






| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
若要对页面中的提示警告窗口中的滚动条进行操作,要先定位到该内嵌窗口,在进行滚动条操作
设置浏览器大小:像素点
set_window_size(width,height)
maximize_window() 浏览器全屏显示,不带参数
控制浏览器前进、后退:
driver.forward()
driver.back()
模拟浏览器刷新:
driver.refresh()
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
#参数是像素点宽,高
driver.set_window_size(800,800)
print("浏览器大小是800px,800px")
driver.find_element_by_link_text("新闻").click()
driver.back() #返回前一个页面
driver.forward() #前进前一个页面
driver.refresh() #刷新当前页面
driver.find_element_by_css_selector("#ww").send_keys("python3")
driver.find_element_by_xpath("//*[@class='btn']").click()
driver.refresh() #刷新当前页面
driver.quit()
clear()清除文本
send_keys("....") 模拟按键输入
click() 单击元素,前提是它是可以被单击的对象。
另外click()方法不仅可以用于单击一个按钮,它还能可以单击任何可以单击的文字、图片、checkbox、radio、select下拉框等。
submit() 用于提交表单,同样可以用于提交一个按钮。
WebElement接口常用方法
先看例子:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
size = driver.find_element_by_name("wd").size
print(size) #size属性,返回元素的尺寸,表单输入框之类的width、height等
text = driver.find_element_by_id("jgwab").text
print(text) #text属性,获取元素的文本,可以用力判断打开的页面是否是预期的。
attribute = driver.find_element_by_xpath(".//input[@id='kw']").get_attribute('maxlength')
print(attribute) #get_attribute()方法可以获取属性值
result = driver.find_element_by_partial_link_text("京公网安备").is_displayed()
print(result) #is_displayed() 元素是否设置可见,可见返回true则false
driver.quit()

size属性返回元素尺寸
text属性返回元素文本
get_attribute()方法获取属性值
is_displayed()方法返回该元素是否设置可见
鼠标事件
对鼠标的操作:右击、双击、悬停、鼠标拖动等功能,
webdriver中对鼠标的操作的方法封装在ActionChains类中 ,使用前要先导入ActionChains类:
from selenium.webdriver.common.action_chains import ActionChains
ActionChains类提供的鼠标操作常用方法:
context_click() 右击
double_click() 双击
drag_and_drop() 拖动
move_to_element() 鼠标悬停
perform() 执行所有ActionChains类中存储的行为,可以理解为对整个操作的提交动作
鼠标右键操作
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains #导入ActionChains类
driver = webdriver.Firefox()
driver.get(r"https://yunpan.360.cn/")
driver.maximize_window ()
driver.find_element_by_xpath("//*[@name='account']").clear()
driver.find_element_by_xpath("//*[@name='account']").send_keys("username.com")
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys("pwd")
driver.find_element_by_xpath("//*[@id='login']/div/div[2]/form/p[4]/label/input").click()
driver.find_element_by_xpath("//*[@id='login']/div/div[2]/form/p[5]/input").click()
#定位到需要右击的元素
right_click = driver.find_element_by_link_text("jemeter")
#对定位到的元素执行鼠标邮件操作,调用ActionChains类,将浏览器驱动driver作为参数传入,context_click()需要指定元素位置
ActionChains(driver).context_click(right_click).perform()
鼠标双击操作
double_click()方法模拟鼠标双击操作
(单击查看详情,双击弹出修改页面就用这个方法模拟)
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
....
#定位需要双击的元素
double_click = driver.find_element_by_xpath("")
#对定位到的元素进行双击操作
ActionChains(driver).double_click(double_click).perform()
a = driver.find_element_by_class_name("")
ActionChains(driver).double_click(a).perform()
鼠标悬停
move_to_element()方法模拟鼠标悬停
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
driver.set_window_size(1000,1000)
#定位到悬停的元素
attrible = driver.find_element_by_link_text("设置")
#对定位到的元素进行悬停操作
ActionChains(driver).move_to_element(attrible).perform()
time.sleep(5)
driver.refresh()
以上3种鼠标操作用法相同!
