的内存中,以后再去内存中去拿就行。
关于导如时的路径:
在Python内部默认设置了一些路径,导入模块或包时,都会按照指定顺序逐一去特定的路径查找。
import sys
print(sys.path)想要导入任意的模块和包,都必须写在如下路径下,才能被找到。
也可以自动手动在sys.path中添加指定路径,然后再导入可以,例如:
import sys
sys.path.append("路径A")
import xxxxx # 导入路径A下的一个xxxxx.py文件- 写模块名称时,不能和内置和第三方的同名。
- 项目执行文件一般都在项目根目录,如果执行文件嵌套的内存目录,就需要自己手动在sys.path中添加路径。
- pycharm中默认会将项目目录加入到sys.path中
关于导入的方式:
导入本质上是将某个文件中的内容先加载到内存中,然后再去内存中拿过来使用。而在Python开发中常用的导入的方式有2类方式,每类方式都也多种情况。
- 第一类:import xxxx(开发中,一般多用于导入sys.path目录下的一个py文件)
- 第二类:from xxx import xxx 【常用】,一般适用于多层嵌套和导入模块中某个成员的情况。
提示:基于from模式也可以支持 from many import *,即:导入一个模块中所有的成员(可能会重名,所以用的少)。
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ ├── tencent
│ │ ├── __init__.py
│ │ ├── sms.py
│ │ └── wechat.py
│ └── utils.py
├── many.py
└── run.py5.1.3. 相对导入
在导入模块时,对于 from xx import xx这种模式,还支持相对到导入。
切记,相对导入只能用在包中的py文件中(即:嵌套在文件中的py文件才可以使用,项目根目录下无法使用)。
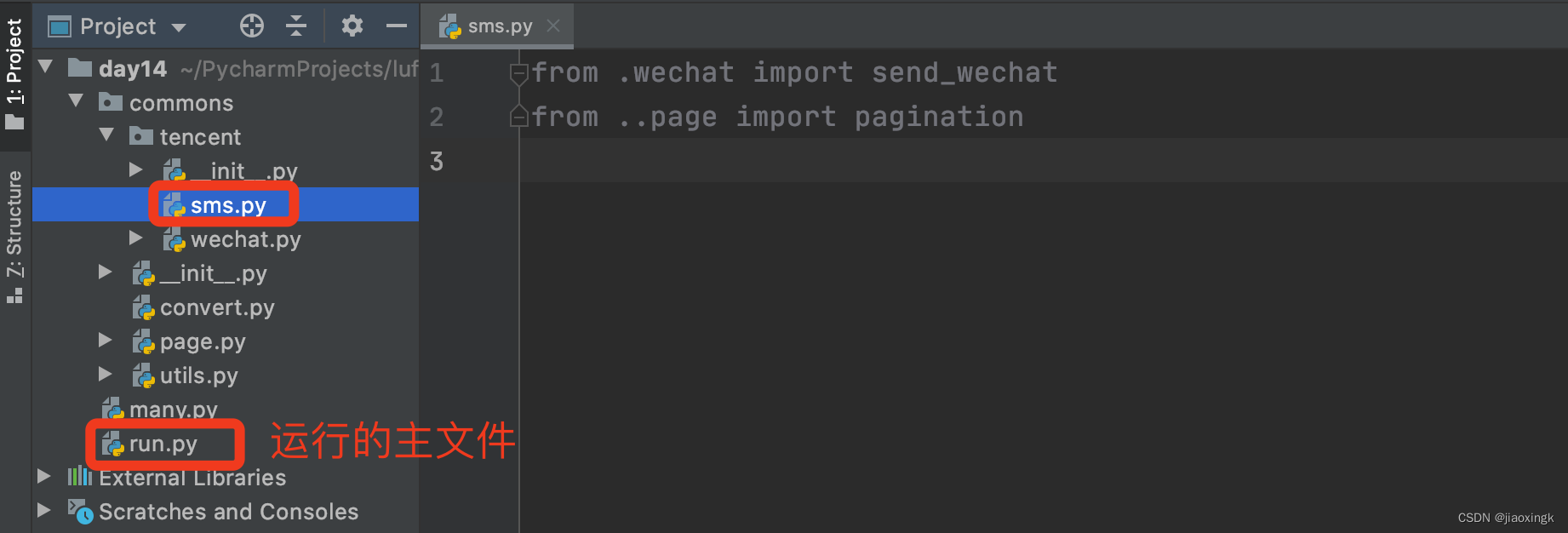
5.1.4. 导入别名
如果项目中导入 成员/模块/包 有重名,那么后导入的会覆盖之前导入,为了避免这种情况的发生,Python支持重命名,即:
from xxx.xxx import xx as xo5.1.5. 主文件
- 执行一个py文件时
__name__ = "__main__"- 导入一个py文件时
__name__ = "模块名"主文件,其实就是在程序执行的入口文件,例如:
我们通常是执行 run.py 去运行程序,其他的py文件都是一些功能代码。当我们去执行一个文件时,文件内部的 __name__变量的值为 __main__,所以,主文件经常会看到:
import many
from commons import page
from commons import utils
def start():
v1 = many.show()
v2 = page.pagination()
v3 = utils.encrypt()
if __name__ == '__main__':
start()只有是以主文件的形式运行此脚本时start函数才会执行,被导入时则不会被执行。
5.2. 第三方模块
Python内部提供的模块有限,所以在平时在开发的过程中,经常会使用第三方模块。
而第三方模块必须要先安装才能可以使用,下面介绍常见的3中安装第三方模块的方式。
5.2.1. pip(最常用)
最常用的方式,也是最方便的
pip其实是一个第三方模块包管理工具,默认安装Python解释器时自动会安装,默认目录:
MAC系统,即:Python安装路径的bin目录下
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3.9
Windows系统,即:Python安装路径的scripts目录下
C:\Python39\Scripts\pip3.exe
C:\Python39\Scripts\pip3.9.exe提示:为了方便在终端运行pip管理工具,我们也会把它所在的路径添加到系统环境变量中。
pip3 install 模块名称默认安装的是最新的版本,如果想要指定版本:
pip3 install 模块名称==版本
例如:
pip3 install django==2.25.2.1.1. pip更新
上图的黄色字体提示:目前我电脑上的pip是20.2.3版本,最新的是 20.3.3 版本,如果想要升级为最新的版本,可以在终端执行他提示的命令:
/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -m pip install --upgrade pip注意:根据自己电脑的提示命令去执行。
