







目录
干货分享,感谢您的阅读!
在现代企业和技术系统中,工作流引擎作为自动化和业务流程管理的核心组件,发挥着至关重要的作用。尤其是在复杂业务场景中,灵活、可配置的工作流引擎能够显著提升流程的自动化程度和系统的响应能力。本文将深入探讨如何设计和实现一个动态配置执行工作流引擎,并以实际业务场景为基础,展示这一技术如何帮助企业实现高效、灵活的工作流管理。从工作流的建模、节点执行到任务调度和错误处理,文章逐步阐述了实现过程中面临的关键技术难题和解决方案,同时结合实际业务应用,分析了如何通过动态配置提升工作流引擎的可扩展性与可维护性。本篇文章不仅适合对工作流引擎感兴趣的开发者,也为有业务流程自动化需求的企业提供了宝贵的技术参考。
一、业界开源工作流处理引擎系统介绍
业界一些可以满足不同需求的非常受欢迎和广泛使用的开源工作流处理引擎系统梳理如下:
-
Apache Airflow:Apache Airflow 是一个基于Python的工作流自动化和调度平台,由Airbnb开发并捐赠给Apache软件基金会。它具有可扩展性、灵活性和强大的功能,可用于构建、调度和监控复杂的工作流。(Apache Airflow: Apache Airflow)
-
Camunda BPM:Camunda BPM 是一个用于工作流和业务过程管理的开源平台,提供了工作流引擎、决策引擎和案例管理等功能。它支持BPMN 2.0标准,并提供了可视化建模工具和强大的执行引擎。(Camunda BPM: The Universal Process Orchestrator | Camunda)
-
Netflix Conductor:Netflix Conductor 是一个用于微服务编排和工作流自动化的开源平台,由Netflix开发。它提供了基于任务的工作流建模方式,并具有可扩展性和高可用性。(Netflix Conductor: https://netflix.github.io/conductor/)
-
Apache NiFi:Apache NiFi 是一个用于数据流处理和自动化的开源项目,由Apache软件基金会维护。它提供了直观的用户界面和强大的数据流管道功能,可用于构建复杂的数据处理工作流。(Apache NiFi: Apache NiFi)
-
Activiti:Activiti 是一个轻量级的工作流和业务流程管理引擎,由Alfresco软件公司开发。它支持BPMN 2.0标准,并提供了灵活的工作流建模和执行功能。(Activiti: Open Source Business Automation | Activiti)
具体感兴趣可以先自行查看,后续对于以上工作流处理引擎系统的分析会单独在写博客。
二、思考关键实现手段
实现一个动态工作流配置化处理引擎需要考虑多个方面:
-
工作流建模和编排: 提供一种方式让用户能够定义和设计工作流程,通常包括图形化界面或者DSL(领域特定语言)或指定相关配置可解释字符串,用于描述工作流程中的任务、依赖关系和执行顺序。
-
任务执行和调度: 实现任务的执行和调度,确保任务能够按照定义的顺序和依赖关系正确执行。其中可能涉及到如任务队列、调度器和执行器等组件。
-
状态管理和监控: 实现状态管理机制,以跟踪工作流程的执行状态,并提供监控和报告功能,以便用户可以了解工作流程的进度和性能。
-
容错和恢复: 设计容错和恢复机制,以应对任务执行失败或者系统故障的情况,确保工作流程能够正确地恢复并继续执行。
-
版本控制和回滚: 提供版本控制功能,使用户能够管理和回滚工作流程的变更。这可以通过使用版本控制系统或者记录历史操作来实现。
-
权限控制和安全性: 确保工作流引擎的安全性,包括数据的保护、用户身份验证和授权等方面。通常需要实现用户管理、角色管理和访问控制等功能。
-
可扩展性和灵活性: 考虑到未来的需求变化和扩展性,设计一个灵活和可扩展的架构,可能涉及到插件系统、扩展点和自定义组件等。
-
性能优化和资源管理: 对于大规模的工作流引擎,需要考虑性能优化和资源管理,以确保系统能够高效地运行并有效地利用资源。
-
集成和交互: 考虑如何与其他系统集成和交互,例如与数据库、消息队列、监控系统等。需要提供API或者集成插件等。
三、实现动态配置执行工作流
(一)整体架构简易版分析
一个简单的动态配置执行工作流的基本思路如下,主要包括配置平台、调度平台和业务分析平台。
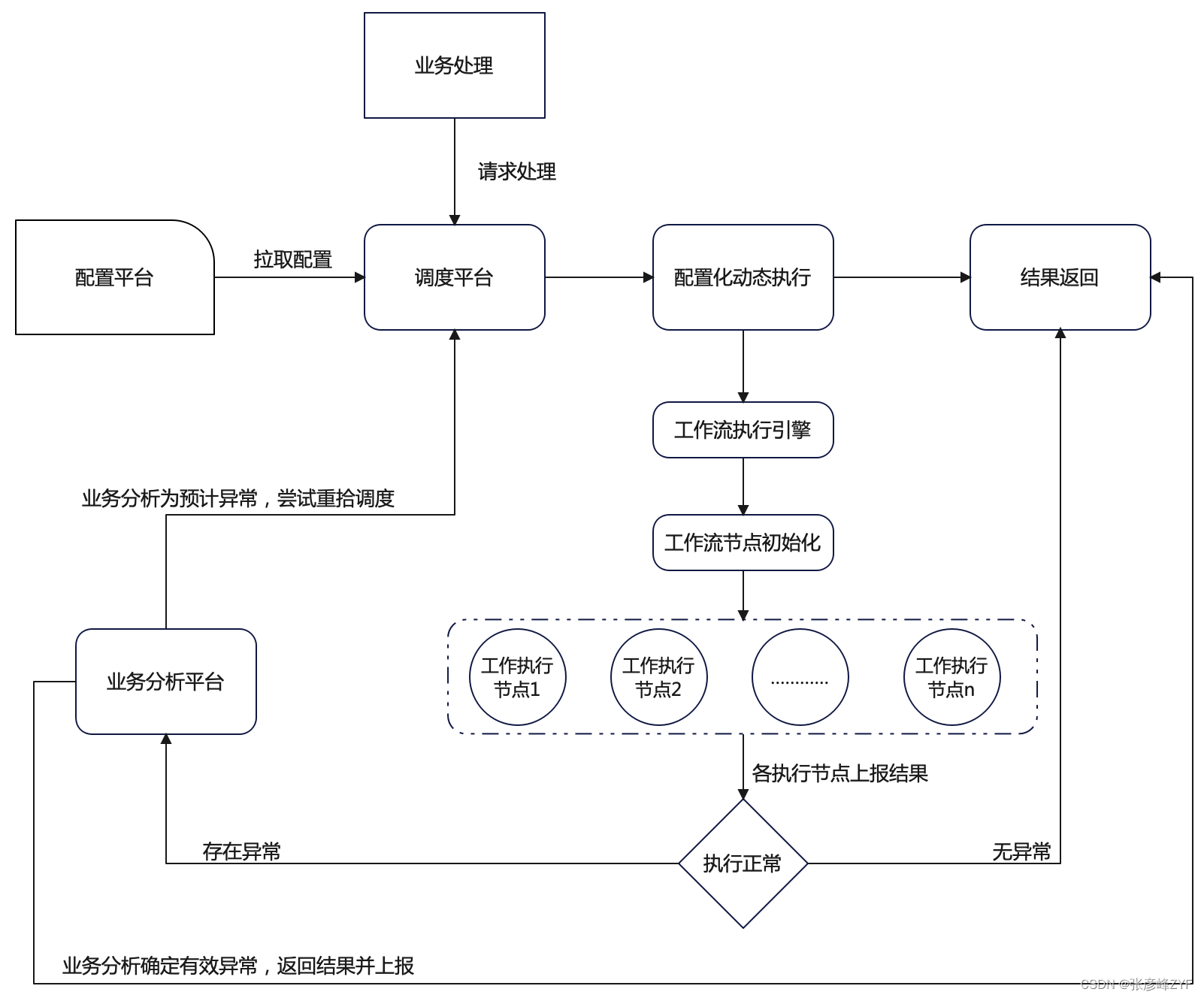
配置平台:
- 提供用户界面或API,让用户能够对业务处理流程进行动态配置。配置内容包括上下文信息参数、流转配置以及工作执行节点的配置。
- 配置平台可能需要支持多种类型的任务节点,例如HTTP请求、数据库操作、消息队列处理等。
- 配置信息可以存储在数据库或者配置文件中,以便后续调度使用。
调度平台:
- 接收业务请求,并根据请求的信息结合相应的动态配置信息进行调度任务的组装。
- 生成唯一的调度任务ID,并将任务信息存储在任务队列或者数据库中。
- 根据任务队列中的任务信息,调度执行任务,并将执行结果返回给请求方。
业务分析平台:
- 监控动态执行流程的执行情况,包括成功、失败和异常等情况。
- 对于执行成功的情况,直接返回执行结果。
- 对于工作执行节点存在异常的情况,进行异常记录和上报。
- 对于预期内的异常情况,调用调度平台进行重新尝试,直到尝试达到一定次数或者超时。
- 分析并记录每次执行的结果,并根据需要进行报表统计和数据分析。
这个简单版本的实现思路可以作为一个基础版本,后续可以根据实际需求进行扩展和优化,例如增加任务状态监控、错误处理机制、任务优先级调度等功能。为了简化,只关注聚焦在配置化动态执行部分的代码实现,并且相关监控执行上报和执行处理等步骤暂时不做处理。
(二)核心工作流实现
定义动态配置工作流执行上下文信息
动态配置工作流执行上下文信息是一种提高工作流程灵活性、可扩展性、可维护性和可监控性的有效手段,可以根据不同的业务需求和环境条件,动态地调整和配置工作流程的参数和属性,以实现最优的业务处理效果。基本定义如下:
package org.zyf.javabasic.workflowpipline.core;
import com.google.common.collect.Maps;
import lombok.Data;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
import org.apache.commons.lang3.builder.ToStringStyle;
import org.apache.commons.lang3.math.NumberUtils;
import org.zyf.javabasic.workflowpipline.constants.PipelineConstant;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowRequest;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowResult;
import java.io.Serializable;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 动态配置工作流执行上下文信息
* @author: zhangyanfeng
* @create: 2024-02-13 19:19
**/
@Data
public class WorkflowExecutionContext implements Serializable {
private static final long serialVersionUID = 1180080154658968619L;
/**
* 上下文变量
*/
private Map<String, Object> contextAttrs = Maps.newConcurrentMap();
/**
* 请求信息
*/
private WorkflowRequest request = new WorkflowRequest();
/**
* 结果集信息
*/
private WorkflowResult result = new WorkflowResult();
public String getWorkflowExecutionConfig() {
return getContextAttr(PipelineConstant.PIPELINE_CONFIG);
}
/**
* 获取上下文属性
*/
@SuppressWarnings("unchecked")
public <T> T getContextAttr(String key) {
if (MapUtils.isEmpty(contextAttrs)) {
return null;
}
return (T) contextAttrs.get(key);
}
public void setContextAttr(String key, Object val) {
if (MapUtils.isEmpty(contextAttrs)) {
contextAttrs = Maps.newConcurrentMap();
}
contextAttrs.put(key, val);
}
/**
* 获取业务动态工作流相关请求参数
*/
public String getBizWorkflowConfig(String key) {
return request.getExt(key);
}
public String getBizWorkflowConfig(String key, String defaultValue) {
String value = getBizWorkflowConfig(key);
if (StringUtils.isEmpty(value)) {
return defaultValue;
}
return value;
}
public boolean getBizWorkflowParamBoolean(String key, boolean defaultValue) {
try {
String result = getBizWorkflowConfig(key);
return Boolean.parseBoolean(result);
} catch (Exception e) {
return defaultValue;
}
}
public int getSceneParamInt(String key, int defaultValue) {
try {
String result = getBizWorkflowConfig(key);
return NumberUtils.toInt(result, defaultValue);
} catch (Exception e) {
return defaultValue;
}
}
/**
* 过去指定配置信息
* @param key 指定配置
* @param defaultValue 默认值
* @param scenarioIdentifier 用于标识特定场景或情景
* @return
*/
public String getBizWorkflowConfig(String key, String defaultValue, String scenarioIdentifier) {
return StringUtils.defaultIfBlank(getBizWorkflowConfig(scenarioIdentifier.concat(key)), getBizWorkflowConfig(key, defaultValue));
}
public String getSceneConfigWithIdentifier(String key, String scenarioIdentifier) {
return StringUtils.defaultIfBlank(getBizWorkflowConfig(scenarioIdentifier.concat(key)), getBizWorkflowConfig(key));
}
/**
* 设置RecResult
*/
public WorkflowExecutionContext result(WorkflowResult recResult) {
this.result = recResult;
return this;
}
@Override
public String toString() {
return ToStringBuilder.reflectionToString(this, ToStringStyle.SHORT_PREFIX_STYLE);
}
}
定义工作流
Workflow 类负责管理和执行工作流的基本定义,包括执行任务接口集合整理、执行任务整合分析以及根据配置生成的执行节点结构等信息。通过注册执行任务接口和构建执行节点结构,可以实现灵活和动态的工作流程执行。相关细节性见代码内容:
package org.zyf.javabasic.workflowpipline.core;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import lombok.Data;
import org.apache.commons.lang3.StringUtils;
import org.zyf.javabasic.workflowpipline.constants.PipelineConstant;
import org.zyf.javabasic.workflowpipline.section.ExecutionNode;
import java.util.Collections;
import java.util.List;
import java.util.Map;
/**
* @program: zyfboot-javabasic
* @description: 工作流基本定义
* @author: zhangyanfeng
* @create: 2024-02-14 09:59
**/
@Data
public class Workflow {
/**
* 用于存储所有注册的执行任务接口。执行任务接口可以执行特定的任务或者操作。
*/
private static List<ExecutorWorker> workers = Lists.newLinkedList();
/**
* 用于存储执行任务接口的名称和对应的执行任务接口对象
*/
private static Map<String, ExecutorWorker> workerMap = Maps.newHashMap();
/**
* 用于存储工作流的执行节点结构。每个执行节点表示了工作流程中的一个执行步骤或者操作。
*/
private List<ExecutionNode> executionNodes = Lists.newLinkedList();
/**
* 用于根据传入的执行上下文信息初始化并获取执行节点列表。
* 根据执行上下文中的配置信息,构建工作流程的执行节点,并返回给调用方。
*/
public List<ExecutionNode> initExecutionNodes(WorkflowExecutionContext context) {
String pipelineCfg = context.getBizWorkflowConfig(PipelineConstant.PIPELINE_CONFIG);
if (StringUtils.isBlank(pipelineCfg)) {
return Collections.emptyList();
}
return ExecutionNode.buildExecutionNodes(pipelineCfg);
}
/**
* 用于获取执行任务接口的名称和对应的执行任务接口对象的映射。
* 通过调用这个方法,可以获取所有注册的执行任务接口信息。
*/
public Map<String, ExecutorWorker> getWorkerMap() {
return workerMap;
}
/**
* 用于注册执行任务接口。
* 当注册执行任务接口时,会将执行任务接口添加到 workers 列表中,
* 并将执行任务接口的名称和对象添加到 workerMap 中,以便后续查找和使用。
*/
public static void registerWorker(String workerName, ExecutorWorker executorWorker) {
workers.add(executorWorker);
workerMap.put(workerName, executorWorker);
}
}
定义执行节点
ExecutionNode 类负责表示执行节点的信息,并通过递归方法构建执行节点的层级结构。具体代码和细节见:
package org.zyf.javabasic.workflowpipline.node;