其实在WebDriver中,提供了许多鼠标操作的方法,这些操作方法都封装在ActionChains类中,
包括鼠标右击、双击、悬停和鼠标拖动等功能。
ActionChains类提供的鼠标操作事件
context_click():点击鼠标右键
double_click():双击鼠标
drag_and_drop():拖动鼠标
move_to_element():鼠标悬停
鼠标悬停
页面上有些下拉菜单,在鼠标放到元素上以后,下面的菜单才会显示出来。下面的图片就是一个例子

百度首页上的设置项,下面的菜单默认不会显示,将鼠标停在上面后才会显示,这就是鼠标的悬停操作,菜单显示以后就可以对下面的项进行点击操作
进入搜索设置的代码
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
time.sleep(3)
settings = driver.find_element_by_link_text('设置')
webdriver.ActionChains(driver).move_to_element(settings).perform()
time.sleep(1)
settings_search = driver.find_element_by_class_name('setpref')
settings_search.click()
time.sleep(3)
driver.close()
打开页面后,根据链接的文本信息找到设置项,使用ActionChains的move_to_element()方法将鼠标悬停在设置上,然后找到搜索设置项
鼠标的右击、双击和拖动事件都是通过上述的方法调用,只要将方法替换一下就可以了。
拖动事件需要传入两个参数,第一个参数是拖动的起点元素,第二个参数是终点元素
webdriver.ActionChains(driver).context_click("右击的元素定位").perform() #右击事件
webdriver.ActionChains(driver).double_click("双击的元素定位").perform() #双击事件
webdriver.ActionChains(driver).drag_and_drop("拖动的起点元素", "拖动的终点元素").perform() #拖动事件
键盘事件
Keys类中提供了几乎所有的键盘事件,在鼠标事件中用到了两个键盘事件,
键盘的向下按键(send_keys(Keys.DOWN))和键盘的回车事件(send_keys(Keys.ENTER))。
键盘的事件需要导入Keys模块
from selenium.webdriver.common.keys import Keys
所有的键盘事件都包含在这个模块中,send_keys用来模拟键盘输入,除此之外,还可以用例模拟键盘上的按键,不仅支持单个的键盘按键,还支持组合按键输入
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
time.sleep(3)
driver.find_element_by_id('kw').send_keys('selenium') #在搜索框中输入"selenium"
driver.find_element_by_id('kw').send_keys(Keys.SPACE) #输入空格键
driver.find_element_by_id('kw').send_keys('python') #在搜索框中输入"python"
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'a') #输入Control+a模拟全选
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'c') #输入Control+c模拟复制
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'v') #输入Control+v模拟粘贴
driver.find_element_by_id('kw').send_keys(Keys.ENTER) #输入回车代替点击搜索按钮
time.sleep(3)
driver.close()
下面是一些常用的键盘事件:
– Keys.BACK_SPACE:回退键(BackSpace)
– Keys.TAB:制表键(Tab)
– Keys.ENTER:回车键(Enter)
– Keys.SHIFT:大小写转换键(Shift)
– Keys.CONTROL:Control键(Ctrl)
– Keys.ALT:ALT键(Alt)
– Keys.ESCAPE:返回键(Esc)
– Keys.SPACE:空格键(Space)
– Keys.PAGE_UP:翻页键上(Page Up)
– Keys.PAGE_DOWN:翻页键下(Page Down)
– Keys.END:行尾键(End)
– Keys.HOME:行首键(Home)
– Keys.LEFT:方向键左(Left)
– Keys.UP:方向键上(Up)
– Keys.RIGHT:方向键右(Right)
– Keys.DOWN:方向键下(Down)
– Keys.INSERT:插入键(Insert)
– DELETE:删除键(Delete)
– NUMPAD0 ~ NUMPAD9:数字键1-9
– F1 ~ F12:F1 - F12键
– (Keys.CONTROL, ‘a’):组合键Control+a,全选
– (Keys.CONTROL, ‘c’):组合键Control+c,复制
– (Keys.CONTROL, ‘x’):组合键Control+x,剪切
– (Keys.CONTROL, ‘v’):组合键Control+v,粘贴
鼠标拖放操作
drag_and_drop(source,target) 在源元素上按住鼠标左键,然后移动到目标元素上释放。
source 鼠标拖动的源元素
target鼠标释放的目标元素
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.get("http://www.baidu.com/")
#定位元素的初始位置
source = driver.find_element_by_css_selector("")
#定位元素的要移动到的位置
target = driver.find_element_by_name("")
#执行元素的拖放操作
ActionChains(driver).drag_and_drop(source,target).perform()
键盘事件
Keys()类提供了键盘上按键的方法,send_keys()方法可以用来模拟键盘输入,还可以用来输入键盘上的按键、组合键。
在使用键盘按键方法前需要先导入keys类:
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
driver.maximize_window()
driver.find_element_by_name("wd").send_keys("pythonm")
#删除多输入的m
time.sleep(2) #删除键
driver.find_element_by_name('wd').send_keys(Keys.BACK_SPACE)
#输入空格键在输入“selenium” #空格键
driver.find_element_by_name("wd").send_keys(Keys.SPACE)
time.sleep(2)
driver.find_element_by_name("wd").send_keys("selenium")
time.sleep(2)
#ctrl+a全选输入框内容 #Ctrl+a全选
driver.find_element_by_name("wd").send_keys(Keys.CONTROL,'a')
time.sleep(2)
#Ctrl+x剪切选中的内容 #Ctrl+x剪切
driver.find_element_by_name("wd").send_keys(Keys.CONTROL,'x')
time.sleep(2)
#Ctrl+v粘贴选中的内容 #Ctrl+v粘贴
driver.find_element_by_name('wd').send_keys(Keys.CONTROL,'v')
#通过输入enter键替代clic()单击 #enter回车键
driver.find_element_by_name('wd').send_keys(Keys.ENTER)
driver.quit()
获取验证信息
在自动化用例执行之后,我们可以在页面上获取一些信息来证明,用例执行成功还是失败。
通常用到的验证信息分别是:text、title、URL
text:获取标签对之间的文本信息;
title:获取当前页面的标题;
current_url:获取当前页面的URL
它们是webdriver的属性!!!
