






Dynamic Ride-Hailing Route Planning Based on Deep Reinforcement Learning
本文的主要贡献
- 提出了一个基于实时供需状态的动态网约车路径规 划 框 架,实 现 高 效 的 大 规 模 空 闲 网 约 车调度,通过包含实时的供需信息来适应动态变化的环境.
- 设计了一种带有动作采样的 ASGAC算法来选择可行的动作,增加了动作选择的随机性,从而有效地防止竞争
网约车路径规划问题
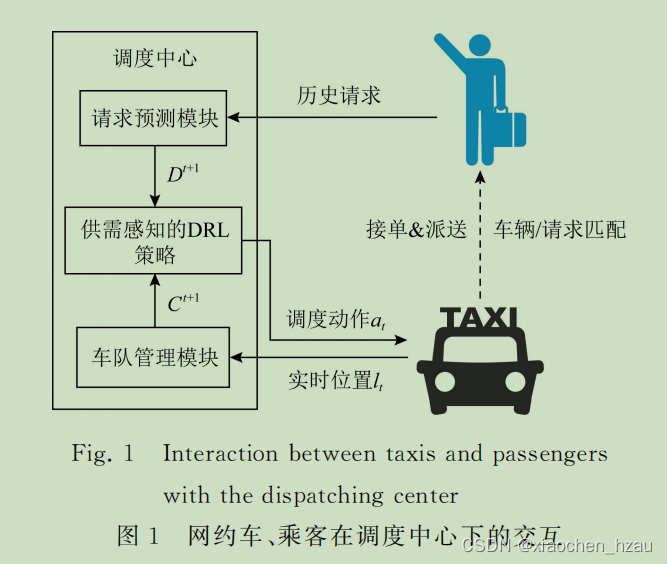
网约车、乘客在调度中心下的交互框架
车队管理模块:跟踪网约车的实时位置,以获取下一个时间片网约车供应量
请求预测模块:根据历史的请求时空分布,预测未来的网约车需求分布
深度强化学习调度策略:将供需结合起来,以确定空闲网约车的调度动作,然
后网约车将会朝着调度终点巡航
当网约车被分配给一个请求后,它会首先沿着最短路径前往请求的起点去接乘客,然后驶向请求的终点以完成服务.如果一个请求在其最长等待时间内都没
有被分配给网约车,则该请求将被拒绝.
Markov决策过程
状态:元组中的元素分别表示网格下标、当前时间片的索引、全局的空闲车辆与等待中的请求数量之差,以及该网格的网约车供应量和乘客需求
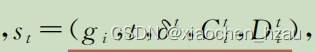
动作:是指将空闲网约车派往某个特定的目的网格gj
奖励:
回合.在该问题设定中,一个回合是从8∶00到22∶00的繁忙时段.因此,时间t在22∶00之后的状态为终止状态


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