import com.google.common.base.Splitter;
import com.google.common.collect.Lists;
import lombok.Data;
import org.apache.commons.lang3.StringUtils;
import org.zyf.javabasic.workflowpipline.enums.ExecMode;
import java.util.Iterator;
import java.util.List;
import java.util.Stack;
/**
* @program: zyfboot-javabasic
* @description: 执行节点信息
* @author: zhangyanfeng
* @create: 2024-02-14 10:34
**/
@Data
public final class ExecutionNode {
/**
* 节点的名称,用于标识执行节点的类型或任务
*/
private String nodeName;
/**
* 节点的执行类型,表示节点执行的方式或模式。通常情况下,这里是指 ExecMode.worker
*/
private ExecMode execMode;
/**
* 当前节点用于标识特定场景或情景的字符串,用于区分同一个节点在不同配置中的使用。确保全局唯一性。
*/
private String scenarioIdentifier = StringUtils.EMPTY;
/**
* 该节点的子节点列表,用于表示节点的下一级子节点。
* 每个子节点也是一个 ExecutionNode 类型的对象。
*/
private List<ExecutionNode> executionNodes = Lists.newLinkedList();
/**
* 用于根据传入的节点配置信息构建节点列表。
* 节点配置信息以字符串的形式表示,通过解析字符串构建节点的层级结构。
*/
public static List<ExecutionNode> buildExecutionNodes(String workerConfig) {
List<String> workerList = Splitter.on(",").omitEmptyStrings().trimResults().splitToList(workerConfig);
Iterator<String> workerIterator = workerList.iterator();
return buildExecutionNode(workerIterator.next(), null, null, workerIterator);
}
/**
* 递归方法,用于构建执行节点的层级结构。
* 接受节点名称、已构建的节点列表、父节点堆栈和未处理的节点名称迭代器作为参数,并根据这些参数构建节点的层级结构。
*
* @param name 初始节点名称
* @param executionNodes 已经构建好的节点信息
* @param parents 父级节点堆栈
* @param tailWorkerNames 剩余未处理的节点名称
* @return
*/
private static List<ExecutionNode> buildExecutionNode(String name, List<ExecutionNode> executionNodes, Stack<ExecutionNode> parents,
Iterator<String> tailWorkerNames) {
if (null == parents) {
parents = new Stack<>();
}
if (null == executionNodes) {
executionNodes = Lists.newLinkedList();
}
ExecutionNode executionNode = buildExecutionNodeByName(name);
if (parents.isEmpty()) {
executionNodes.add(executionNode);
} else {
parents.peek().getExecutionNodes().add(executionNode);
}
if (tailWorkerNames.hasNext()) {
buildExecutionNode(tailWorkerNames.next(), executionNodes, parents, tailWorkerNames);
}
return executionNodes;
}
/**
* 私有静态方法,用于构建单个执行节点。
* 根据节点名称解析出节点的名称和场景标识符,并创建一个新的 ExecutionNode 对象。
*/
private static ExecutionNode buildExecutionNodeByName(String name) {
ExecutionNode executionNode = new ExecutionNode();
String[] nameParts = StringUtils.split(name, ":");
String nodeName = nameParts[0];
String scenarioIdentifier = (nameParts.length > 1) ? nameParts[1] : StringUtils.EMPTY;
executionNode.setNodeName(nodeName);
executionNode.setExecMode(ExecMode.worker);
executionNode.setScenarioIdentifier(scenarioIdentifier);
return executionNode;
}
}
节点执行接口定义
package org.zyf.javabasic.workflowpipline.node;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
/**
* @program: zyfboot-javabasic
* @description: 节点执行逻辑
* @author: zhangyanfeng
* @create: 2024-02-14 09:55
**/
public interface NodeExecutor {
/**
* 节点逻辑执行
*/
WorkflowExecutionContext execute(Workflow workflow, ExecutionNode executionNode, WorkflowExecutionContext context) throws Exception;
}
节点执行模版定义
package org.zyf.javabasic.workflowpipline.node;
import lombok.extern.log4j.Log4j2;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
/**
* @program: zyfboot-javabasic
* @description: 节点执行器实现模版
* @author: zhangyanfeng
* @create: 2024-02-14 10:35
**/
@Log4j2
public abstract class AbstractNodeExecutor implements NodeExecutor {
/**
* 提交执行处理
*/
@Override
public WorkflowExecutionContext execute(Workflow workflow,
ExecutionNode executionNode,
WorkflowExecutionContext context) throws Exception {
return doExecute(workflow, executionNode, context);
}
/**
* 执行节点逻辑
*/
public abstract WorkflowExecutionContext doExecute(Workflow workflow,
ExecutionNode executionNode,
WorkflowExecutionContext context) throws Exception;
}任务执行器定义
package org.zyf.javabasic.workflowpipline.node;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.core.WorkerExecutor;
/**
* @program: zyfboot-javabasic
* @description: 任务执行器
* @author: zhangyanfeng
* @create: 2024-02-15 10:01
**/
public class WorkerNodeExecutor extends AbstractNodeExecutor {
@Override
public WorkflowExecutionContext doExecute(Workflow workflow, ExecutionNode executionNode, WorkflowExecutionContext context) throws Exception {
if (!workflow.getWorkerMap().containsKey(executionNode.getNodeName())) {
throw new Exception("动态工作流配置有误");
}
return WorkerExecutor.executeWorker(workflow.getWorkerMap().get(executionNode.getNodeName()), context, executionNode.getScenarioIdentifier());
}
}执行任务实现接口定义
ExecutorWorker 接口定义了执行任务的方法和一些辅助方法,用于执行具体的任务操作并进行参数校验,具体如下:
package org.zyf.javabasic.workflowpipline.core;
/**
* @program: zyfboot-javabasic
* @description: 执行任务实现接口
* @author: zhangyanfeng
* @create: 2024-02-14 09:56
**/
public interface ExecutorWorker {
/**
* 用于执行数据处理步骤
* 接受一个 WorkflowExecutionContext 对象作为参数,表示执行任务的上下文信息,
* 然后执行相应的任务操作,并返回更新后的上下文信息。
*/
WorkflowExecutionContext work(WorkflowExecutionContext context);
/**
* 用于执行推荐步骤
* 与上面的方法类似,但还接受一个额外的参数 scenarioIdentifier,用于标识特定的场景或情景。
*/
WorkflowExecutionContext work(WorkflowExecutionContext context, String scenarioIdentifier);
/**
* 用于根据 @WorkerInfo 注解校验执行任务所需的参数
* 接受一个 WorkflowExecutionContext 对象作为参数,表示执行任务的上下文信息,
* 然后校验参数是否满足任务的要求,并返回校验结果。
*/
boolean checkParams(WorkflowExecutionContext ctx);
/**
* 用于获取执行任务的名称,通常是通过 @WorkerInfo 注解中的 name 属性指定的
* 返回一个字符串,表示执行任务的名称。
*/
String getName();
}
基本执行任务基类
package org.zyf.javabasic.workflowpipline.core;
import org.apache.commons.collections.CollectionUtils;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import java.util.Objects;
/**
* @program: zyfboot-javabasic
* @description: 基本执行任务基类
* @author: zhangyanfeng
* @create: 2024-02-15 10:20
**/
public abstract class BaseExecutorWorker implements ExecutorWorker {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context, String scenarioIdentifier) {
return work(context);
}
@Override
public boolean checkParams(WorkflowExecutionContext ctx) {
WorkerInfo workerInfo = this.getClass().getAnnotation(WorkerInfo.class);
if (Objects.isNull(workerInfo)) {
return true;
}
return !workerInfo.skipIfItemsIsEmpty() || CollectionUtils.isNotEmpty(ctx.getResult().getItems());
}
/**
* 获取worker的名称(通过@WorkerInfo中name属性指定)
*/
@Override
public String getName() {
WorkerInfo workerInfo = this.getClass().getAnnotation(WorkerInfo.class);
if (Objects.isNull(workerInfo)) {
return this.getClass().getSimpleName();
}
return workerInfo.name();
}
}任务执行模版
package org.zyf.javabasic.workflowpipline.core;
import lombok.extern.slf4j.Slf4j;
/**
* @program: zyfboot-javabasic
* @description: 实际任务执行
* @author: zhangyanfeng
* @create: 2024-02-14 10:13
**/
@Slf4j
public class WorkerExecutor {
/**
* work执行
*/
public static WorkflowExecutionContext executeWorker(ExecutorWorker worker,
final WorkflowExecutionContext context, String scenarioIdentifier) throws Exception {
try {
if (!worker.checkParams(context)) {
return context;
}
return worker.work(context, scenarioIdentifier);
} catch (Exception e) {
boolean exceptionSkip = Boolean.parseBoolean(context.getContextAttr(worker.getName() + ".exception.skip"));
// 跟worker配置决定是否进一步抛出异常
if (!exceptionSkip) {
log.error(worker.getName() + "Worker执行失败:", e);
throw new Exception("系统繁忙或其他未处理的异常!");
}
}
return context;
}
}
工作流任务执行器
package org.zyf.javabasic.workflowpipline.core;
import lombok.extern.slf4j.Slf4j;
import org.zyf.javabasic.workflowpipline.constants.PipelineConstant;
import org.zyf.javabasic.workflowpipline.node.ExecutionNode;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 工作流执行器具体运行