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get(r"http://yunpan.360.cn")
print("登录之前:")
#打印当前页面的title
title = driver.title
print(title)
#打印当前页面的URL
now_url = driver.current_url
print(now_url)
#获取“欢迎使用360云盘!”的文本
text = driver.find_element_by_tag_name("h1").text
print(text)
#登录邮箱 分别对应输入账户和密码
driver.find_element_by_name("account").clear() #name定位
driver.find_element_by_name("account").send_keys("xxxqq.com")
driver.find_element_by_xpath("//*[@name='password']").clear() #xpath元素属性定位
driver.find_element_by_xpath("//*[@name='password']").send_keys("yxxx36")
#xpath元素属性和层级结合定位
driver.find_element_by_xpath("//div[@id='login']/div/div[2]/form/p[4]/label/input").click()
driver.find_element_by_xpath("//*[@id='login']/div/div[2]/form/p[5]/input").click()
sleep(5)
print("登录邮箱之后:")
#再次打印title
title = driver.title
print(title)
#打印当前的URL
now_url = driver.current_url
print(now_url)
#获取登录后的文本
text = driver.find_element_by_xpath(".//*[@id='crumb']/div/span").text
print(text)

可以把登录之后的信息存放起来,作为验证登录是否成功。加断言就可可以。
设置元素等待
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待和显性等待可以同时用,但要注意:等待的最长时间取两者之中的大者
driver.get('https://huilansame.github.io')
locator = (By.LINK_TEXT, 'CSDN')
try:
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located(locator))
print driver.find_element_by_link_text('CSDN').get_attribute('href')
finally:
driver.close()
web应用程序采用AJAX技术时,页面上的元素不会同时被加载完成,防止定位元素会出现ElementNotVisibleException的错误,可以通过设置元素等待防止这种问题出现。
显式等待
显式等待使WebDriver等待某个条件成立时继续执行,否则在达到最大时长抛出超时异常(TimeException)。
显式等待用到WebDriverWait()类和expected_conditions()类中的方法,使用前需要先导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
显式等待相当于:在定位某个元素之前检查该元素是否被加载出来了,until到当前元素被加载到DOM树中.
(例一)
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get('https://huilansame.github.io')
sleep(3) # 强制等待3秒再执行下一步
print driver.current_url
driver.quit()
(例二)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com//")
#显式等待
#定位第一个元素
element = WebDriverWait(driver,5,0.5,ignored_exceptions=None).until(
EC.presence_of_element_located((By.ID,"kw"))
)
element.send_keys("ptyh")
#定位第二个元素
element = WebDriverWait(driver,5,0.5,ignored_exceptions=None).until(
EC.presence_of_element_located((By.ID,"su"))
)
element.click()
driver.quit()
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver:浏览器驱动
timeout:最长超时时间,默认单位是秒
poll_frequency:检测的间隔时间,默认是0.5秒
ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException异常。
WebDriverWait()一般由until()或until_not()方法一起使用:
until(method,message = 'xxx')
until_not(method,message = ‘XXX’)
例子中until()的method是EC.presence_of_element_located((By.Id,"kw"))
使用匿名函数:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Chrome()
driver.get(r'http://www.baidu.com')
driver.maximize_window()
WebDriverWait(driver,5,0.5,ignored_exceptions=None).until(lambda driver : driver.find_element_by_xpath("//*[@id='kw']")).send_keys('lambda')
WebDriverWait(driver,5).until(lambda driver : driver.find_element_by_id('su')).click()
driver.quit()
lambda是一个匿名函数,冒号前是入参,冒号后面是return的返回值,相当于:
def test(driver):
return driver.find_element_by_id('su').click()
除了预期类提供的判断外还可以用is_displayed()方法判断元素是否可见:
#利用is_displayed()方法判断元素是否可见
'''''
for循环10次每次循环判断元素的is_diaplayed()状态
是否是true,若为true,则break跳出循环;否则sleep(1)
后继续循环判断,知道10次循环结束后,打印“time_out”信息。
'''
from selenium import webdriver
from time import sleep,ctime
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
print(ctime())
for i in range(10):
try:
element = driver.find_element_by_id("kw33")
if element.is_displayed():
break
except:pass
sleep(1)
else:
print("time_out!")