5.2.1.2. 豆瓣源
pip默认是去 https://pypi.org 去下载第三方模块(本质上就是别人写好的py代码),国外的网站速度会比较慢,为了加速可以使用国内的豆瓣源。
- 一次性使用
pip3.9 install 模块名称 -i https://pypi.douban.com/simple/- 永久使用
-
- 配置
# 在终端执行如下命令
pip3.9 config set global.index-url https://pypi.douban.com/simple/
# 执行完成后,提示在我的本地文件中写入了豆瓣源,以后就会默认使用豆瓣源了。-
- 使用
pip3.9 install 模块名称写在最后,也还有其他的源可供选择(豆瓣应用广泛)。
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/5.2.2. 源码
如果要安装的模块在pypi.org中不存在 或 因特殊原因无法通过pip install 安装时,可以直接下载源码,然后基于源码安装,例如:
- 下载requests源码(压缩包zip、tar、tar.gz)并解压。
下载地址:https://pypi.org/project/requests/#files- 进入目录
- 执行编译和安装命令
python3 setup.py build
python3 setup.py install5.2.3. wheel
wheel是Python的第三方模块包的文件格式的一种,我们也可以基于wheel去安装一些第三方模块。
- 安装wheel格式支持,这样pip再安装第三方模块时,就可以处理wheel格式的文件了。
pip3.9 install wheel- 下载第三方的包(wheel格式),例如:requests · PyPI
- 进入下载目录,在终端基于pip直接安装
pip install xxx.whl
无论通过什么形式去安装第三方模块,默认模块的安装路径在:
Max系统:
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages
Windows系统:
C:\Python39\Lib\site-packages\提醒:这个目录在sys.path中,所以我们直接在代码中直接导入下载的第三方包是没问题的。
5.3. 内置模块
内置模块有很多 , 以下是几个比较常见的内置模块
5.3.1. os
import os
# 1. 获取当前脚本绝对路径
"""
abs_path = os.path.abspath(__file__)
print(abs_path)
"""
# 2. 获取当前文件的上级目录
"""
base_path = os.path.dirname( os.path.dirname(路径) )
print(base_path)
"""
# 3. 路径拼接
"""
p1 = os.path.join(base_path, 'xx')
print(p1)
p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png')
print(p2)
"""
# 4. 判断路径是否存在
"""
exists = os.path.exists(p1)
print(exists)
"""
# 5. 创建文件夹
"""
os.makedirs(路径)
"""
"""
path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
if not os.path.exists(path):
os.makedirs(path)
"""
# 6. 是否是文件夹
"""
file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png')
is_dir = os.path.isdir(file_path)
print(is_dir) # False
folder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
is_dir = os.path.isdir(folder_path)
print(is_dir) # True
"""
# 7. 删除文件或文件夹
"""
os.remove("文件路径")
"""
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""- listdir,查看目录下所有的文件
- walk,查看目录下所有的文件(含子孙文件)
import os
data = os.listdir("/commons")
print(data)