* @author: zhangyanfeng
* @create: 2024-02-14 10:02
**/
@Slf4j
public class WorkflowExecutor {
/**
* 单例
*/
public static final WorkflowExecutor INSTANCE = new WorkflowExecutor();
public WorkflowExecutionContext pipelineExecute(Workflow workerflow, WorkflowExecutionContext context) {
List<ExecutionNode> executionNodes = workerflow.initExecutionNodes(context);
for (ExecutionNode executionNode : executionNodes) {
try {
context = executionNode.getExecMode().getExecutor().execute(workerflow, executionNode, context);
} catch (Exception e) {
log.error(executionNode.getNodeName() + e.getMessage());
}
// 是否终止pipeline
boolean breakPipeline = Boolean.parseBoolean(context.getContextAttr(PipelineConstant.PIPELINE_FOECE_BREAK));
if (breakPipeline) {
log.warn("ProcessPipelineExecutor pipeline force break by " + executionNode.getNodeName());
break;
}
}
return context;
}
}动态工作流执行引擎
package org.zyf.javabasic.workflowpipline.core;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowResult;
/**
* @program: zyfboot-javabasic
* @description: 具体执行引擎实现
* @author: zhangyanfeng
* @create: 2024-02-14 09:58
**/
@Service
public class ExecutionEngine {
/**
* 执行工作流水线
*/
public WorkflowResult process(WorkflowExecutionContext context) {
WorkflowExecutionContext workflowExecutionContext = WorkflowExecutor
.INSTANCE
.pipelineExecute(new Workflow(), context);
return workflowExecutionContext.getResult();
}
}对外接口定义
package org.zyf.javabasic.workflowpipline.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.core.ExecutionEngine;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowRequest;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowResult;
import javax.annotation.Resource;
/**
* @program: zyfboot-javabasic
* @description: 动态任务执行对外接口
* @author: zhangyanfeng
* @create: 2024-02-15 14:39
**/
@Service
@Slf4j
public class BizWorkflowExecutor {
@Resource
private ExecutionEngine executionEngine;
public WorkflowResult startDynamicExecution(WorkflowRequest request) {
log.info("SceneProcessService startPipLineProcess request:{}", request);
// 1.上下文构建(直接先模拟一个)
WorkflowExecutionContext context = getProcessPipelineContext(request);
// 3. 执行pipLine
WorkflowResult workflowResult = executionEngine.process(context);
log.info("SceneProcessService startPipLineProcess result:{}", workflowResult);
return workflowResult;
}
private static WorkflowExecutionContext getProcessPipelineContext(WorkflowRequest request) {
WorkflowExecutionContext workflowExecutionContext = new WorkflowExecutionContext();
workflowExecutionContext.setRequest(request);
return workflowExecutionContext;
}
}
(三)具体业务场景举例
业务背景说明
假设存在大背景如下,我们期望最终构建知识中台理念。
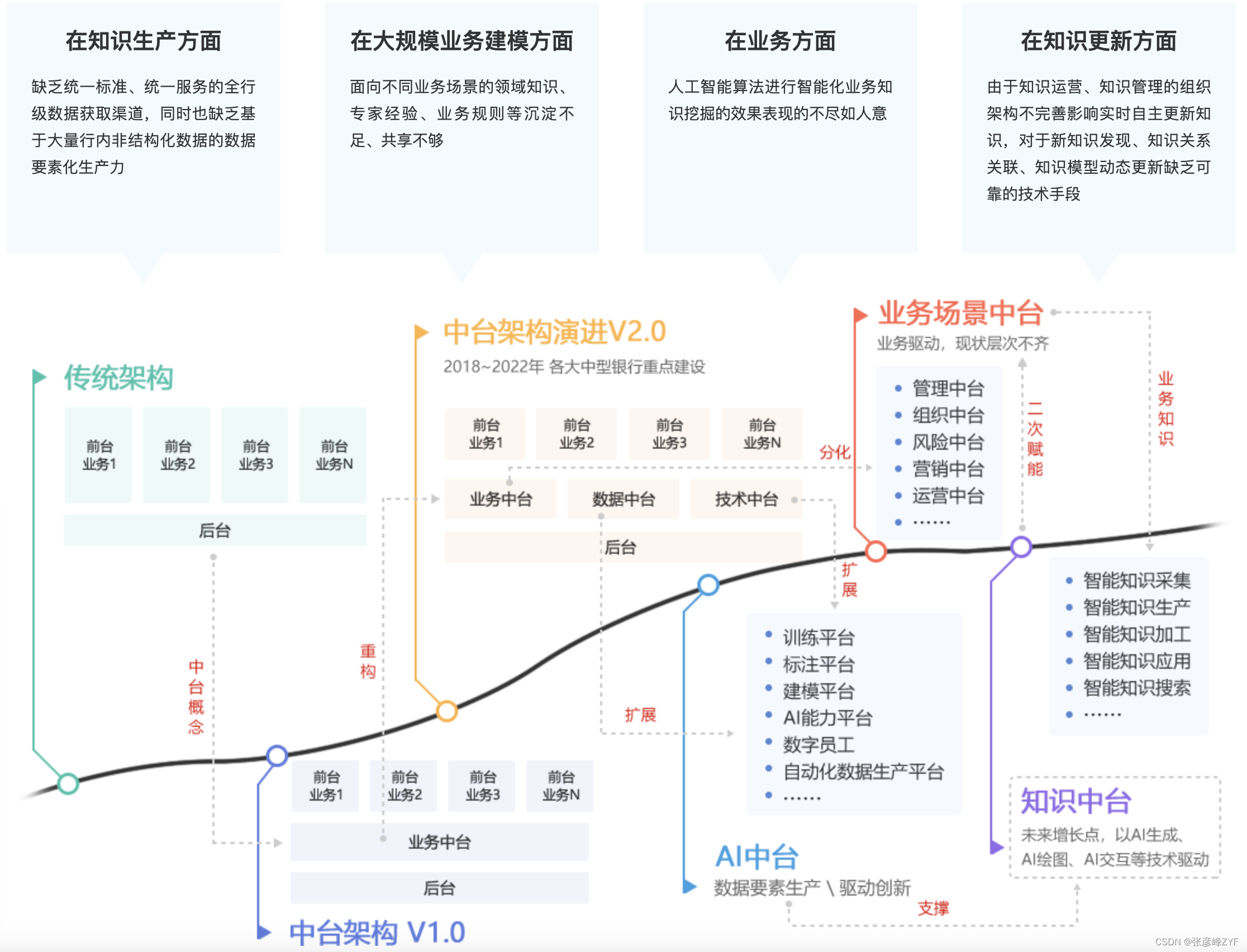
搭建知识中台,赋能业务场景基本架构图如下:
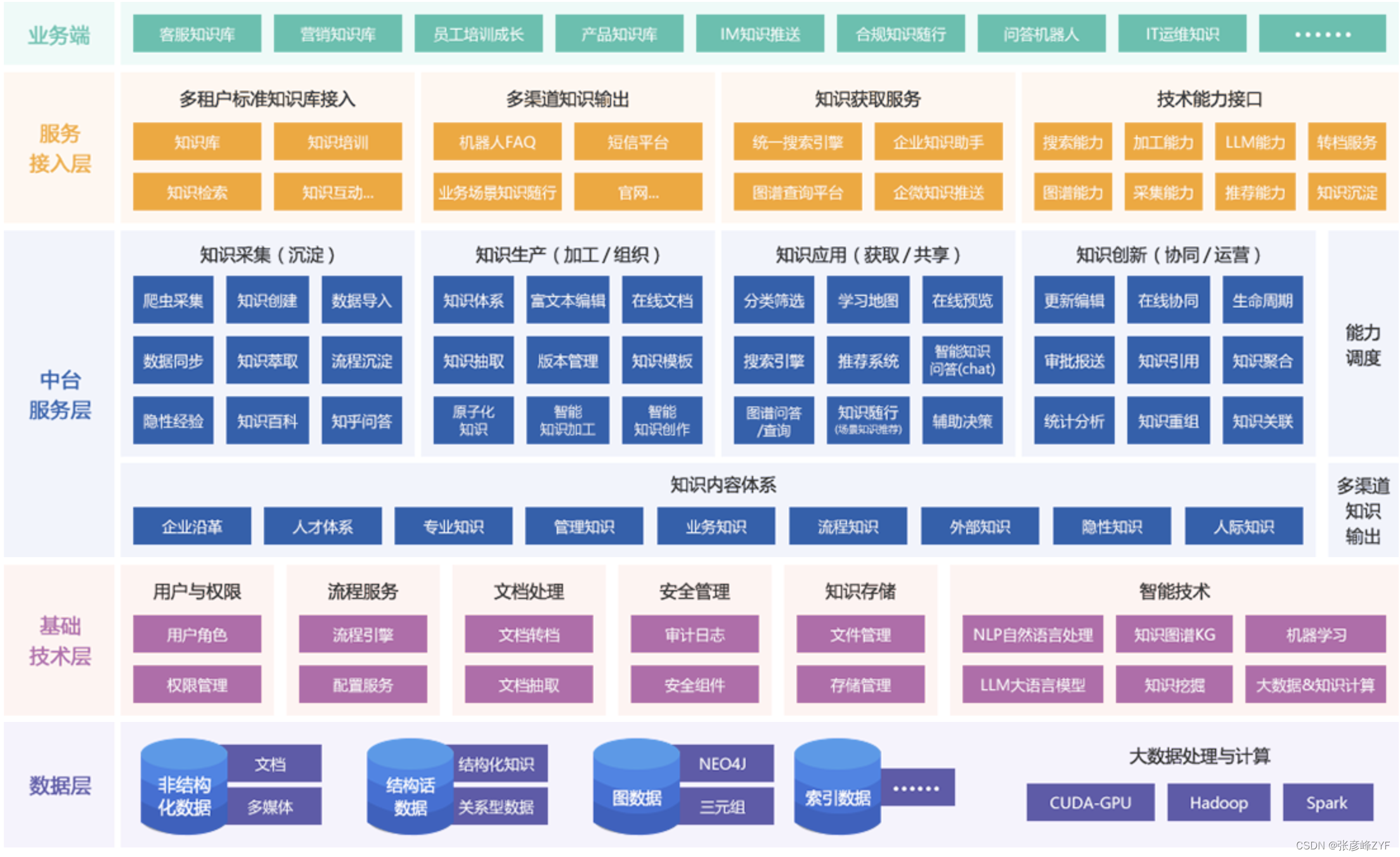
假设业务上需要对新闻类信息进行动态化处理入库库,对应上图中的知识生产处理:

为了简化,相关体系构建先做最基本的处理,只简化为以下基本流程并作动态化处理。
![]()
初始化工作节点赋能
package org.zyf.javabasic.workflowpipline.worker.check;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.BaseExecutorWorker;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowRequest;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowResult;
/**
* @program: zyfboot-javabasic
* @description: 初始化参数检查
* @author: zhangyanfeng
* @create: 2024-02-15 13:46
**/
@Slf4j
@WorkerInfo(name = "initCheckWorker")
@Service
public class InitCheckWorker extends BaseExecutorWorker implements InitializingBean {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context) {
log.info("InitCheckWorker deal!");
WorkflowRequest request = context.getRequest();
log.info("InitCheckWorker request check items valid info done!");
//假定检查数据没有问题,则当前默认结果中需要对齐进行后续的加工处理
//模拟一个基本结果类型
WorkflowResult result = new WorkflowResult();
result.setItems(context.getRequest().getItems());
context.setResult(result);
return context;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
知识力补全工作节点赋能
基类定义
package org.zyf.javabasic.workflowpipline.worker.complement;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.zyf.javabasic.workflowpipline.core.BaseExecutorWorker;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import java.util.List;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: 内容补全任务基类
* @author: zhangyanfeng
* @create: 2024-02-15 13:47
**/
@Slf4j
public abstract class AbstractComplementWorker extends BaseExecutorWorker {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context) {
if (CollectionUtils.isEmpty(context.getRequest().getItems())) {
log.info("AbstractComplementWorker items is empty, game over");
return context;
}
return doWork(context);
}
/**
* 子类补全
*/
protected abstract WorkflowExecutionContext doWork(WorkflowExecutionContext context);
/**
* 根据类型拿到所有的item
*/
protected List<Item> getTypedItems(WorkflowExecutionContext context, String... itemType) {
return context.getResult().getItems().stream()
.filter((item) -> StringUtils.equalsAnyIgnoreCase(item.getItemType(), itemType))
.collect(Collectors.toList());
}
protected void addResult(WorkflowExecutionContext context, List<Item> typedItems) {
List<Item> resultItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(resultItems)) {
context.getResult().setItems(typedItems);
}
}
}
新闻类补全处理
package org.zyf.javabasic.workflowpipline.worker.complement;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.enums.ItemType;
import org.zyf.javabasic.workflowpipline.enums.ProcessType;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import org.zyf.javabasic.workflowpipline.model.biz.NewExtInfo;
import org.zyf.javabasic.workflowpipline.model.biz.NewsModel;
import java.util.*;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: 新闻相关信息补全整合为知识力元数据
* @author: zhangyanfeng
* @create: 2024-02-15 13:49
**/
@Slf4j
@WorkerInfo(name = "newsComplementWorker")
@Service
public class NewsComplementWorker extends AbstractComplementWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
// 抽取item
List<Item> items = getTypedItems(context, ItemType.NEWS.name());
if (CollectionUtils.isEmpty(items)) {
return context;
}
// 模拟:按相关策略进行新闻类相关信息的源头查询,并进行转换成基本的知识力元数据 NewsConverter.fillInfo
List<String> itemIds = items.stream().map(Item::getItemId).collect(Collectors.toList());
List<NewsModel> news = getNewsModels(itemIds);
if (CollectionUtils.isEmpty(news)) {
return context;
}
//整合传入的知识库初始加工信息
Map<String, Object> originData = items.stream()
.collect(Collectors.toMap(
Item::getItemId,
item -> Objects.nonNull(item.getData()) ? item.getData() : KnowledgeMetadata.builder().build(),
// Keep the existing value in case of a duplicate key
(existingValue, newValue) -> existingValue
));
;
// 将实际新闻类相关信息与传入加工data进行比对,整合成知识力模型返回
List<Item> itemComplements = Lists.newArrayList();
news.stream().forEach(newsModel -> {
Item item = new Item();
item.setItemId(newsModel.getId());
item.setItemType(ItemType.NEWS.name());
//如果本身对数据有更新则直接按传入加工已有数据初始化
KnowledgeMetadata data = Item.getData(originData.get(newsModel.getId()), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
data = KnowledgeMetadata.builder().build();
}
//提炼新闻实际内容转为对应知识力元数据
data.setId(newsModel.getId());
data.setContentType(ItemType.NEWS.name());
data.setUkId(ItemType.NEWS.name().toLowerCase() + "_" + newsModel.getId());
data.setTitle(newsModel.getTitle());
data.setContent(newsModel.getContent());
data.setSummary(newsModel.getSummary());
if (StringUtils.isNotBlank(newsModel.getTitle())) {
data.setTitleLength(newsModel.getTitle().length());
}
if (StringUtils.isNotBlank(newsModel.getContent())) {