driver.close()
print(ctime())
隐式等待
# -*- coding: utf-8 -*-
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(30) # 隐性等待,最长等30秒
driver.get('https://huilansame.github.io')
print driver.current_url
driver.quit()
隐性等待对整个driver的周期都起作用,所以只要设置一次即可
隐式等待是通过一定的时长等待页面上某元素加载完成。如果超出了设置的时长元素还没有加载,会抛出NoSuchElementException异常。
webdriver的implicitly_wait()方法来实现隐式等待,默认设置为0。
这个等待函数是针对整个driver的,只需要设置一个函数就行。
也就是说,使用driver去获取一个元素或对象,当找不到这个元素时,它就会自动根据设置的时间去等待,超过设置的时长才会抛出错误。
隐式等待使用到抛出异常,NoSuchElementException异常需要先导入:
from selenium .common.exceptions import NoSuchElementException
implicitly_wait()方法由webdriver提供。
from selenium import webdriver
#from selenium.common.exceptions import NoSuchElementException
from time import ctime
driver = webdriver.Firefox()
#设置隐式等待是10s
driver.implicitly_wait(10)
driver.get("http://www.baidu.com/")
try:
print(ctime())
driver.find_element_by_id("kw22").send_keys("python")
except NoSuchElementException as e:
print(e)
finally:
print(ctime())
driver.quit()
implicitly_wait()默认参数单位是秒,这里的5秒并不是一个固定的等待时间,它不影响脚本的执行速度。
implicitly_wait()并不针对页面上的某一元素进行等待,当脚本执行到某个元素定位时,若元素可以定位,则继续执行;若元素定位不到,则它将以轮询的方式不断判断元素是否被定位到,直到超出设置时长还没有定位到元素,则抛出异常。
sleep休眠方法
希望脚本执行到某个位置做固定休眠,可以使用sleep()方法。sleep()方法由python的time提供:
from time import sleep
实例:(结合隐式等待、键盘事件)
隐式等待利用语句:try...except...else...finally...
先对定位元素进行判断,若在设置的时间内定位元素失败就执行except语句抛出NoSuchElementException,定位到元素执行else语句代码继续执行。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep,ctime
from selenium.common.exceptions import NoSuchElementException
driver = webdriver.Firefox()
print(ctime())
#设置隐式等待
driver.implicitly_wait(10)
#先执行try定位元素位置
try:
driver.get(r"http://www.baidu.com/")
driver.maximize_window () #全屏显示
sleep(2)
el = driver.find_element_by_name("wd")
sleep(3) #休眠3秒
#找不到元素位置就执行except
except NoSuchElementException as e:
print(e)
#找到元素位置执行else语句
else:
el.send_keys("pythonm")
#删除多输入的m
driver.find_element_by_name("wd").send_keys(Keys.BACK_SPACE)
sleep(3)
#输入空格+“自动化测试”
driver.find_element_by_name("wd").send_keys(Keys.SPACE)
sleep(3)
driver.find_element_by_name("wd").send_keys("自动化测试")
sleep(3)
#输入enter键百度一下
driver.find_element_by_id("su").send_keys("Keys.ENTER")
sleep(3)
#定不定位到元素都会执行finally语句
finally:
print(ctime())
driver.quit()
定位一组元素
webdriver提供了定位一组元素的方法:
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_xpath()
find_elements_by_css_selector()
find_elements_by_link_text()
find_elements_by_partial_link_text()
原来定位一组元素和定位一个元素基本一样,唯一不同的是elements复数。
定位一组元素用于:
批量操作元素,如勾选复选框checkbox、单选框radio。
先获取一组元素,再从这组元素对象中过滤出需要操作的元素,如定位页面所有的复选框,然后选择其中一个进行其他操作。
如操作下面一段代码:checkbox.html
<!DOCTYPE HTML>
<html lang="ch-zh">
<head>
<meta charset="utf-8">
<title>checkbox test~</title>
<style type="text/css">
</style>
</head>
<body>
<h2>选择你喜欢的食物:</h2>
<form action="" method="get" id="myform">
<p>
<label>
<input type="checkbox" name="checkbox1" value="1">苹果
</label>
<label>
<input type="checkbox" name="checkbox2" value="2">栗子
</label>
<label>
<input type="checkbox" name="checkbox3" value="3">西瓜
</label>
<label>
<input type="checkbox" name="checkbox4" value="4">芒果
</label>
<label>