# ['convert.py', '__init__.py', 'page.py', '__pycache__', 'utils.py', 'tencent']
"""
要遍历一个文件夹下的所有文件,例如:遍历文件夹下的所有mp4文件
"""
data = os.walk("/mp4")
for path, folder_list, file_list in data:
for file_name in file_list:
file_abs_path = os.path.join(path, file_name)
ext = file_abs_path.rsplit(".",1)[-1]
if ext == "mp4":
print(file_abs_path)5.3.2. shutil
import shutil
# 1. 删除文件夹
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
# 2. 拷贝文件夹 (原来地址 , 新地址 , 以下都是)
"""
shutil.copytree("xx","xx")
"""
# 3.拷贝文件
"""
shutil.copy("xx","xxxx")
"""
# 4.文件或文件夹重命名
"""
shutil.move("xx","xxxxx")
"""
# 5. 压缩文件
"""
# base_name,压缩后的压缩包文件
# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".
# root_dir,要压缩的文件夹路径
"""
# shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 6. 解压文件
"""
# filename,要解压的压缩包文件
# extract_dir,解压的路径
# format,压缩文件格式
"""
# shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')5.3.3. sys
import sys
# 1. 获取解释器版本
"""
print(sys.version)
print(sys.version_info)
print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro)
"""
# 2. 导入模块路径
"""
print(sys.path)
"""5.3.4. random
import random
# 1. 获取范围内的随机整数
v = random.randint(10, 20)
print(v)
# 2. 获取范围内的随机小数
v = random.uniform(1, 10)
print(v)
# 3. 随机抽取一个元素
v = random.choice([11, 22, 33, 44, 55])
print(v)
# 4. 随机抽取多个元素
v = random.sample([11, 22, 33, 44, 55], 3)
print(v)
# 5. 打乱顺序
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(data)
print(data)5.3.5. hashlib
加密常用 , 可以将明文加密为人类无法识别的密文
import hashlib
hash_object = hashlib.md5()
hash_object.update("jiaoxingk".encode('utf-8'))
result = hash_object.hexdigest()
print(result)6. 模块-进阶
6.1. 更多内置模块
6.1.1. json
json模块,是python内部的一个模块,可以将python的数据格式 转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。
json格式,是一个数据格式(本质上就是个字符串,常用语网络数据传输)
# Python中的数据类型的格式
data = [
{"id": 1, "name": "jiaoxingk", "age": 18},
{"id": 2, "name": "jiaoxingk", "age": 18},
('jiaoxingk',123),
]
# JSON格式
value = '[{"id": 1, "name": "jiaoxingk", "age": 18}, {"id": 2, "name": "jiaoxingk", "age": 18},["jiaoxingk",123]]'6.1.1.1. 核心功能
json格式的作用?