data.setContentLength(newsModel.getContent().length());
}
data.setAuthor(newsModel.getAuthor());
data.setGmtCreate(newsModel.getPublishedDate());
data.setGmtModified(newsModel.getLastUpdated());
data.setExtInfo(getExtInfo(newsModel));
data.setStatus(newsModel.getKnowledgeStatus(newsModel.getStatus()));
data.setSplitType("st");
data.setProcessType(ProcessType.FINAI.name());
item.setData(data);
itemComplements.add(item);
});
context.getResult().setItems(itemComplements);
return context;
}
private List<NewsModel> getNewsModels(List<String> itemIds) {
NewsModel news = NewsModel.builder()
.id(String.valueOf(new Random().nextLong()))
.title("科学家发现新的太阳系外行星")
.summary("科学家宣布在距离地球不远的星系中发现了一颗可能适宜生命存在的行星。")
.content("近日,天文学家在距离地球仅40光年的系外行星上发现了液态水的迹象,这颗行星围绕一颗红矮星运行,被命名为“K2-18b”。科学家认为这颗行星上可能存在生命。")
.author("张彦峰")
.source("网易科技")
.publishedDate(1701398032000L)
.lastUpdated(1701399412000L)
.category("科技")
.tags(Arrays.asList("太空", "发现", "外星生命"))
.imageUrl("http://example.com/news/k2-18b.png")
.videoUrl("http://example.com/news/k2-18b.mp4")
.status("published")
.language("zh-CN")
.slug("kexuejia-faxian-xin-de-taiyangxi-waixingxing")
.isPrivate(false)
.viewableBy(Arrays.asList("all"))
.build();
NewsModel economicNews = NewsModel.builder()
.id(String.valueOf(new Random().nextLong()))
.title("全球经济面临挑战,国际货币基金组织下调增长预期")
.summary("面对持续的疫情影响和地缘政治紧张,国际货币基金组织调低了全球经济增长的预期。")
.content("根据国际货币基金组织的最新报告,由于新冠疫情的不断冲击和多地区的政治不稳定,全球经济增长率预期被下调至3.2%。这一情况对交易市场和国际投资产生了影响,许多经济学家呼吁各国政府采取措施以避免经济衰退。")
.author("张彦峰")
.source("财经时报")
.publishedDate(1707361012000L)
.lastUpdated(1707367616000L)
.category("经济")
.tags(Arrays.asList("全球经济", "IMF", "增长预期"))
.imageUrl("http://example.com/news/economic-outlook.png")
.videoUrl("http://example.com/news/economic-outlook.mp4")
.status("published")
.language("zh-CN")
.slug("quanjingji-mianlin-tiaozhan")
.isPrivate(false)
.viewableBy(Arrays.asList("all"))
.build();
NewsModel fertilityNews = NewsModel.builder()
.id(String.valueOf(new Random().nextLong()))
.title("国家统计局数据显示,生育率持续下降引发关注")
.summary("最新统计数据揭示,国家生育率继续下降,引起政策制定者和学者的广泛关注。")
.content("据国家统计局的数据显示,过去十年间,国家的生育率呈持续下降趋势。目前,生育率已跌至1.3,远低于维持人口更替水平的2.1。此现象引发了政策制定者的担忧,他们正在考虑推出一系列措施来鼓励生育,包括提高育儿津贴、延长产假等。")
.author("张彦峰")
.source("国家日报")
.publishedDate(1707367616000L)
.lastUpdated(1707378416000L)
.category("社会")
.tags(Arrays.asList("生育率", "人口政策", "统计数据"))
.imageUrl("http://example.com/news/fertility-rate.png")
.videoUrl("http://example.com/news/fertility-rate.mp4")
.status("published")
.language("zh-CN")
.slug("shengyulv-chixuxiajiang")
.isPrivate(false)
.viewableBy(Arrays.asList("all"))
.build();
return Lists.newArrayList(news, economicNews, fertilityNews);
}
private String getExtInfo(NewsModel newsModel) {
if (Objects.isNull(newsModel)) {
return NewExtInfo.builder().toString();
}
return NewExtInfo.builder()
.category(newsModel.getCategory())
.tags(newsModel.getTags())
.imageUrl(newsModel.getImageUrl())
.videoUrl(newsModel.getVideoUrl())
.isPrivate(newsModel.isPrivate())
.viewableBy(newsModel.getViewableBy()).build().toString();
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
内容拆段工作节点赋能
package org.zyf.javabasic.workflowpipline.worker.split;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.enums.ItemType;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import org.zyf.javabasic.workflowpipline.utils.MD5Utils;
import org.zyf.javabasic.workflowpipline.worker.complement.AbstractComplementWorker;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
/**
* @program: zyfboot-javabasic
* @description: 对数据内容进行拆段分析
* @author: zhangyanfeng
* @create: 2024-02-15 14:31
**/
@Slf4j
@WorkerInfo(name = "multiContentSplitWorker")
@Service
public class MultiContentSplitWorker extends AbstractComplementWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
// 抽取item
List<Item> items = getTypedItems(context, ItemType.NEWS.name());
if (CollectionUtils.isEmpty(items)) {
return context;
}
// 模拟:针对新闻容进行拆条处理
List<Item> needAddItems = Lists.newArrayList();
for (Item item : items) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("MultiContentSplitWorker Item data is null! item={}", item);
continue;
}
String content = data.getContent();
if (StringUtils.isBlank(content)) {
continue;
}
List<String> segments = new ContentSegmenter().segmentContent(content);
if (CollectionUtils.isEmpty(segments)) {
continue;
}
segments.stream().forEach(contentSeg -> {
Item newItem = new Item();
newItem.setItemId(item.getItemId());
newItem.setItemType(ItemType.NEWS_CONTENT_SUG.name());
newItem.setDynamicParams(item.getDynamicParams());
newItem.setExt(item.getExt());
newItem.setData(getNewKnowBaseModel(data, contentSeg));
needAddItems.add(newItem);
});
}
if (CollectionUtils.isEmpty(needAddItems)) {
return context;
}
context.getResult().getItems().addAll(needAddItems);
return context;
}
private KnowledgeMetadata getNewKnowBaseModel(KnowledgeMetadata curData, String contentSeg) {
KnowledgeMetadata newKnowBaseModel = KnowledgeMetadata.builder().build();
BeanUtils.copyProperties(curData, newKnowBaseModel);
newKnowBaseModel.setContentType(ItemType.NEWS_CONTENT_SUG.name());
newKnowBaseModel.setContent(contentSeg);
newKnowBaseModel.setUkId(curData.getUkId() + MD5Utils.md5(contentSeg).substring(0, 4));
newKnowBaseModel.setSplitType("content_ext");
return newKnowBaseModel;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
static class ContentSegmenter {
// 假设我们有一组关键短语来表示可能的新段落的开始
private static final String[] KEY_PHRASES = {
"此外", "另一方面", "接下来", "此外", "总之", "例如", "比如", "然而"
};
public static void main(String[] args) {
String content = "这是关于历史的部分。然而,现在我们转向科学。"
+ "关于科学的内容,我们可以看到以下事实。"
+ "此外,数学也很有趣。比如,让我们考虑以下问题。";
ContentSegmenter segmenter = new ContentSegmenter();
List<String> segments = segmenter.segmentContent(content);
for (int i = 0; i < segments.size(); i++) {
System.out.println("段落 " + (i + 1) + ": " + segments.get(i));
}
}
public List<String> segmentContent(String content) {
// 将内容分割成句子,这里简单使用句号作为分隔符
String[] sentences = content.split("\\. ");
List<String> segments = new ArrayList<>();
StringBuilder currentSegment = new StringBuilder();
for (String sentence : sentences) {
// 检查当前句子是否包含关键短语,如果是则开始一个新段落
if (containsKeyPhrase(sentence)) {
if (currentSegment.length() > 0) {
segments.add(currentSegment.toString());
currentSegment = new StringBuilder();
}
}
// 添加句子到当前段落
currentSegment.append(sentence).append(". ");
}
// 添加最后一个段落
if (currentSegment.length() > 0) {
segments.add(currentSegment.toString());
}
return segments;
}
private boolean containsKeyPhrase(String sentence) {
for (String phrase : KEY_PHRASES) {
if (sentence.contains(phrase)) {
return true;
}
}
return false;
}
}
}
智能AI赋能工作节点赋能
基类定义
package org.zyf.javabasic.workflowpipline.worker.aideal;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.zyf.javabasic.workflowpipline.core.BaseExecutorWorker;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import java.util.List;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: AI 基本分析处理
* @author: zhangyanfeng
* @create: 2024-02-15 10:19
**/
@Log4j2
public abstract class AbstractAIDealWorker extends BaseExecutorWorker {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context) {
if (CollectionUtils.isEmpty(context.getRequest().getItems())) {
log.info("AbstractAIDealWorker items is empty, game over");
return context;
}
return doWork(context);
}
/**
* 子类补全
*/
protected abstract WorkflowExecutionContext doWork(WorkflowExecutionContext context);