<input type="checkbox" name="checkbox5" value="5">芒果
</label>
</p>
<h2>你是男士还是女士:</h2>
<p>
<label>
<input type="radio" name="sex" value="man">男士
</label>
<label>
<input type="radio" name="sex" value="woman">女士
</label>
<label>
<input type="radio" name="sex" value="no">保密
</label>
</p>
</form>
</body>
</html>
把checkbox复选框全部选择:
find_elements_by_tag_name()定位,需要判断是否是checkbox
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get(r"http://192.168.225.137/html5/checkbox.html")
#选择页面上所有tag_name是input的元素
inputs = driver.find_elements_by_tag_name("input")
#然后过滤出type为checkbox的元素
for i in inputs: #用tag_name定位需要判断是否是checkbox,如下:
if i.get_attribute("type") == "checkbox":
i.click()
time.sleep(1)
inputs.pop().click()
inputs.pop().click(2)
通过find_elements_by_xpath()和find_elements_by_css_selector()直接定位到checkbox:
不需要判断了,选择所有的复选框后取消第二个和最后一个:
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get(r"http://192.168.225.137/html5/checkbox.html")
driver.set_window_size(1000,1000)
#通过css定位
checkboxs = driver.find_elements_by_css_selector("[type='checkbox']")
#通过xpath定位
inputs = driver.find_elements_by_xpath("//*[@type='checkbox']")
#通过以上两种方式定位就不需要判断定位的标签是否是复选框的了
for i in checkboxs:
i.click()
sleep(1)
#打印当前页面上input="checkbox" 的个数
print(len(inputs))
#把页面上第二个checkbox取到勾选
inputs.pop(1).click()
sleep(2)
driver.find_elements_by_xpath("//*[@type='checkbox']").pop(-1).click()
#前面已经把所有checkbox勾上了,通过pop().click()对某个checkbox再勾选,即是取消勾选。
len()方法可以计算定位到的元素个数;
pop()方法获取列表中某个元素,pop().click()定位到某个checkbox后取消勾选;
pop()\pop(-1)都表示最后一个checkbox;
pop(0)第一个checkbox;
多表单切换
webdriver只能在一个页面上定位和识别元素,对于iframe或frame不能直接定位。
通过switch_to.frame()方法将当前的主体切换为frame或iframe表单的内嵌页面中。
myframe.html
<!DOCTYPE HTML>
<html lang="ch-zn">
<head>
<title>myframe test!!!</title>
<meta charset="utf-8">
<style type="text/css">
h3{text-align:center;color:blue;}
div{text-align:center;}
</style>
</head>
<body>
<h3>myframe</h3>
<div>
<iframe src="http://www.baidu.com/" width="800px" height="200px" name="myframe" id="if"></iframe>
</div>
</body>
</html>

如上内联框架,定位里面的百度页面元素时,先要使用switch_to.frame()找到<iframe>标签,然后再定位百度页面的元素。
from selenium import webdriver
from time import sleep
from selenium.common.exceptions import NoSuchElementException
driver =webdriver.Firefox()
driver.get(r"http://192.168.225.137/html5/myframe.html")
driver.set_window_size(2000,2000)
#切换到iframe里面,iframe(name='myframe')
driver.switch_to.frame("myframe")
#下面就是正常操作
#隐式等待10s
driver.implicitly_wait(10)
try:
el = driver.find_element_by_xpath("//*[@id='kw']")
el1 = driver.find_element_by_id("su")
sleep(2)
except NoSuchElementException as e:
print(e)
else:
el.send_keys("python")
el1.click()
finally:
driver.quit()
switch_to.frame()默认可以去id或name属性值定位,如果没有id或name属性,可以用下面方式定位:
from selenium import webdriver
from time import ctime,sleep
driver = webdriver.Firefox()
driver.implicitly_wait(10)
print(ctime())
driver.get(r"http://192.168.225.137/html5/myframe.html")
#定位iframe的位置保存到变量el
el = driver.find_element_by_xpath("//*[@class='if']")
#切换到该frame
driver.switch_to.frame(el)
#对iframe页面操作
driver.find_element_by_css_selector("#kw").send_keys("iframe")
