






存储器分级
问题
- SSD、内存和L1 Cache相比速度差多少倍?
- 假设有一个二维数组,总共有 1M 个条目,如果我们要遍历这个二维数组,应该逐行遍历还是逐列遍历?
知识梳理
为什么会有存储器分级策略?
从需求上讲,我们希望存储器速度快、体积小、空间大、能耗低、散热好、断电数据不丢失。但在现实中,我们往往
无法把所有需求都实现。
但事实就是速度快的存储太贵,所以空间不会太大,而且能耗也会很高,在单一地一种硬件存储器上很难实现需求
但有了存储器分级策略就可以通过缓存预加载之类的事情可以用有限的寄存器和cache资源结合内存硬盘和使置换算法,可以让用户主观地实现cpu读写数据快,存储地空间很大,还可以做到文件断电后持久化缓存
存储器分级策略
我们根据存储器地读取速度进行分级主要分为6个级别,级别越高速度越快造假也更贵
1.寄存器;
2.L1-Cache;
3.L2-Cache;
4.L3-Cahce;
5.内存;
6.硬盘/SSD
 **寄存器(Register)**
**寄存器(Register)**
存器紧挨着PU 的控制单元和逻辑计算单元,它所使用的材料速度也是最快的。就像我们前面讲到的,存储器的
速度越快、能耗越高、产热越大,而且花费也是最贵的,因此数量不能很多
寄存器的数量通常在几十到几百之间,每个寄存器可以用来存储一定字节 (byte)的数据。比如:
32位CPU中大多数寄存器可以存储4个字节
。64位CPU中大多数寄存器可以存储8个字节
寄存机的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写。比如一条要在 4 个周期内完成的指令,除了
读写寄存器,还需要解码指令、控制指令执行和计算。如果寄存器的速度太慢,那 4 个周期就可能无法完成这条指
L1-Cache
L1- 缓存在CPU 中,相比寄存器,虽然它的位置距离 CPU 核心更远,但造价更低。通常 L1-Cache 大小在几十Kb
到几百 Kb 不等,读写速度在 2~4个CPU 时钟周期
L2-Cache
L2- 缓存也在CPU 中位置比L1- 缓存距离 CPU 核心更远。它的大小比L1-Cache 更大,具体大小要看CPU型
号,有2M的,也有更小或者更大的,速度在 10~20个CPU 周期。
L3-Cache
L3- 缓存同样在CPU 中,位置比 L2- 缓存距离 CPU 核心更远。大小通常比 L2-Cache 更大,读写速度在 20~60
个CPU周期。L3缓存大小也是看型号的,比如i9 CPU有512KB L1Cache 有2MB L2Cache; 有16MBL3
Cache。
内存
内存的主要材料是半导体硅,是插在主板上工作的。因为它的位置距离 CPU 有一段距离,所以需要用总线和 CPU
连接。因为内存有了独立的空间,所以体积更大,造价也比上面提到的存储器低得多。现在有的个人电脑上的内存
是16G,但有些服务器的内存可以到几个 T。内存速度大概在 200~300个CPU 周期之间
SSD和硬盘
SSD 也叫固态硬盘,结构和内存类似,但是它的优点在于断电后数据还在。内存、寄存器、缓存断电后数据就消失
了。内存的读写速度比 SSD 大概快 10~1000 倍。以前还有一种物理读写的磁盘,我们也叫作硬盘,它的速度比内
存慢100W倍左右。因为它的速度太慢,现在已经逐渐被 SSD替代