/**
* 根据类型拿到所有的item
*/
protected List<Item> getTypedItems(WorkflowExecutionContext context, String... itemType) {
return context.getResult().getItems().stream()
.filter((item) -> StringUtils.equalsAnyIgnoreCase(item.getItemType(), itemType))
.collect(Collectors.toList());
}
protected void addResult(WorkflowExecutionContext context, List<Item> typedItems) {
List<Item> resultItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(resultItems)) {
context.getResult().setItems(typedItems);
}
}
}
向量化智能生成
package org.zyf.javabasic.workflowpipline.worker.aideal;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import java.util.*;
/**
* @program: zyfboot-javabasic
* @description: 向量相关处理生成
* @author: zhangyanfeng
* @create: 2024-02-15 10:37
**/
@Slf4j
@WorkerInfo(name = "aIEmbeddingCreateWorker")
@Service
public class AIEmbeddingCreateWorker extends AbstractAIDealWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
//抽取item
List<Item> typedItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(typedItems)) {
return context;
}
//模拟:通过请求算法服务,根据当前标题和文本给出对应的关键词和实体词信息
for (Item item : typedItems) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
continue;
}
String title = data.getTitle();
if (StringUtils.isBlank(title)) {
continue;
}
//模拟:根据标题成对应的向量信息
data.setEmbedding(embedding(title));
item.setData(data);
}
context.getResult().setItems(typedItems);
return context;
}
private List<Double> embedding(String text) {
// 假设的词汇表,包含了所有可能的单词
final List<String> VOCABULARY = Arrays.asList(
"科学家", "发现", "新", "太阳", "系外", "行星", "地球", "液态", "水", "迹象", "国际货币基金组织", "报告", "新冠疫情", "冲击", "政治", "不稳定",
"全球", "经济", "增长率", "下调", "3.2%", "交易", "市场", "国际",
"投资", "影响", "经济学家", "政府", "措施", "经济衰退", "国家统计局",
"数据", "十年", "生育率", "下降", "跌至", "1.3", "人口", "更替",
"2.1", "政策", "制定者", "担忧", "推出", "鼓励", "生育", "育儿津贴",
"产假"
);
// 初始化向量
List<Double> vector = new ArrayList<>(Collections.nCopies(VOCABULARY.size(), 0.0));
// 分词(这里简化处理,实际应用应考虑更复杂的分词方法)
String[] words = text.split("\\s+|,|。|、");
// One-Hot编码,如果词汇表中包含单词,则相应位置为1.0,否则为0.0
for (String word : words) {
int index = VOCABULARY.indexOf(word);
if (index != -1) {
vector.set(index, 1.0);
}
}
return generateUniqueRandomDoubleList(8);
}
public List<Double> generateUniqueRandomDoubleList(int size) {
Random random = new Random();
Set<Double> uniqueNumbers = new HashSet<>();
// 继续生成随机数直到集合达到所需的大小
while (uniqueNumbers.size() < size) {
// 假设我们希望生成的随机数在0到100之间
double randomNumber = 100.0 * random.nextDouble();
uniqueNumbers.add(randomNumber);
}
// 将生成的随机数集合转换为列表
return new ArrayList<>(uniqueNumbers);
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
关键词实体词提炼
package org.zyf.javabasic.workflowpipline.worker.aideal;
import com.google.common.collect.Sets;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import org.zyf.javabasic.workflowpipline.model.common.WordDeal;
import java.util.*;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: 关键词实体词处理
* @author: zhangyanfeng
* @create: 2024-02-15 12:30
**/
@Slf4j
@WorkerInfo(name = "aIWordCreateWorker")
@Service
public class AIWordCreateWorker extends AbstractAIDealWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
//抽取item
List<Item> typedItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(typedItems)) {
return context;
}
//模拟:通过请求算法服务,根据当前标题和文本给出对应的关键词和实体词信息
for (Item item : typedItems) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
continue;
}
String title = data.getTitle();
String content = data.getContent();
//模拟:根据标题和内容生成对应的关键词和实体词
WordDeal info = getWordDealRes(title, content);
data.setKeyword(info.getKeyword());
data.setEntityWord(info.getEntityWord());
item.setData(data);
}
context.getResult().setItems(typedItems);
return context;
}
private WordDeal getWordDealRes(String title, String content) {
return WordDeal.builder()
.keyword(extractKeywords(title, content))
.entityWord(extractEntities(content)).build();
}
/**
* 生成关键词通常是通过自然语言处理(NLP)技术来实现的。在实际应用中涉及到文本分析、词频统计、词性标注、以及可能的机器学习模型。
* 在编程语言中,这通常需要依赖于专门的库来处理复杂的NLP任务。
* <p>
* 如果只是简单的关键词提取,可以考虑以下几个简易步骤:
* 分词:将文章标题和内容分割成单词或短语。
* 去除停用词:停用词是在文本处理中通常被忽略的词汇,如“的”、“和”、“在”等。
* 词频统计:统计每个单词的出现频率。
* 提取关键词:选择最频繁的词汇作为关键词。
* 下面基于Java的代码示例演示如何实现基本的关键词提取
*/
private List<String> extractKeywords(String title, String content) {
// 示例的停用词列表
final Set<String> STOP_WORDS = Sets.newHashSet("的", "和", "在", "是", "有", "我", "了", "不");
// 合并标题和内容
String fullText = title + " " + content;
// 正则表达式用于匹配非字母数字字符,用于分词
Pattern pattern = Pattern.compile("[^\\p{IsAlphabetic}\\p{IsDigit}]+");
// 分词并转为小写
List<String> words = Arrays.stream(pattern.split(fullText.toLowerCase()))
.filter(word -> !word.isEmpty() && !STOP_WORDS.contains(word)) // 过滤停用词和空字符串
.collect(Collectors.toList());
// 统计词频
Map<String, Long> frequencyMap = words.stream()
.collect(Collectors.groupingBy(word -> word, Collectors.counting()));
// 根据词频降序排序,提取关键词
List<String> keywords = frequencyMap.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.map(Map.Entry::getKey)
.collect(Collectors.toList());
return keywords;
}
/**
* 模拟一个非常基础的实体词识别器,用预定义列表中的实体与文本进行匹配
*/
private List<String> extractEntities(String text) {
// 模拟的实体列表
final List<String> PERSON_ENTITIES = Arrays.asList("张三", "李四", "王五", "天文学家", "经济学家", "政策制定者");
final List<String> LOCATION_ENTITIES = Arrays.asList("北京", "上海", "深圳", "地球");
final List<String> ORGANIZATION_ENTITIES = Arrays.asList("苹果公司", "谷歌", "微软", "国际货币基金组织", "国家统计局");
final List<String> ASTRONOMY_ENTITIES = Arrays.asList("系外行星", "红矮星", "K2-18b");
final List<String> ECONOMIC_INDICATORS = Arrays.asList("全球经济增长率", "生育率");
final List<String> NUMERIC_VALUES = Arrays.asList("3.2%", "1.3", "2.1");
final List<String> SOCIAL_CONCEPTS = Arrays.asList("新冠疫情", "经济衰退", "产假", "育儿津贴");
List<String> identifiedEntities = new ArrayList<>();
// 根据列表识别不同类型的实体
identifiedEntities.addAll(findEntitiesInText(text, PERSON_ENTITIES));
identifiedEntities.addAll(findEntitiesInText(text, LOCATION_ENTITIES));
identifiedEntities.addAll(findEntitiesInText(text, ORGANIZATION_ENTITIES));
identifiedEntities.addAll(findEntitiesInText(text, ASTRONOMY_ENTITIES));
identifiedEntities.addAll(findEntitiesInText(text, ECONOMIC_INDICATORS));
identifiedEntities.addAll(findEntitiesInText(text, NUMERIC_VALUES));
identifiedEntities.addAll(findEntitiesInText(text, SOCIAL_CONCEPTS));
return identifiedEntities;
}
// 一个辅助方法用来在文本中查找实体
private List<String> findEntitiesInText(String text, List<String> entities) {
List<String> foundEntities = new ArrayList<>();
for (String entity : entities) {
if (text.contains(entity)) {
foundEntities.add(entity);
}
}
return foundEntities;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}情绪分判定
package org.zyf.javabasic.workflowpipline.worker.aideal;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
/**
* @program: zyfboot-javabasic
* @description: 情绪分生成分析
* @author: zhangyanfeng
* @create: 2024-02-15 13:40
**/
@Slf4j
@WorkerInfo(name = "moodScoreCreateWorker")
@Service
public class MoodScoreCreateWorker extends AbstractAIDealWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
//抽取item
List<Item> typedItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(typedItems)) {
return context;
}
//模拟:通过请求算法服务,根据当前标题和文本给出对应的关键词和实体词信息
for (Item item : typedItems) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
continue;
}
String content = data.getContent();
if (StringUtils.isBlank(content)) {
continue;
}
//模拟:根据标题成对应的情绪分
data.setMoodScore(getSentimentScore(content));