driver.find_element_by_css_selector("#su").click()
print(ctime())
#跳出当前一级表单
driver.switch_to.parent_frame ()
#切换到最外层的页面
driver.switch_to.default_content()
多窗口切换
在页面操作过程中有时候点击某个链接会弹出新的窗口,
webdriver的switch_to.window()方法,可以实现在不同窗口之间的切换。
打开百度首页,打开新的窗口注册窗口,在返回百度首页窗口。
from selenium import webdriver
from time import *
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get(r"http://www.baidu.com/")
driver.maximize_window()
#获得百度搜索窗口句柄
search_windows = driver.current_window_handle
driver.find_element_by_link_text("登录").click()
driver.find_element_by_link_text("立即注册").click()
#获得当前所有打开窗口的句柄,这里一共就两个句柄。
all_handles = driver.window_handles
#进入注册窗口
for handle in all_handles:
if handle != search_windows: #不是百度句柄,就是注册句柄了。
driver.switch_to.window(handle)
print("现在是注册窗口!")
#获取当前页面的title
title = driver.title
print(title)
pass
#获取当前注册页面的URL
url = driver.current_url
print(url)
#回到搜索窗口
for handle in all_handles:
if handle ==search_windows: #百度句柄了
driver.switch_to.window(handle)
print("现在是搜索窗口!")
#关闭百度登录框
driver.find_element_by_xpath(".//*[@id='TANGRAM__PSP_2__closeBtn']").click()
title = driver.title
print(title)
pass
url = driver.current_url
print(url)
#百度搜索
driver.find_element_by_id("kw").send_keys("python")
driver.find_element_by_id("su").click()
sleep(2)
driver.quit()
webdriver新的属性和方法:
current_window_handle:获取当前窗口句柄
Window_handles:获取所有窗口的句柄
switch_to.window():切换到相应的窗口。用于不同窗口的切换;
switch_to.frame()用于不同表单的切换。
警告框处理
webdriver中处理js所生成的alert、confirm、prompt警告框:(怎么区分是不是警告框的一种方法:利用firebug的“点击查看元素”,是不能定位到警告框的元素位置的,定位到的就不是警告框了,可以通过一般的方式操作该页面的元素,这里要理解警告是怎么产生的,一般是js脚本<script>docum.write(alert())</script>)
使用switch_to_alert()方法定位到alert、confirm、prompt,然后使用text、accept、dismiss、send_keys等方法进行操作。
text:返回alert、confirm、prompt中的文字信息;
accept():接受现有警告框;
dismiss():解散现有警告框;
send_keys(keysToSend):发送文本到警告框。
keyToSend:将文本发送到警告框
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
driver.maximize_window()
#鼠标悬停
el = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(el).perform()
#打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
#点击恢复默认
driver.find_element_by_link_text("恢复默认").click()
sleep(2)
#返回警告框中的文本信息
text = driver.switch_to_alert().text
print(text)
#接受现有警告框
driver.switch_to_alert().accept()
driver.quit()
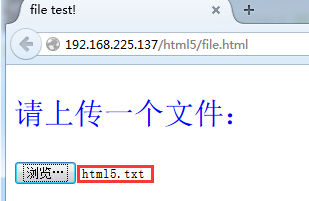
上传文件
file.html
通过input标签实现的上传功能
<!DOCTYPE html>
<html lang="en">
<head>
<title>file test!</title>
<meta charset="utf-8">
</head>
<body>
<p style="color:blue;text-align:left;font-size:30px;">请上传一个文件:</p>
<form action="" method="get" id="myform">
<input type="file" name="file" accept="" multiple="multiple">
</form>
</body>
</html>
实例:通过input标签实现上传功能的可以通过send_keys("文件地址")上传
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(r"http://192.168.225.137/html5/file.html")
#通过send_keys()上传
driver.find_element_by_css_selector("[type='file']").send_keys("C:\\Users\\Administrator\\Desktop\\html5.txt")
from selenium import webdriver
import os
import time
#为了能够让Firefox()实现下载,需要对FirefoxPile()进行设置
fp = webdriver.FirefoxProfile()
#browser.download.folderList设置为0,下载到浏览器默认的路径;设置为2则可以设置下载路径