跨语言数据传输,例如:
A系统用Python开发,有列表类型和字典类型等。
B系统用Java开发,有数组、map等的类型。
语言不同,基础数据类型格式都不同。
为了方便数据传输,大家约定一个格式:json格式,每种语言都是将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。Python数据类型与json格式的相互转换:
- 数据类型 -> json ,一般称为:序列化
import json
data = [
{"id": 1, "name": "jiaoxingk", "age": 18},
{"id": 2, "name": "jiaoxingk", "age": 18},
]
res = json.dumps(data)
print(res) # '[{"id": 1, "name": "\u6b66\u6c9b\u9f50", "age": 18}, {"id": 2, "name": "jiaoxingk", "age": 18}]'
res = json.dumps(data, ensure_ascii=False)
print(res) # '[{"id": 1, "name": "jiaoxingk", "age": 18}, {"id": 2, "name": "jiaoxingk", "age": 18}]'- json格式 -> 数据类型,一般称为:反序列化
import json
data_string = '[{"id": 1, "name": "jiaoxingk", "age": 18}, {"id": 2, "name": "jiaoxingk", "age": 18}]'
data_list = json.loads(data_string)
print(data_list)6.1.1.2. 其他功能
json模块中常用的是:
json.dumps,序列化生成一个字符串。json.loads,发序列化生成python数据类型。json.dump,将数据序列化并写入文件(不常用)
import json
data = [
{"id": 1, "name": "jiaoxingk", "age": 18},
{"id": 2, "name": "jiaoxingk", "age": 18},
]
file_object = open('xxx.json', mode='w', encoding='utf-8')
json.dump(data, file_object)
file_object.close()json.load,读取文件中的数据并反序列化为python的数据类型(不常用)
import json
file_object = open('xxx.json', mode='r', encoding='utf-8')
data = json.load(file_object)
print(data)
file_object.close()6.1.2. 时间处理
- UTC/GMT:世界时间
- 本地时间:本地时区的时间。
Python中关于时间处理的模块有两个,分别是time和datetime。
6.1.2.1. time
import time
# 获取当前时间戳(自1970-1-1 00:00)
v1 = time.time()
print(v1)
# 时区
v2 = time.timezone
# 停止n秒,再执行后续的代码。
time.sleep(5)6.1.2.2. datetime
在平时开发过程中的时间一般是以为如下三种格式存在:
- datetime
from datetime import datetime, timezone, timedelta
v1 = datetime.now() # 当前本地时间
print(v1)
tz = timezone(timedelta(hours=7)) # 当前东7区时间
v2 = datetime.now(tz)
print(v2)
v3 = datetime.utcnow() # 当前UTC时间
print(v3)- 字符串
# 字符串格式的时间 ---> 转换为datetime格式时间
text = "2021-11-11"
v1 = datetime.strptime(text,'%Y-%m-%d') # %Y 年,%m,月份,%d,天。
print(v1)- 时间戳
# 时间戳格式 --> 转换为datetime格式
ctime = time.time() # 11213245345.123
v1 = datetime.fromtimestamp(ctime)
print(v1)6.1.3. 正则表达式相关
当给你一大堆文本信息,让你提取其中的指定数据时,可以使用正则来实现。例如:提取文本中的邮箱和手机号
import re
text = "哈哈哈,大家好呀,这是我的手机号13370778945"
phone_list = re.findall("1[3|5|8|9]\d{9}", text)
print(phone_list)6.1.3.1. 正则表达式
6.1.3.1.1. 字符相关
jiaoxingk匹配文本中的jiaoxingk
import re
text = "你好jiaoxingk,"
data_list = re.findall("jiaoxingk", text)
print(data_list) # ['jiaoxingk'] 可用于计算字符串中某个字符出现的次数[abc]匹配a或b或c 字符。
import re
text = "jiaoxingk,abc"
data_list = re.findall("[abc]", text)
print(data_list) # ['a', 'a', 'b', 'c'][^abc]匹配除了abc意外的其他字符。
import re
text = "你wffbbupceiqiff"
data_list = re.findall("[^abc]", text)
print(data_list) # ['你', 'w', 'f', 'f', 'u', 'p', 'e', 'i', 'q', 'i', 'f', 'f'][a-z]匹配a~z的任意字符( [0-9]也可以 )。
import re
text = "jiaoxingkrootrootadmin"
data_list = re.findall("t[a-z]", text)
print(data_list) # ['tr', 'ta'].代指除换行符以外的任意字符。
import re
text = "jiaoxingkraotrootadmin"
data_list = re.findall("r.o", text)
print(data_list) # ['rao', 'roo']\w代指字母或数字或下划线(汉字)。
import re
text = "北京荒天jiaoxingk帝北 京荒天jiaoxingk帝"
data_list = re.findall("荒\w+x", text)
print(data_list) # ['荒天jiaoxingk', '荒天jiaoxingk']\d代指数字
import re
text = "root-ad32min-add3-admd1in"
data_list = re.findall("d\d", text)
print(data_list) # ['d3', 'd3', 'd1']\s代指任意的空白符,包括空格、制表符等。
import re
text = "root admin add admin"
data_list = re.findall("a\w+\s\w+", text)