item.setData(data);
}
context.getResult().setItems(typedItems);
return context;
}
private double getSentimentScore(String text) {
if (text == null || text.isEmpty()) {
return 0.0; // 文本为空时情绪分为0
}
final List<String> POSITIVE_WORDS = Arrays.asList(
"好", "出色", "快乐", "幸福", "赞", "发现", "可能存在生命"
);
final List<String> NEGATIVE_WORDS = Arrays.asList(
"坏", "糟糕", "悲伤", "愤怒", "批评", "冲击", "不稳定",
"下调", "影响", "衰退", "下降", "担忧"
);
double score = 0.0;
// 对于文本中的每个正面词,增加分数
for (String word : POSITIVE_WORDS) {
if (text.contains(word)) {
score += 1.0;
}
}
// 对于文本中的每个负面词,减少分数
for (String word : NEGATIVE_WORDS) {
if (text.contains(word)) {
score -= 1.0;
}
}
return score;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
质量分判定
package org.zyf.javabasic.workflowpipline.worker.aideal;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import java.util.List;
import java.util.Objects;
/**
* @program: zyfboot-javabasic
* @description: 文章质量评估
* @author: zhangyanfeng
* @create: 2024-02-15 13:41
**/
@Slf4j
@WorkerInfo(name = "qualityScoreCreateWorker")
@Service
public class QualityScoreCreateWorker extends AbstractAIDealWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
//抽取item
List<Item> typedItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(typedItems)) {
return context;
}
//模拟:通过请求算法服务,根据当前标题和文本给出对应的关键词和实体词信息
for (Item item : typedItems) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
continue;
}
String content = data.getContent();
if (StringUtils.isBlank(content)) {
continue;
}
//模拟:根据标题成对应的质量分
data.setQualityScore(getQualityScore(content));
item.setData(data);
}
context.getResult().setItems(typedItems);
return context;
}
private double getQualityScore(String articleContent) {
// 这里是一个非常简单的示例,实际的质量评分会更复杂
if (articleContent == null || articleContent.isEmpty()) {
return 0.0; // 空文章得分为0
}
double score = 5.0; // 基础分数
// 增加一些简单的规则来调整分数
if (StringUtils.containsAny(articleContent, "错误", "迹象", "不稳定", "担忧")) {
score -= 1.0; // 文章提到“错误”,分数减少
}
if (articleContent.length() > 76) {
score += 2.0; // 文章内容充实,分数增加
}
if (articleContent.length() < 80) {
score -= 2.0; // 文章内容太短,分数减少
}
// 确保分数在0到10之间
return Math.max(0, Math.min(score, 10));
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
时效性分析
package org.zyf.javabasic.workflowpipline.worker.aideal;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import java.time.Instant;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.List;
import java.util.Objects;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @program: zyfboot-javabasic
* @description: 时效性分析处理
* @author: zhangyanfeng
* @create: 2024-02-15 13:43
**/
@Slf4j
@WorkerInfo(name = "timeDealCreateWorker")
@Service
public class TimeDealCreateWorker extends AbstractAIDealWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doWork(WorkflowExecutionContext context) {
//抽取item
List<Item> typedItems = context.getResult().getItems();
if (CollectionUtils.isEmpty(typedItems)) {
return context;
}
//模拟:通过请求算法服务,根据当前标题和文本给出对应的关键词和实体词信息
for (Item item : typedItems) {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
continue;
}
//模拟:根据标题成对应的情绪分
ArticleTimeliness timeliness = new ArticleTimeliness(data.getGmtCreate());
// 分析文章中的时间表达式
timeliness.analyzeTimeExpressions(data.getTitle(), data.getContent());
data.setStartValidTs(timeliness.getStartValidTs());
data.setEndValidTs(timeliness.getEndValidTs());
data.setStartShownTs(timeliness.getStartShownTs());
data.setEndShownTs(timeliness.getEndShownTs());
item.setData(data);
}
context.getResult().setItems(typedItems);
return context;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
class ArticleTimeliness {
private Long startValidTs;
private Long endValidTs;
private Long startShownTs;
private Long endShownTs;
// 构造函数,初始化有效开始时间为文章发布时间
public ArticleTimeliness(Long publicationTimestamp) {
this.startValidTs = publicationTimestamp;
// 转换时间戳为LocalDateTime来增加一年时间,得到有效截止时间
LocalDateTime publicationDate = LocalDateTime.ofInstant(Instant.ofEpochMilli(publicationTimestamp), ZoneId.systemDefault());
this.endValidTs = publicationDate.plusYears(1).atZone(ZoneId.systemDefault()).toInstant().toEpochMilli();
}
// 从文章标题和内容中提取时间表达式并更新语义时间字段
public void analyzeTimeExpressions(String articleTitle, String articleContent) {
String combinedText = articleTitle + " " + articleContent;
// 正则表达式匹配简单的时间表达式(这里仅为示例,实际情况可能复杂得多)
// 匹配格式如“2023年3月5日”
Pattern pattern = Pattern.compile("\\d{4}年\\d{1,2}月\\d{1,2}日");
Matcher matcher = pattern.matcher(combinedText);
// 日期格式化器,假设日期格式为 "yyyy年MM月dd日"
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日");
while (matcher.find()) {
String dateStr = matcher.group();
if (startShownTs == null) {
// 如果开始语义时间还未设置,将它设置为第一个找到的时间
startShownTs = LocalDate.parse(dateStr, formatter).atStartOfDay(ZoneId.systemDefault()).toInstant().toEpochMilli();
} else {
// 如果开始语义时间已经设置,尝试更新截止语义时间
endShownTs = LocalDate.parse(dateStr, formatter).atStartOfDay(ZoneId.systemDefault()).toInstant().toEpochMilli();
}
}
}
public Long getStartValidTs() {
return startValidTs;
}
public Long getEndValidTs() {
return endValidTs;
}
public Long getStartShownTs() {
return startShownTs;
}
public Long getEndShownTs() {
return endShownTs;
}
}
}
内容安全工作节点赋能
基类定义
package org.zyf.javabasic.workflowpipline.worker.filter;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.zyf.javabasic.workflowpipline.constants.PipelineConstant;
import org.zyf.javabasic.workflowpipline.core.BaseExecutorWorker;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import java.util.List;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: 内容过滤处理分析基类
* @author: zhangyanfeng
* @create: 2024-02-15 13:51
**/
@Slf4j
public abstract class AbstractFilterWorker extends BaseExecutorWorker {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context) {
if (CollectionUtils.isEmpty(context.getRequest().getItems())) {
log.info("AbstractFilterWorker items is empty, skip filter,return");
return context;
}
List<Item> filterPreItems = context.getResult().getItems();
doFilter(context);
List<Item> filterAfterItems = context.getResult().getItems();
logFilterItem(filterPreItems, filterAfterItems);
if (CollectionUtils.isEmpty(filterAfterItems)) {
context.setContextAttr(PipelineConstant.PIPELINE_FOECE_BREAK, "true");
}
return context;
}
/**
* 具体过滤逻辑
*/
protected abstract WorkflowExecutionContext doFilter(WorkflowExecutionContext context);
/**
* 打印过滤item信息
*/
private void logFilterItem(List<Item> filterPreItems, List<Item> filterAfterItems) {
List<String> filterItems = filterPreItems.stream()
.filter(item -> !filterAfterItems.contains(item))
.map(item -> item.getItemType() + ":" + item.getItemId())
.collect(Collectors.toList());
log.info("AbstractFilterWorker|worker={}|size={}|filterId={}|", this.getName(), filterItems.size(), String.join(",", filterItems));
}
}
敏感词内容过滤
package org.zyf.javabasic.workflowpipline.worker.filter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import java.util.HashSet;
import java.util.List;
import java.util.Objects;
import java.util.Set;
import java.util.stream.Collectors;
/**
* @program: zyfboot-javabasic
* @description: 敏感词内容过滤
* @author: zhangyanfeng
* @create: 2024-02-15 13:53
**/
@Slf4j
@WorkerInfo(name = "sensitiveContentFilterWorker")
@Service
public class SensitiveContentFilterWorker extends AbstractFilterWorker implements InitializingBean {
@Override
protected WorkflowExecutionContext doFilter(WorkflowExecutionContext context) {
List<Item> items = context.getResult().getItems();
