






用读写操作复制文件
r :只能读
w; 只能写 覆盖整个文件 不存在则创建
a 只能写 从文件底部添加内容 不存在则创建
“rb” : 以二进制读方式打开,只能读文件 , 如果文件不存 在,会发生异常
“wb”: 以二进制写方式打开,只能写文件, 如果文件不存 在,创建该文件;如果文件已存在,先清空,再打开文件
file_path = r'C:\Users\running\Desktop\GPDay14(模块与文件)\图片\open.png'
with open(file_path, 'rb') as rstream:
content = rstream.read()
# 写入
filename = file_path[file_path.rfind('\\') + 1:]
with open(filename, 'wb') as wstream:
wstream.write(content)
print('复制完成!')
1、csv的写
调用writer对象的前提是:需要传入一个文件对象,然后才能在这个文件对象的基础上调用csv的写入方法writerow(写入一行)writerrow(写入多行)。写入数据的代码如下:
import csv
headers = ['class','name','sex','height','year']
rows = [
[1,'xiaoming','male',168,23],
[1,'xiaohon
g','female',162,22],
[2,'xiaozhang','female',163,21],
[2,'xiaoli','male',158,21]
]
with open('test.csv','w')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
注意:如果打开csv文件出现空行的情况,那么需要添加一个参数 newline=”(我使用windows出现了这种情况,使用linux mint没有出现)
with open('test.csv','w',newline='')as f:
2、写入字典序列的数据
在写入字典序列类型数据的时候,需要传入两个参数,一个是文件对象——f,一个是字段名称——fieldnames,到时候要写入表头的时候,只需要调用writerheader方法,写入一行字典系列数据调用writerrow方法,并传入相应字典参数,写入多行调用writerows
具体代码如下:
import csv
headers = ['class','name','sex','height','year']
rows = [
{'class':1,'name':'xiaoming','sex':'male','height':168,'year':23},
{'class':1,'name':'xiaohong','sex':'female','height':162,'year':22},
{'class':2,'name':'xiaozhang','sex':'female','height':163,'year':21},
{'class':2,'name':'xiaoli','sex':'male','height':158,'year':21},
]
with open('test2.csv','w',newline='')as f:
f_csv = csv.DictWriter(f,headers)
f_csv.writeheader()
f_csv.writerows(rows)
3、csv文件的读
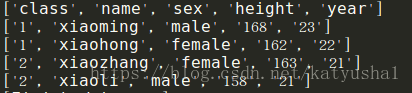
在上面,row是一个列表,如果想要查看固定的某列,则需要加上下标,例如我想要查看name,那么只需要改为row[1]
import csv
with open('test.csv')as f:
f_csv = csv.reader(f)
for row in f_csv:
print(row[1])
序列化和反序列化
什么是序列化与反序列化?
将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化;
反之,则称为反序列化。
json:返回的是字符串
import json
dict1 = {'tianfengli': [{'sno': '001', 'sname': 'xiaohua', 'age': 18, 'status': False},
{'sno': '002', 'sname': 'egou', 'age': 20, 'status': True},
{'sno': '003', 'sname': 'xiaoming', 'age': 18, 'status': False}
],
'beike': [
{'sno': '011', 'sname': 'xiaohua1', 'age': 18, 'status': False},
{'sno': '012', 'sname': 'egou1', 'age': 20, 'status': True},
{'sno': '013', 'sname': 'xiaoming1', 'age': 18, 'status': False}
]
}
result = json.dumps(dict1)
print(result)
print(type(result))
#反序列化
r = json.loads(result)
print(r)
students = r.get('tianfengli')
for student in students:
if 'xiaohua1' == student.get('sname'):
print('找到了')
break
else:
print('没有此学生!')
序列化: dumps
反序列化: loads
with open('students.txt','w') as wstream:
json.dump(dict1,wstream)
print('保存成功')
with open('students.txt','r') as rstream:
content = json.load(rstream)
print(content)
students = content.get('beike')
print(students)
pickle:返回的是字节串
dict1 = {'tianfengli': [{'sno': '001', 'sname': 'xiaohua', 'age': 18, 'status': False},
{'sno': '002', 'sname': 'egou', 'age': 20, 'status': True},
{'sno': '003', 'sname': 'xiaoming', 'age': 18, 'status': False}
],
'beike': [
{'sno': '011', 'sname': 'xiaohua1', 'age': 18, 'status': False},
{'sno': '012', 'sname': 'egou1', 'age': 20, 'status': True},
{'sno': '013', 'sname': 'xiaoming1', 'age': 18, 'status': False}
]
}
可以放一个自定义的dict1,也可以放一个对象(stu)
import pickle
result = pickle.dumps(dict1)
print(result)
r = pickle.loads(result)
print(r)
也可以放一个对象(stu)
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return self.name
stu = Student('xiaohua', 20)
stu1 = Student('ergou', 19)
bobj = pickle.dumps(stu)
print(bobj)
stu = pickle.loads(bobj)
print(stu)
关于dump和load
可以把对象写入文件里
with open('stus.txt', 'wb') as ws:
pickle.dump(stu, ws)
pickle.dump(stu1, ws)
with open('stus.txt', 'rb') as rs:
while True:
try:
content = pickle.load(rs)
print(content)
except:
print('读取完毕!')
break
json 模块提供了一种很简单的方式来编码和解码JSON数据。 其中两个主要的函数是 json.dumps() 和 json.loads() , 要比其他序列化函数库如pickle的接口少得多。 下面演示如何将一个Python数据结构转换为JSON:
import json
data = {
'name' : 'ACME',
'shares' : 100,
'price' : 542.23
}
json_str = json.dumps(data)
下面演示如何将一个JSON编码的字符串转换回一个Python数据结构:
data = json.loads(json_str)
如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据。例如:
# Writing JSON data
with open('data.json', 'w') as f:
json.dump(data, f)
# Reading data back
with open('data.json', 'r') as f:
data = json.load(f)















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