fp.set_preference('browser.download.folderList',2)
#browser.download.manager.showWhenStarting设为false不显示开始,设为true显示开始
fp.set_preference('browser.download.manager.showWhenStarting',False)
#browser.download.dir用于指定下载文件的目录,os.getcwd()当前目录
fp.set_preference('browser.download.dir',os.getcwd())
#browser.helperApps.neverAsk.saveToDisk指定下载页面的Content-type值,“application/octet-stream”是文件的类型
fp.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/octet-stream')
#将所有设置的信息在调用webdriver的Firefox时作为参数传递给浏览器,Firefox浏览器就是根据折现设置信息将文件下载到设定的脚本目录下。
driver = webdriver.Firefox(firefox_profile = fp)
driver.get('https://pypi.python.org/pypi/selenium')
driver.find_element_by_partial_link_text("selenium-3.0").click()
time.sleep(30)
driver.quit()
为了能够让Firefox()实现下载,需要对FirefoxPile()进行设置:
browser.download.folderList设置为0,下载到浏览器默认的路径;设置为2则可以设置下载路径
browser.download.manager.showWhenStarting设为false不显示开始,设为true显示开始
browser.download.dir用于指定下载文件的目录,os.getcwd()当前目录
browser.helperApps.neverAsk.saveToDisk指定下载页面的Content-type值,“application/octet-stream”是文件的类型
HTTP Content-type常用的对照表:http://tool.oschina.net/commons
操作cookie
有时候我们需要验证浏览器中cookie是否正确。
webdriver提供了操作cookie的相关方法,可以读取、添加、删除cookie信息。
webdriver操作cookie的方法:
get_cookies():获取所有的cookie信息
get_cookie(name):返回字典的key为name的cookie信息
add_cookie(cookie_dict) :添加cookie。cookie_dict值字典对象,必须有name和value值
delete_cookie(name,optionString):删除cookie信息。name是要删除的cookie名称,optionString是该cookie的选项,目前支持的选项包括“路径”,“域”
delete_all_cookies():删除所有的cookie信息
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(r"http://www.hao123.com/")
#获取所有cookies
cookies = driver.get_cookies()
print(cookies)
driver.quit()
from selenium import webdriver
driver = webdriver.Firefox()
driver.get(r"http://www.baidu.com/")
#添加cookie,字典形式且必须有name、value值
driver.add_cookie({"name":"user","value":"tester"})
#遍历所有的cookies中的name、value并打印出来,就会显示添加的信息了
for i in driver.get_cookies():
print("%s => %s"%(i['name'],i['value']))
driver.quit()
调用JavaScript
webdriver对与浏览器的滚动条没有提供相应的操作方法,可以借着JavaScript来控制浏览器的滚动条。webdriver提供了execute_script()方法来执行JavaScript代码。
调整浏览器的滚动条位置的JavaScript方法:
window.scrollTo(水平位置,垂直位置);
水平位置是指水平的左间距;
垂直位置是指垂直的上边距;
for i in range(10):
from selenium import webdriver
from time import *
driver = webdriver.Firefox()
driver.get(r'http://www.baidu.com/')
driver.set_window_size(600,600)
driver.find_element_by_css_selector('#kw').clear()
driver.find_element_by_css_selector('#kw').send_keys("python接口测试")
driver.find_element_by_xpath("//*[@id='su']").click()
sleep(2)
#通过JavaScript设置浏览器窗口的滚动条位置
js = "window.scrollTo(100,300);"
driver.execute_script(js)
sleep(3)
driver.quit()
另外JavaScript的作用还可以像textarea多行文本框输入内容:
多行文本.html
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>多行文本 test!!</title>
</head>
<body>
<h3>请输入你的建议:</h3>
<form action="" method="get" name="1">
<textarea name="suggest" cols="50" rows="10"></textarea>
<br>
<input type="submit" id="3" value="提交叻">
</form>
</body>
</html>
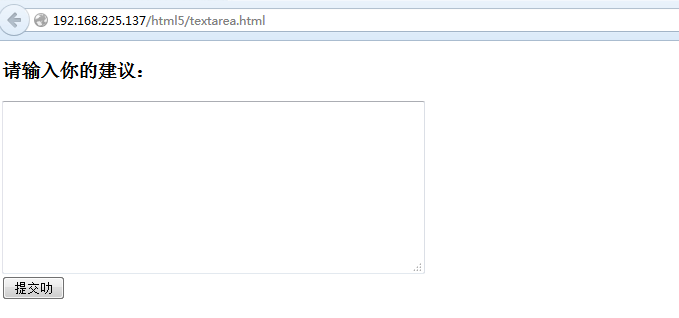
操作textarea文本框
from selenium import webdriver
from time import *
driver = webdriver.Firefox()
driver.get(r"http://192.168.225.137/html5/textarea.html")