// 过滤后的结果
List<Item> result = items.stream()
.filter(item -> {
KnowledgeMetadata data = Item.getData(item.getData(), KnowledgeMetadata.class);
if (Objects.isNull(data)) {
log.warn("AIWordCreateWorker Item data is null! item={}", item);
return false;
}
return !containsSensitiveWords(data.getTitle(), data.getContent());
})
.collect(Collectors.toList());
context.getResult().setItems(result);
return context;
}
public boolean containsSensitiveWords(String articleTitle, String articleContent) {
Set<String> sensitiveWords = new HashSet<>();
// 假设这是我们的敏感词列表
sensitiveWords.add("敏感词1");
sensitiveWords.add("敏感词2");
for (String word : sensitiveWords) {
if (articleTitle.contains(word) || articleContent.contains(word)) {
return true;
}
}
return false;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
数据落库工作节点赋能
基类定义
package org.zyf.javabasic.workflowpipline.worker.sink;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang.StringUtils;
import org.zyf.javabasic.workflowpipline.core.BaseExecutorWorker;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 内容落库处理
* @author: zhangyanfeng
* @create: 2024-02-15 14:09
**/
@Slf4j
public abstract class AbstractSinkWorker extends BaseExecutorWorker {
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context, String uniqueId) {
List<Item> items = context.getResult().getItems();
if (CollectionUtils.isEmpty(items)) {
log.info(getName() + " items is empty");
return context;
}
boolean success = sink(context, uniqueId);
log.info(getName() + " sink success:" + success);
return context;
}
@Override
public WorkflowExecutionContext work(WorkflowExecutionContext context) {
return work(context, StringUtils.EMPTY);
}
/**
* 子类实现插入不同数据库
*/
protected boolean sink(WorkflowExecutionContext context, String uniqueId) {
return sink(context);
}
protected abstract boolean sink(WorkflowExecutionContext context);
}数据同步到doris
package org.zyf.javabasic.workflowpipline.worker.sink;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
/**
* @program: zyfboot-javabasic
* @description: 数据同步到doris
* @author: zhangyanfeng
* @create: 2024-02-15 14:15
**/
@Log4j2
@WorkerInfo(name = "dorisSinkWorker")
@Service
public class DorisSinkWorker extends AbstractSinkWorker implements InitializingBean {
@Override
protected boolean sink(WorkflowExecutionContext context, String uniqueId) {
log.info("数据已经落入doris");
// dorisSinkService.sink(context, getName(), tableName);
return true;
}
@Override
protected boolean sink(WorkflowExecutionContext context) {
return sink(context, "");
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}数据同步到ES
package org.zyf.javabasic.workflowpipline.worker.sink;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
/**
* @program: zyfboot-javabasic
* @description: 数据同步到ES
* @author: zhangyanfeng
* @create: 2024-02-15 14:17
**/
@Log4j2
@WorkerInfo(name = "elasticsearchSinkWorker")
@Service
public class ElasticsearchSinkWorker extends AbstractSinkWorker implements InitializingBean {
/**
* 默认测试表
*/
static final String DEFAULT_INDEX = "zyf_test";
@Override
protected boolean sink(WorkflowExecutionContext context) {
String index;
if (context.getRequest().isTestData()) {
//测试数据写入 alias_real_time_task_test表
index = context.getBizWorkflowConfig("", DEFAULT_INDEX);
log.info("ElasticsearchSinkWorker test index={}", index);
} else {
index = context.getBizWorkflowConfig("");
}
// 插入/更新
//sinkESService.sink(context, getName(), index);
log.info("数据已经落入es");
return true;
}
@Override
protected boolean sink(WorkflowExecutionContext context, String uniqueId) {
String index;
if (context.getRequest().isTestData()) {
index = context.getBizWorkflowConfig("", DEFAULT_INDEX, uniqueId);
log.info("ElasticsearchSinkWorker test index={}", index);
} else {
index = context.getSceneConfigWithIdentifier("", uniqueId);
}
// 插入/更新
// sinkESService.sink(context, getName(), index);
log.info("数据已经落入es");
return true;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
数据同步到HBase
package org.zyf.javabasic.workflowpipline.worker.sink;
import lombok.extern.log4j.Log4j2;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;
import org.zyf.javabasic.workflowpipline.annotations.WorkerInfo;
import org.zyf.javabasic.workflowpipline.core.Workflow;
import org.zyf.javabasic.workflowpipline.core.WorkflowExecutionContext;
/**
* @program: zyfboot-javabasic
* @description: 数据同步到HBase
* @author: zhangyanfeng
* @create: 2024-02-15 14:18
**/
@Log4j2
@WorkerInfo(name = "hbaseSinkWorker")
@Service
public class HbaseSinkWorker extends AbstractSinkWorker implements InitializingBean {
@Override
protected boolean sink(WorkflowExecutionContext context) {
log.info("数据已经落入hbase");
return false;
}
@Override
public void afterPropertiesSet() throws Exception {
Workflow.registerWorker(getName(), this);
}
}
(四)验证分析
按以上基本定义,书写测试类如下:
package org.zyf.javabasic.workflowpipline.service;
import com.alibaba.fastjson.JSON;
import com.google.common.collect.Lists;
import lombok.extern.log4j.Log4j2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import org.zyf.javabasic.ZYFApplication;
import org.zyf.javabasic.workflowpipline.constants.PipelineConstant;
import org.zyf.javabasic.workflowpipline.dataprocess.Item;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowRequest;
import org.zyf.javabasic.workflowpipline.dataprocess.WorkflowResult;
import org.zyf.javabasic.workflowpipline.enums.ItemType;
import org.zyf.javabasic.workflowpipline.model.KnowledgeMetadata;
import javax.annotation.Resource;
import java.util.List;
/**
* @program: zyfboot-javabasic
* @description: 测试动态执行工作引擎
* @author: zhangyanfeng
* @create: 2024-02-15 14:41
**/
@Log4j2
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ZYFApplication.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class BizWorkflowExecutorTest {
@Resource
private BizWorkflowExecutor bizWorkflowExecutor;
@Test
public void testProcessPipelineExecutor() {
Item newItem = new Item();
newItem.setItemId("1111111111111");
newItem.setItemType(ItemType.NEWS.name());
KnowledgeMetadata testData = KnowledgeMetadata.builder()
.id("1111111111111")
.contentType(ItemType.NEWS.name())
.gmtCreate(1706861925016L).build();
newItem.setData(testData);
List<Item> items = Lists.newArrayList(newItem);
WorkflowRequest request = new WorkflowRequest();
request.setScene("ZYF_TEST_SCENE");
request.setTestData(true);
request.setItems(items);
request.setExt(PipelineConstant.PIPELINE_CONFIG, "initCheckWorker,newsComplementWorker,multiContentSplitWorker," +
"aIWordCreateWorker,moodScoreCreateWorker,qualityScoreCreateWorker,timeDealCreateWorker,aIEmbeddingCreateWorker," +
"sensitiveContentFilterWorker,elasticsearchSinkWorker,dorisSinkWorker,hbaseSinkWorker");
WorkflowResult workflowResult = bizWorkflowExecutor.startDynamicExecution(request);
log.info("SceneProcessServiceTest request={}\n,processResult={}", JSON.toJSONString(request), JSON.toJSONString(workflowResult));
}
}验证结果如下:
{
"items":[
{
"data":{
"author":"张彦峰",
"content":"近日,天文学家在距离地球仅40光年的系外行星上发现了液态水的迹象,这颗行星围绕一颗红矮星运行,被命名为“K2-18b”。科学家认为这颗行星上可能存在生命。",
"contentLength":77,
"contentType":"NEWS",
"embedding":[
39.98789033878333,
84.12862572518468,
85.71827215476029,
36.04847828297135,
62.19531600889984,
4.642137614229558,
54.755882150549255,
48.884138425996184
],
"endValidTs":1733020432000,
"entityWord":[
"天文学家",
"地球",
"系外行星",
"红矮星",
"K2-18b"
],
