







算法解决问题:
1,从json文件中抽取数据集中的小目标pne、p11、i5、w57四种交通标志数据集
2.小目标判断标注像素范围在[32,32]
3.转为对应的xml文件
4.标出选出的类别的个数
import os
import time
import json
import cv2
xml_head = '''<annotation>
<folder>traffic-sign</folder>
<!--文件名-->
<filename>{}</filename>
<size>
<width>2048</width>
<height>2048</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<category>{}</category>
'''
xml_obj = '''
<object>
<!--图片中目标类别-->
<name>{}</name>
<!--是否被裁减,0表示完整,1表示不完整-->
<truncated>0</truncated>
<!--是否容易识别,0表示容易,1表示困难-->
<difficult>0</difficult>
<bndbox>
<xmin>{}</xmin>
<ymin>{}</ymin>
<xmax>{}</xmax>
<ymax>{}</ymax>
</bndbox>
</object>
'''
xml_end = '''
</annotation>'''
# json文件路径和用于存放xml文件的路径
anno = '/home/xiaobumidm/Yolo_mark-master/annotations.json'
xml_dir = '/home/xiaobumidm/Yolo_mark-master/jsonxml/'
labels = ['pne','p11','i5','w57'] # label for datasets
print("labels类型:",type(labels))
# 读取json文件内容,返回字典格式
with open(anno,'r',encoding='utf8')as fp:
json_data = json.load(fp)
#imgs数据,字典类型
json_imgs=json_data['imgs']
#记录小目标总数目,共2908
count=0
#count_pne的小目标数目
count_pne=0
#count_p11的小目标数目
count_p11=0
#count_i5的小目标数目
count_i5=0
#count_w57的小目标数目
count_w57=0
#count_pne_trian训练文件夹中pne数量
count_pne_trian=0
# count_p11_trian训练文件夹中p11数量
count_p11_trian = 0
# count_i5_trian训练文件夹中i5数量
count_i5_trian = 0
# count_w57_trian训练文件夹中w57数量
count_w57_trian = 0
#训练pne数量
count_img_pne_train=0
#训练p11数量
count_img_p11_train=0
#训练i5数量
count_img_i5_train=0
#训练w57数量
count_img_w57_train=0
# 测试pne数量
count_img_pne_test=0
# 测试p11数量
count_img_p11_test=0
# 测试i5数量
count_img_i5_test=0
# 测试w57数量
count_img_w57_test=0
#图片总数
count_image=0;
table=['pne']
for item in json_imgs.items():
#item是tuple类型 ,item元组中共有两个元素,一开始的ID和图片详细信息
#detail_info为图片详细信息,是字典类型,含有path,objects,id三个key值
detail_info=item[1]
#path图片路径
image_path=detail_info['path']
if image_path.find('train')!=-1 or image_path.find('test')!=-1:
#图片含有的目标,list类型
image_objects=detail_info['objects']
# 图片的id
image_id = detail_info['id']
# flag_category记录category的标记
flag_category = ''
#obj表示一个图片中目标信息
obj=''
for info in range(len(image_objects)):
# object_info是object的详细信息,数据类型为字典,包含category,objects
object_info = image_objects[info]
#object_category是object的category,字符串
object_category = object_info['category']
# object_bbox为字典类型,存放目标信息xmin,ymin,xmax,ymax
object_bbox = object_info['bbox']
#x_rang目标的x间的大小,xmax-xmin
x_rang=object_bbox['xmax']-object_bbox['xmin']
#目标的y间的大小,ymax-ymin
y_rang=object_bbox['ymax']-object_bbox['ymin']
#flag=0
if x_rang <= 32 and y_rang <= 32:
if object_category == 'pne':
if flag_category == '':
flag_category = object_category
obj+=xml_obj.format(labels[0],str(object_bbox['xmin']),str(object_bbox['ymin']),
str(object_bbox['xmax']),str(object_bbox['ymax']))
if image_path.find('train') != -1:
count_pne_trian+=1
count_pne += 1
count += 1
if object_category == 'p11':
if flag_category == '':
flag_category = object_category
obj += xml_obj.format(labels[1], str(object_bbox['xmin']),
str(object_bbox['ymin']),
str(object_bbox['xmax']), str(object_bbox['ymax']))
if image_path.find('train') != -1:
count_p11_trian+=1
count_p11 += 1