print(data_list) # ['admin add']6.1.3.1.2. 数量相关
*重复0次或更多次
import re
text = "他是大B个,确实是个大2B。"
data_list = re.findall("大2*B", text)
print(data_list) # ['大B', '大2B']+重复1次或更多次
import re
text = "他是大B个,确实是个大2B,大3B,大66666B。"
data_list = re.findall("大\d+B", text)
print(data_list) # ['大2B', '大3B', '大66666B']?重复0次或1次
import re
text = "他是大B个,确实是个大2B,大3B,大66666B。"
data_list = re.findall("大\d?B", text)
print(data_list) # ['大B', '大2B', '大3B']{n}重复n次
import re
text = "楼主手机号也可15131255889"
data_list = re.findall("151312\d{5}", text)
print(data_list) # ['15131255889']{n,}重复n次或更多次
import re
text = " 2480419172@qq.com手机号也可15131255889"
data_list = re.findall("\d{9,}", text)
print(data_list) # ['2480419172', '15131255889']{n,m}重复n到m次
import re
text = "2480419172@qq.com手机号也可15131255889"
data_list = re.findall("\d{10,15}", text)
print(data_list) # ['15131255889']6.1.3.1.3. 括号(分组)
- 提取数据区域
import re
text = "楼主太牛逼了,在线想要 2480419172@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
data_list = re.findall("15131(2\d{5})", text)
print(data_list) # ['255789']- 获取指定区域 + 或条件
import re
text = "楼主15131root太牛15131jiaoxingk逼了,在线想要 2480419172@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
data_list = re.findall("15131(2\d{5}|r\w+太)", text)
print(data_list) # ['root太', '255789']6.1.3.1.4. 起始和结束
上述示例中都是去一段文本中提取数据,只要文本中存在即可。
但,如果要求用户输入的内容必须是指定的内容开头和结尾,比就需要用到如下两个字符。
^开始$结束
import re
text = "啊2480419172@qq.com我靠"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # []import re
text = "2480419172@qq.com"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # ['2480419172@qq.com']这种一般用于对用户输入数据格式的校验比较多,例如:
import re
text = input("请输入邮箱:")
email = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
if not email:
print("邮箱格式错误")
else:
print(email)6.1.3.1.5. 特殊字符
由于正则表达式中 * . \ { } ( ) 等都具有特殊的含义,所以如果想要在正则中匹配这种指定的字符,需要转义,例如:
import re
text = "我是你{5}爸爸"
data = re.findall("你{5}爸", text)
print(data) # []import re
text = "我是你{5}爸爸"
data = re.findall("你\{5\}爸", text)
print(data)6.1.3.2. re模块
python中提供了re模块,可以处理正则表达式并对文本进行处理。
- findall,获取匹配到的所有数据
import re
text = "dsf130429191912015219k13042919591219521Xkk"
data_list = re.findall("(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)", text)
print(data_list) # [('130429', '1919', '12', '01', '521', '9'), ('130429', '1959', '12', '19', '521', 'X')]- match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
import re
text = "大小逗2B最逗3B欢乐"
data = re.match("逗\dB", text)
print(data) # None- search,浏览整个字符串去匹配第一个,未匹配成功返回None
import re
text = "大小逗2B最逗3B欢乐"
data = re.search("逗\dB", text)
if data:
print(data.group()) # "逗2B"- sub,替换匹配成功的位置
import re
text = "逗2B最逗3B欢乐"
data = re.sub("\dB", "沙雕", text)
print(data) # 逗沙雕最逗沙雕欢乐- split,根据匹配成功的位置分割
import re
text = "逗2B最逗3B欢乐"
data = re.split("\dB", text)
print(data) # ['逗', '最逗', '欢乐']- finditer
import re
text = "逗2B最逗3B欢乐"
data = re.finditer("\dB", text)
for item in data:
print(item.group())6.2. 知识补充
6.2.1. nolocal关键字
我们已经学过global关键字。
name = 'root'
def outer():
name = "jiaoxingk"
def inner():
global name
name = 123
inner()
print(name)
outer()
print(name)其实,还有一个nolocal关键字,用的比较少,此处作为了解即可。
用于函数里面,把外部函数的作用域换成内部函数的作用域,从而可以从内部修改外部变量
name = 'root'
def outer():
name = "jiaoxingk"
def inner():
nonlocal name
name = 123
inner()
print(name)
outer()
print(name)结尾
以上便是今天的内容,主要是关于函数以及各种内置模块的使用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