"extInfo":"NewExtInfo[category=科技,tags=[太空, 发现, 外星生命],imageUrl=http://example.com/news/k2-18b.png,videoUrl=http://example.com/news/k2-18b.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1701398032000,
"gmtModified":1701399412000,
"id":"-8904604984625147944",
"keyword":[
"天文学家在距离地球仅40光年的系外行星上发现了液态水的迹象",
"近日",
"k2",
"被命名为",
"这颗行星围绕一颗红矮星运行",
"科学家发现新的太阳系外行星",
"18b",
"科学家认为这颗行星上可能存在生命"
],
"moodScore":2,
"processType":"FINAI",
"qualityScore":4,
"splitType":"st",
"startValidTs":1701398032000,
"status":"OFFLINE",
"summary":"科学家宣布在距离地球不远的星系中发现了一颗可能适宜生命存在的行星。",
"title":"科学家发现新的太阳系外行星",
"titleLength":13,
"ukId":"news_-8904604984625147944"
},
"itemId":"-8904604984625147944",
"itemType":"NEWS"
},
{
"data":{
"author":"张彦峰",
"content":"根据国际货币基金组织的最新报告,由于新冠疫情的不断冲击和多地区的政治不稳定,全球经济增长率预期被下调至3.2%。这一情况对交易市场和国际投资产生了影响,许多经济学家呼吁各国政府采取措施以避免经济衰退。",
"contentLength":100,
"contentType":"NEWS",
"embedding":[
63.85237634128891,
25.962513217591933,
54.86696706029298,
53.63716805815274,
3.1111754698535665,
95.15671397454307,
12.636223990773331,
51.353342787418434
],
"endValidTs":1738983412000,
"entityWord":[
"经济学家",
"国际货币基金组织",
"全球经济增长率",
"3.2%",
"新冠疫情",
"经济衰退"
],
"extInfo":"NewExtInfo[category=经济,tags=[全球经济, IMF, 增长预期],imageUrl=http://example.com/news/economic-outlook.png,videoUrl=http://example.com/news/economic-outlook.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1707361012000,
"gmtModified":1707367616000,
"id":"6970666909287614189",
"keyword":[
"2",
"全球经济面临挑战",
"国际货币基金组织下调增长预期",
"许多经济学家呼吁各国政府采取措施以避免经济衰退",
"根据国际货币基金组织的最新报告",
"由于新冠疫情的不断冲击和多地区的政治不稳定",
"全球经济增长率预期被下调至3",
"这一情况对交易市场和国际投资产生了影响"
],
"moodScore":-5,
"processType":"FINAI",
"qualityScore":6,
"splitType":"st",
"startValidTs":1707361012000,
"status":"OFFLINE",
"summary":"面对持续的疫情影响和地缘政治紧张,国际货币基金组织调低了全球经济增长的预期。",
"title":"全球经济面临挑战,国际货币基金组织下调增长预期",
"titleLength":23,
"ukId":"news_6970666909287614189"
},
"itemId":"6970666909287614189",
"itemType":"NEWS"
},
{
"data":{
"author":"张彦峰",
"content":"据国家统计局的数据显示,过去十年间,国家的生育率呈持续下降趋势。目前,生育率已跌至1.3,远低于维持人口更替水平的2.1。此现象引发了政策制定者的担忧,他们正在考虑推出一系列措施来鼓励生育,包括提高育儿津贴、延长产假等。",
"contentLength":110,
"contentType":"NEWS",
"embedding":[
98.53678350897746,
5.927960129333432,
30.466035737677355,
81.13587736888547,
99.51926560233684,
99.85587461826823,
91.8838481355491,
59.828212370496836
],
"endValidTs":1738990016000,
"entityWord":[
"政策制定者",
"国家统计局",
"生育率",
"1.3",
"2.1",
"产假",
"育儿津贴"
],
"extInfo":"NewExtInfo[category=社会,tags=[生育率, 人口政策, 统计数据],imageUrl=http://example.com/news/fertility-rate.png,videoUrl=http://example.com/news/fertility-rate.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1707367616000,
"gmtModified":1707378416000,
"id":"-6278401618287950922",
"keyword":[
"他们正在考虑推出一系列措施来鼓励生育",
"国家统计局数据显示",
"过去十年间",
"远低于维持人口更替水平的2",
"国家的生育率呈持续下降趋势",
"包括提高育儿津贴",
"1",
"目前",
"延长产假等",
"3",
"生育率已跌至1",
"据国家统计局的数据显示",
"生育率持续下降引发关注",
"此现象引发了政策制定者的担忧"
],
"moodScore":-2,
"processType":"FINAI",
"qualityScore":6,
"splitType":"st",
"startValidTs":1707367616000,
"status":"OFFLINE",
"summary":"最新统计数据揭示,国家生育率继续下降,引起政策制定者和学者的广泛关注。",
"title":"国家统计局数据显示,生育率持续下降引发关注",
"titleLength":21,
"ukId":"news_-6278401618287950922"
},
"itemId":"-6278401618287950922",
"itemType":"NEWS"
},
{
"data":{
"author":"张彦峰",
"content":"近日,天文学家在距离地球仅40光年的系外行星上发现了液态水的迹象,这颗行星围绕一颗红矮星运行,被命名为“K2-18b”。科学家认为这颗行星上可能存在生命。. ",
"contentLength":77,
"contentType":"NEWS_CONTENT_SUG",
"embedding":[
95.42397419927094,
98.37348767750565,
4.0665137546073815,
38.79405288389508,
81.9156575651701,
84.6948696337797,
65.76966369628316,
26.453695305048885
],
"endValidTs":1733020432000,
"entityWord":[
"天文学家",
"地球",
"系外行星",
"红矮星",
"K2-18b"
],
"extInfo":"NewExtInfo[category=科技,tags=[太空, 发现, 外星生命],imageUrl=http://example.com/news/k2-18b.png,videoUrl=http://example.com/news/k2-18b.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1701398032000,
"gmtModified":1701399412000,
"id":"-8904604984625147944",
"keyword":[
"天文学家在距离地球仅40光年的系外行星上发现了液态水的迹象",
"近日",
"k2",
"被命名为",
"这颗行星围绕一颗红矮星运行",
"科学家发现新的太阳系外行星",
"18b",
"科学家认为这颗行星上可能存在生命"
],
"moodScore":2,
"processType":"FINAI",
"qualityScore":4,
"splitType":"content_ext",
"startValidTs":1701398032000,
"status":"OFFLINE",
"summary":"科学家宣布在距离地球不远的星系中发现了一颗可能适宜生命存在的行星。",
"title":"科学家发现新的太阳系外行星",
"titleLength":13,
"ukId":"news_-890460498462514794414be"
},
"itemId":"-8904604984625147944",
"itemType":"NEWS_CONTENT_SUG"
},
{
"data":{
"author":"张彦峰",
"content":"根据国际货币基金组织的最新报告,由于新冠疫情的不断冲击和多地区的政治不稳定,全球经济增长率预期被下调至3.2%。这一情况对交易市场和国际投资产生了影响,许多经济学家呼吁各国政府采取措施以避免经济衰退。. ",
"contentLength":100,
"contentType":"NEWS_CONTENT_SUG",
"embedding":[
63.27055189462071,
21.961341646965792,
4.630136714552213,
40.011880497068454,
76.0783628435717,
4.190285748876055,
43.34669070849731,
11.537776457888116
],
"endValidTs":1738983412000,
"entityWord":[
"经济学家",
"国际货币基金组织",
"全球经济增长率",
"3.2%",
"新冠疫情",
"经济衰退"
],
"extInfo":"NewExtInfo[category=经济,tags=[全球经济, IMF, 增长预期],imageUrl=http://example.com/news/economic-outlook.png,videoUrl=http://example.com/news/economic-outlook.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1707361012000,
"gmtModified":1707367616000,
"id":"6970666909287614189",
"keyword":[
"2",
"全球经济面临挑战",
"国际货币基金组织下调增长预期",
"许多经济学家呼吁各国政府采取措施以避免经济衰退",
"根据国际货币基金组织的最新报告",
"由于新冠疫情的不断冲击和多地区的政治不稳定",
"全球经济增长率预期被下调至3",
"这一情况对交易市场和国际投资产生了影响"
],
"moodScore":-5,
"processType":"FINAI",
"qualityScore":6,
"splitType":"content_ext",
"startValidTs":1707361012000,
"status":"OFFLINE",
"summary":"面对持续的疫情影响和地缘政治紧张,国际货币基金组织调低了全球经济增长的预期。",
"title":"全球经济面临挑战,国际货币基金组织下调增长预期",
"titleLength":23,
"ukId":"news_6970666909287614189ac28"
},
"itemId":"6970666909287614189",
"itemType":"NEWS_CONTENT_SUG"
},
{
"data":{
"author":"张彦峰",
"content":"据国家统计局的数据显示,过去十年间,国家的生育率呈持续下降趋势。目前,生育率已跌至1.3,远低于维持人口更替水平的2.1。此现象引发了政策制定者的担忧,他们正在考虑推出一系列措施来鼓励生育,包括提高育儿津贴、延长产假等。. ",
"contentLength":110,
"contentType":"NEWS_CONTENT_SUG",
"embedding":[
20.973890401789973,
29.135271054529532,
25.346375169860135,
76.08391654725041,
43.01523963713163,
57.8513799448355,
70.78231441778235,
25.28356841684827
],
"endValidTs":1738990016000,
"entityWord":[
"政策制定者",
"国家统计局",
"生育率",
"1.3",
"2.1",
"产假",
"育儿津贴"
],
"extInfo":"NewExtInfo[category=社会,tags=[生育率, 人口政策, 统计数据],imageUrl=http://example.com/news/fertility-rate.png,videoUrl=http://example.com/news/fertility-rate.mp4,isPrivate=false,viewableBy=[all]]",
"gmtCreate":1707367616000,
"gmtModified":1707378416000,
"id":"-6278401618287950922",
"keyword":[
"他们正在考虑推出一系列措施来鼓励生育",
"国家统计局数据显示",
"过去十年间",
"远低于维持人口更替水平的2",
"国家的生育率呈持续下降趋势",
"包括提高育儿津贴",
"1",
"目前",
"延长产假等",
"3",
"生育率已跌至1",
"据国家统计局的数据显示",
"生育率持续下降引发关注",
"此现象引发了政策制定者的担忧"
],
"moodScore":-2,
"processType":"FINAI",
"qualityScore":6,
"splitType":"content_ext",
"startValidTs":1707367616000,
"status":"OFFLINE",
"summary":"最新统计数据揭示,国家生育率继续下降,引起政策制定者和学者的广泛关注。",
"title":"国家统计局数据显示,生育率持续下降引发关注",
"titleLength":21,
"ukId":"news_-62784016182879509223bfe"
},
"itemId":"-6278401618287950922",
"itemType":"NEWS_CONTENT_SUG"
}
]
}四、总结
本文详细介绍了如何设计和实现一个动态配置执行工作流引擎,并通过实际业务场景的分析,阐述了这一引擎在提升业务流程自动化、灵活性和可扩展性方面的重要性。在构建工作流引擎时,我们从核心模块的设计入手,包括工作流执行上下文、节点定义、任务执行器、调度平台等关键组成部分。特别是通过动态配置和执行机制,我们能够在不同的业务场景下灵活调整工作流的执行方式,提高系统对变化需求的适应能力。
在实际应用中,动态配置的优势不仅表现在流程执行的灵活性上,还在于如何通过配置化管理业务逻辑,使得系统的维护和扩展变得更加高效。此外,文章中的工作流示例展示了如何将智能化技术(如AI赋能和数据处理)融入工作流执行中,进一步增强了工作流引擎的业务价值。
尽管本文已经涵盖了工作流引擎设计的主要内容,但仍有许多可以深入探讨和优化的空间,例如更加精细的错误处理机制、动态调度算法的优化等。在未来的工作中,我们可以继续探索如何进一步提升工作流引擎的性能,增强其对高并发和大规模数据的支持能力。
希望通过这篇文章,读者能够对动态配置执行工作流引擎的设计理念和实现方式有更深入的理解,并能根据自己的业务需求,灵活调整和应用这一技术,推动企业数字化转型和流程自动化的落地实施。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











