







文章目录
一、Datax官网
二、Datax的介绍
1、Datax概述
- DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

- 设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
2、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
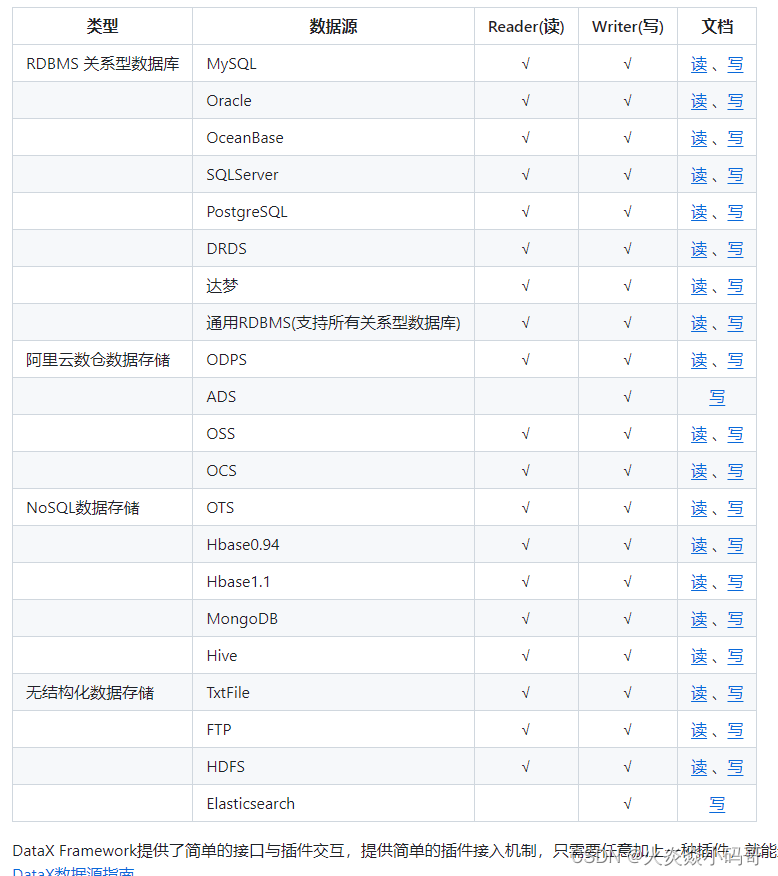
3、DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
4、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
5、DataX 3.0六大核心优势
-
可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量�运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
-
-
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。 -
精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。```bash "speed": { "channel": 5, "byte": 1048576, "record": 10000 } ``` -
强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南 -
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
-
-
极简的使用体验
-
易用
下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。
-
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。-
传输过程中打印传输速度、进度等

-
传输过程中会打印进程相关的CPU、JVM等

-
在任务结束之后,打印总体运行情况

-
-
三、Datax安装
1、安装教程
1.1 下载Datax tar包
- 下载到自己指定的安装目录
#wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
- 进行解压
tar -zxvf datax.tar.gz
系统环境要求
-
JDK(1.8以上,推荐1.8)
- 查看系统是否安装jdk
java -version #如下表明安装成功: openjdk version "1.8.0_382" OpenJDK Runtime Environment (build 1.8.0_382-b05) OpenJDK 64-Bit Server VM (build 25.382-b05, mixed mode) # 如果没有,执行下面命令 yum install java-1.8.0-openjdk.x86_64
- 查看系统是否安装jdk
-
Python(2或3都可以)
- 产看系统Python是否已安装
# 查看命令 python --version #如果已安装,则提示 Python 版本号 # 如果没有可以用如下命令安装 yum install -y python38
- 产看系统Python是否已安装
Datax验证
#进入datax目录
cd datax
#执行下面命令
bin/datax.py job/job.json
#如果提示
-bash: ../bin/datax.py: Permission denied
#修改datax.py的权限,修改权限后再执行验证命令
chmod 777 datax.py
有如下信息提示,则说明datax可以正常运行

1.2 运行相关job
streamreader,streamwriter方式
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 3 #并发数量,在这里是3个并发
}
}
}
}
Mysql的数据传输
-
Mysql历史数据同步
-
第一种方式,源字段和目标字段要一一对应,顺序一致
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "用户名",
"password": "密码",
"column": [
"`ENDCHECKTIME`",
"`ENDCHECKUSER`",
"`SUMBMITTIME`",
"`REPORTTIME`",
"`NETVISATIME`",
"`STOCKRIGHTTIME`",
"`ACCOUNTNUM`",
"`MULTIPLECARDS`",
"`ACCOUNTNUMSTATE`",
"`ACCOUNTNUMCHANGE`",
"`CONSUMACCOUNTCHANGE`",
"`assetresult`",
"`CREATETIME`",
"`UPDATETIME`"
],
"where": "id>= ${startId} and id< ${endId}\n", #where条件,根据自己的实际情况来
"splitPk": "",#任务分割标识,主键id,只有第一种方式添加分割标识,任务才会分割,分割为多个小任务,第二种方式不会分割
"connection": [
{
"table": [
"源表"
],
"jdbcUrl": [
"jdbc:mysql://源目标数据库链接"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"writeMode": "insert", #这里有三种模式,详见下方描述
"parameter": {
"username": "数据用户名",
"password": "数据库密码",
"column": [
"`endcheck_time`",
"`endcheck_user_id`",
"`submit_time`",
"`report_time`",
"`netvisa_time`",
"`stockright_time`",
"`account_num`",
"`account_type`",
"`ocr_bank_card`",
"`multiplecards`",
"`account_state`",
"`account_num_change`",
"`consum_account_change`",
"`assert_result`",
"`create_time`",
"`update_time`"
],
"connection": [
{
"table": [
"target_table" #目标表
],
"jdbcUrl": "jdbc:mysql://数据库链接"
}
]
}
}
}
]
}
}
- 第二种方式,源字段和目标字段要一一对应,顺序一致
写sql的方式
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "用户名",
"password": "密码",
"splitPk": "",
"connection": [
{
"querySql": [
"select ORDERID,STATIONNO,STATIONDETAITYPE,IDNUMER from 源表 where orderid>= ${startId} and orderid< ${endId}"
],
"jdbcUrl": [
"jdbc:mysql://数据库链接"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "用户名",
"password": "密码",
"column": [
"`order_id`",
"`station_no`",
"`station_type`",
"`id_number`"
],
"connection": [
{
"table": [
"target_table"
],
"jdbcUrl": "jdbc:mysql://数据库链接"
}
]
}
}
}
]
}
}
-
writeMode
-
描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
-
必选:是
-
所有选项:insert/replace/update
-
默认值:insert
-
四、下集预告
针对这种我们需要到服务器上或者本地编写json脚本,然后再执行,也不支持增量同步,后续我会介绍一款可视化界面工具,可以界面操作,并且可以支持增量同步,Datax配合可视化界面,真的是数据同步的利器,关注博主不迷路















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