当CPU 需要内存中某个数据的时候,如果寄存器中有这个数据,我们可以直接使用,如果寄存器中没有这个数据
我们就要先查询L1缓存;L1 中没有,再查询 L2 缓存;L2 中没有再查询 L3 缓存;L3 中没有,再去内存中拿
而上面六种存储器组合在一起共同完成计算机地任务。寄存器存放CPU正在运行的指令和数据,是最快的存储器,L1 cache 存放即将执行的指令和即将使用的数据,以便快速访问,L2 、L3 cache存放等待执行的程序和数据,优先级排在L1缓存之后,内存中存放正在执行的程序和数据,包括当前大部分还不需要CPU立即处理的部分,硬盘持久化存储数据,保存计算机未来要用的数据和文件信息
指令预读
上面说到L1 cache放到是cpu即将执行的程序,而执行程序可以简单的理解为cpu根据指令对数据进行运算处理
举个简单的例子
指令:MOV A ,B 将数据从寄存器B移动到寄存器A。
指令所涉及的数据A,B的值
计算机执行程序的过程就是
1.读取指令 MOV A,B
2.读取数据 A,B
3.根据指令将B的数据转移到A上
因此L1存储的就有指令和数据
这里又产生了另一个问题:如果数据和指令都存储在 L1-缓存中,如果数据缓存覆盖了指令缓存,就会产生非常严
重的后果。因此,L1- 缓存通常会分成两个区域,一个是指令区,一个是数据区。
与此同时,又出现了一个问题,L1- 缓存分成了指令区和数据区,那么L2/L3 需不需要这样分呢?其实,是不需要
的。因为 L2和L3,不需要协助处理指令预读的问题。
缓存命中率
接下来,还有一个重要的问题需要解决。就是L1/L2/L3 加起来,缓存的命中率有多少?
所谓命中就是指在缓存中找到需要的数据。和命中相反的是穿透,也叫 miss,就是一次读取操作没有从缓存中找到
对应的数据。
据统计,L1 缓存的命中率在80%左右,L1/L2/L3 加起来的命中率在95%左右。因此,CPU 缓存的设计还是相当
合理的。只有 5%的内存读取会穿透到内存,95% 都能读取到缓存。这也是为什么程席语言逐渐取消了让程席员操
作寄存器的语法,因为缓存保证了很高的命中率,多余的优化意义不大,而且很容易出错。
简而言之,cpu执行程序所需要的数据95%都会预加载到L1、2、3缓存中,这样也给了人一种即使大部分数据都在存储在
内存中但通过缓存预加载,使得cpu拿数据只需往缓存中拿了,实现了cpu的读取整个程序的速度几乎和cpu读取缓存的速度接近
问题回答
- SSD、内存和L1 Cache相比速度差多少倍?
[解析] 因为内存比SSD 快10~1000 倍,L1 Cache 比内存快 100 倍左右。因此 L1 Cache 比SSD 快了
1000~100000 倍。所以你有没有发现 SSD 的潜力很,好的 SSD 已经接近内存了,只不过造价还略高.
- 假设有一个二维数组,总共有 1M 个条目,如果我们要遍历这个二维数组,应该逐行遍历还是逐列遍历?
逐行遍历
我相信在我们平时写程序时for循环的最完成也是先遍历行再遍历列
因为二维数组再内存中是连续的逐列遍历时地址时跳跃的
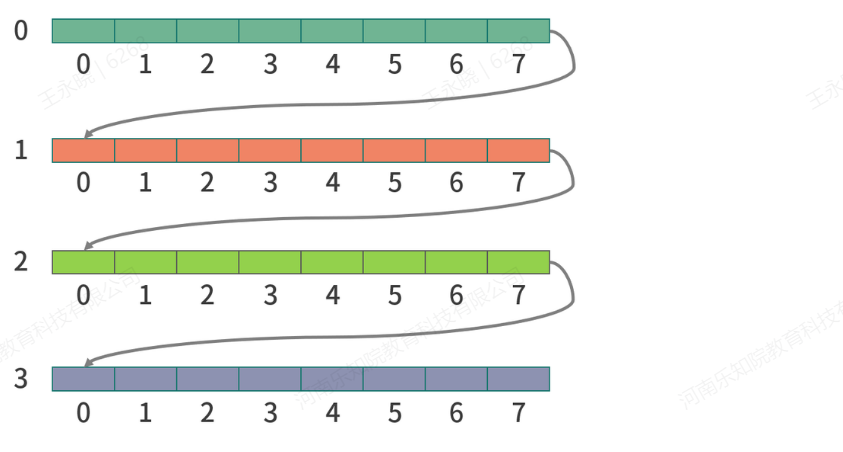
比如说 第一行第一个元素的值时00
那么第一行和第二行的地址就是(一个元素占4个字节)
00 04 08 12 16 20 24
28 32 36 40 44 48 52
那么逐行遍历只需要将指针下一一个长度单位(4)
[外链图片转存中…(img-94BovS2A-1721976567910)]
比如说 第一行第一个元素的值时00
那么第一行和第二行的地址就是(一个元素占4个字节)
00 04 08 12 16 20 24
28 32 36 40 44 48 52
那么逐行遍历只需要将指针下一一个长度单位(4)
但逐列的话就需要跳跃一行的长度单位(24)并且如果读到最后一行再回去读第一行的下一列也非常麻烦


















 6741
6741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