count += 1
if object_category == 'i5':
if flag_category == '':
flag_category = object_category
obj += xml_obj.format(labels[2], str(object_bbox['xmin']),
str(object_bbox['ymin']),
str(object_bbox['xmax']), str(object_bbox['ymax']))
if image_path.find('train') != -1:
count_i5_trian+=1
count_i5 += 1
count += 1
if object_category == 'w57':
if flag_category == '':
flag_category = object_category
obj += xml_obj.format(labels[3], str(object_bbox['xmin']),
str(object_bbox['ymin']),
str(object_bbox['xmax']), str(object_bbox['ymax']))
if image_path.find('train') != -1:
count_w57_trian+=1
count_w57 += 1
count += 1
print('x_rang:', x_rang)
print('y_range:', y_rang)
#表示有合适类别的小目标的时候开始创建xml文件,存放在了test和train文件夹下面
if flag_category!='' :
if image_path.find('train') != -1:
if flag_category=='pne':
count_img_pne_train+=1
xml_name = os.path.join(xml_dir + 'trains/pne/', str(image_id) + '.xml')
if flag_category=='p11':
count_img_p11_train+=1
xml_name = os.path.join(xml_dir + 'trains/p11/', str(image_id) + '.xml')
if flag_category=='i5':
count_img_i5_train+=1
xml_name = os.path.join(xml_dir + 'trains/i5/', str(image_id) + '.xml')
if flag_category=='w57':
count_img_w57_train+=1
xml_name = os.path.join(xml_dir + 'trains/w57/', str(image_id) + '.xml')
else :
if flag_category=='pne':
count_img_pne_test+=1
xml_name = os.path.join(xml_dir + 'tests/pne/', str(image_id) + '.xml')
if flag_category=='p11':
count_img_p11_test+=1
xml_name = os.path.join(xml_dir + 'tests/p11/', str(image_id) + '.xml')
if flag_category=='i5':
count_img_i5_test+=1
xml_name = os.path.join(xml_dir + 'tests/i5/', str(image_id) + '.xml')
if flag_category=='w57':
count_img_w57_test+=1
xml_name = os.path.join(xml_dir + 'tests/w57/', str(image_id) + '.xml')
count_image+=1
print("xml_name:"+xml_name)
print("image_id:",image_id)
#xml的头部信息传入参数值,文件名字和类别
head=xml_head.format(str(xml_name),str(flag_category))
#xml的尾部信息
end=xml_end
#向xml文件中写入内容
with open(xml_name, 'w') as f:
f.write(head+obj+end)
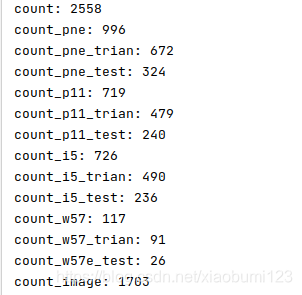
print('count:', count)
print('count_pne:', count_pne)
print('count_pne_trian:',count_pne_trian)
print('count_pne_test:',count_pne - count_pne_trian)
print('count_p11:', count_p11)
print('count_p11_trian:', count_p11_trian)
print('count_p11_test:', count_p11 - count_p11_trian)
print('count_i5:', count_i5)
print('count_i5_trian:', count_i5_trian)
print('count_i5_test:', count_i5 - count_i5_trian)
print('count_w57:', count_w57)
print('count_w57_trian:', count_w57_trian)
print('count_w57e_test:', count_w57 - count_w57_trian)
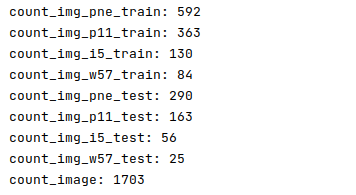
print('count_img_pne_train:',count_img_pne_train)
print('count_img_p11_train:',count_img_p11_train)
print('count_img_i5_train:',count_img_i5_train)
print('count_img_w57_train:',count_img_w57_train)
print('count_img_pne_test:',count_img_pne_test)
print('count_img_p11_test:',count_img_p11_test)
print('count_img_i5_test:',count_img_i5_test)
print('count_img_w57_test:',count_img_w57_test)
print('count_image:', count_image)
count值:

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









