








版权声明:未经允许,随意转载,请附上本文链接谢谢(づ ̄3 ̄)づ╭❤~
http://blog.csdn.net/xiaoduan_/article/details/79328487
KNN
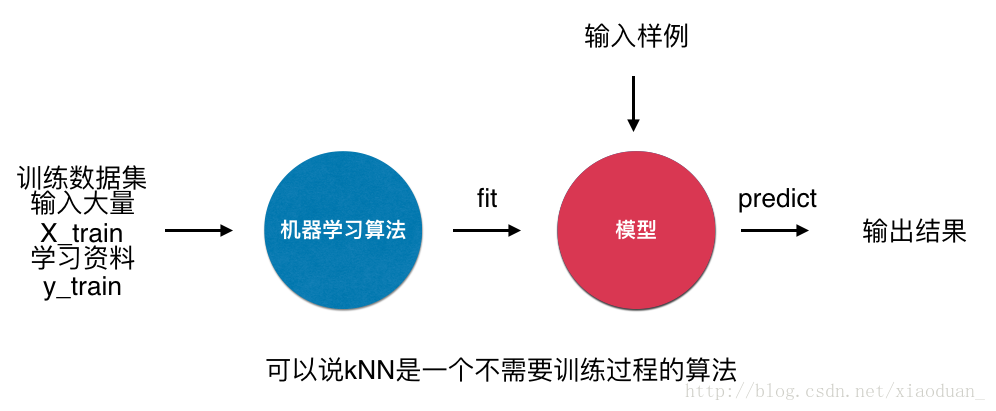
- k近邻算法是非常特殊的,可以被认为是没有模型的算法
- 为了和其他算法统一,可以认为训练数据集就是模型本身
Sklearn中KNN的简单调用
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train, y_train)
y_predict = kNN_classifier.predict(X_predict)超参数
- 超参数
- 在算法运行前需要决定的参数
- 模型参数
- 算法运行过程中学习的参数
- KNN中没有模型参数
- KNN中的K是典型的超参数
- KNN中的另一个超参数weights
-
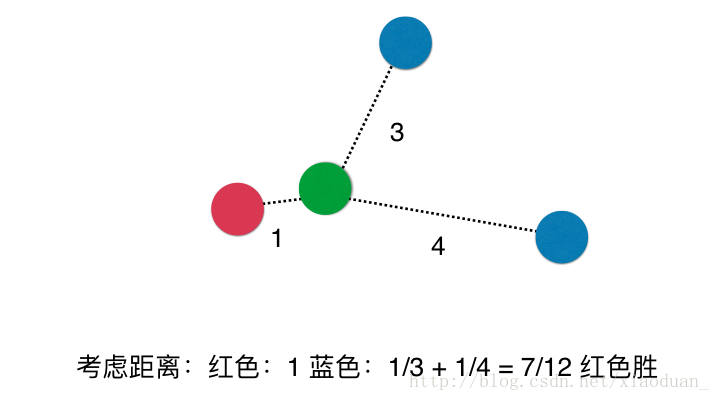
1.考虑距离
-
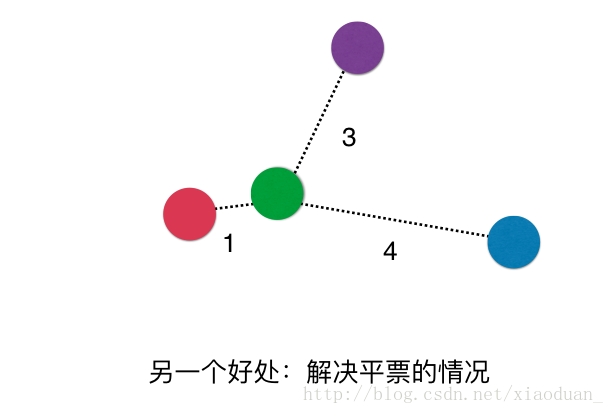
2.解决平票问题
-
参数的选择
uniform:不考虑距离
distance:使用距离
p: 距离的定义
自己封装一个简易版KNN
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
KNN的特点
- 解决分类问题
- 天然解决多分类问题
- 思想简单,效果强大
- 还可以用来解决回归问题

缺点
- 效率低下
- 高度数据相关
- 预测结果具有不可解释性
- 维度灾难

















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