driver.maximize_window()
#首先text定义要输入的内容
text = "我的建议是,哈哈哈哈哈哈哈哈"
#然后将text与JavaScript代码通过“+”拼接,这样是使输入的内容变得可以自定义
js = "var sum=document.get_element_by_name('suggest');sum.value='" + text + "';"
#通过execute_script()执行js代码
driver.execute_script(js)
driver.find_element_by_xpath("//*[@id='3']").click()
sleep(5)
driver.quit()
窗口截图
webdriver提供了截图函数get_screenshot_as_file('保存文件的路径')来截取当前窗口。
实例1:截取百度
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get(r'http://www.baidu.com/')
driver.maximize_window()
driver.find_element_by_css_selector('#kw').send_keys("selenium")
driver.find_element_by_id('su').click()
time.sleep(3)
#截取当前窗口,并将图片保存到指定位置
driver.get_screenshot_as_file('E:\\screenshot\\baidu.jpg')
driver.quit()
实例2:截取126邮箱
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get(r'http://www.126.com/')
driver.maximize_window()
driver.implicitly_wait(5)
url = driver.current_url
print(url)
title = driver.title
print(title)
#使用截图函数,截取当前页面
driver.get_screenshot_as_file('E:\\screenshot\\login.jpg')
#登录126邮箱
driver.find_element_by_xpath("//*[@id='login-form']/div/div/div[2]/input").clear()
driver.find_element_by_xpath("//*[@id='login-form']/div/div/div[2]/input").send_keys('XXX—you')
driver.find_element_by_xpath("//*[@type='password']").clear()
driver.find_element_by_xpath("//*[@type='password']").send_keys('yuexxx.')
driver.find_element_by_id('dologin').click()
time.sleep(3)
title = driver.title
print(title)
url = driver.current_url
print(url)
#截取登录后的页面
driver.get_screenshot_as_file("E:\\screenshot\\afterlogin")
time.sleep(3)
#退出邮箱
driver.find_element_by_link_text("退出").click()
driver.quit()
在做UI自动化测试时,可以把该截图函数:get_screenshot_as_file()封装成单独一个模块,需要截取的时直接使用该方法。
定义截图函数。
创建截图函数insert_img(),为了保持自动化项目的可移植性,采用相对
路径的方式将测试截图保存到.\report\image\目录中。
'''
from selenium import webdriver
import os
#截图函数
def insert_img(driver,file_name):
#获取当前运行脚本的路径保存到base_dir里面
base_dir = os.path.dirname(os.path.dirname(__file__))
#把获取到的路径转为字符串
base_dir = str(base_dir)
#字符串函数replace()把路径中的“\\”变成“/”
base_dir = base_dir.replace('\\','/')
#利用split()方法把字符串以“/test_case/”分割为两部分,split分割字符串后保存为列表,把左边的保存到base列表中
base = base_dir.split('/test_case')[0]
#利用字符串拼接重新组合文件路径。get_screenshot_as_file(文件路径+截取到的文件名)
file_path = base +"/report/image/" + file_name
driver.get_screenshot_as_file(file_path)
if __name__ == "__main__":
driver = webdriver.Firefox()
driver.get("https://www.126.com/")
#调用截图函数
insert_img(driver,"126.jpg")
driver.quit()
验证码处理
对于有些登录系统是需要验证码的,怎么处理呢?
去掉验证码
但如果自动化脚本是在正式环境中测试,这种做法就会给系统带来一定的风险。
设置万能的验证码
只要测试时输入一个万能验证码,程序就认为验证通过,否则就判断用户输入的验证码是否正确。设计万能验证码的方式只需要对用户的输入信息多加一个逻辑判断,如下:
number.py
from random import randint
#生成1000到9999之间一个随机数
verify = randint(1000,9999)
print(u"生成的随机数是:%s"%verify)
number =input("请输入一个验证码:")
number = int(number) #把number转为int和随机数类型一致
print(number)
if number == verify: #number和verify类型要一致才有可比性
print("验证码正确!")
elif number == 1234:
print("验证吗正确!")
else:
print("验证码错误!!!")
这个程序分别输入正确的验证码、万能验证码、错误验证码。
记录cookie
通过向浏览器中添加cookie可以要过登录的验证码。














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









