










一、Hive 部署
(一)Linux 环境搭建
一、虚拟机的安装
二、Linux 系统安装
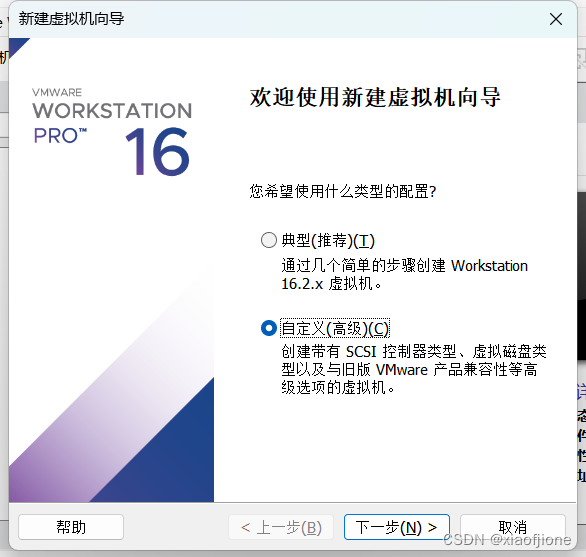
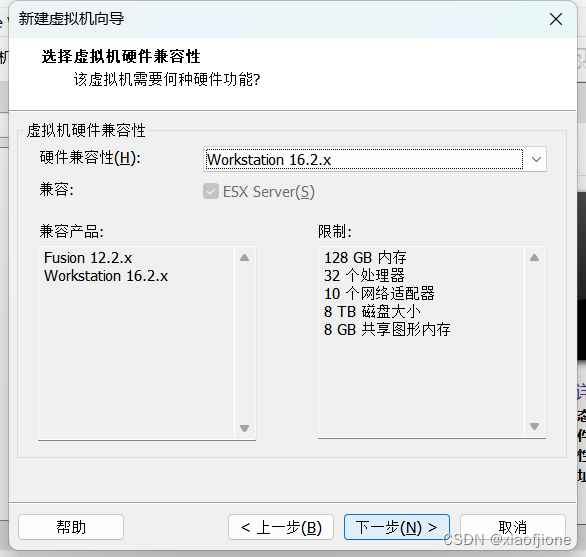
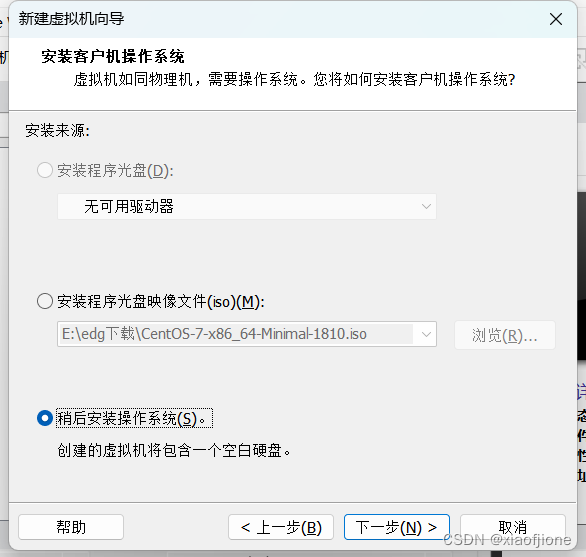
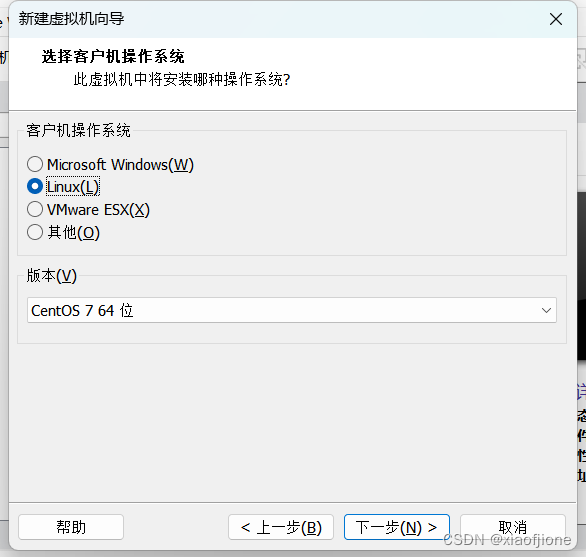
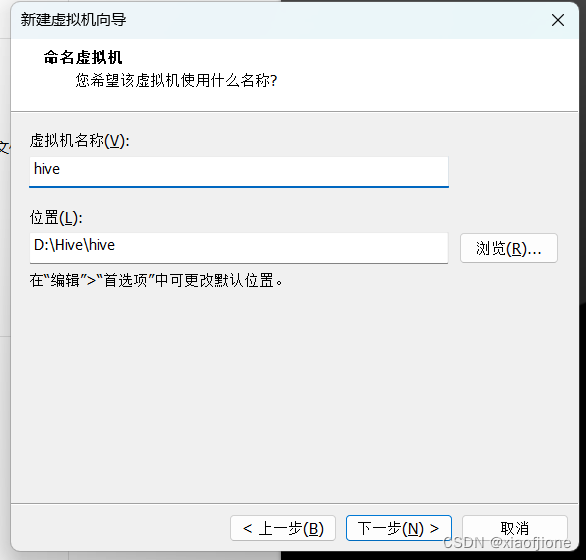
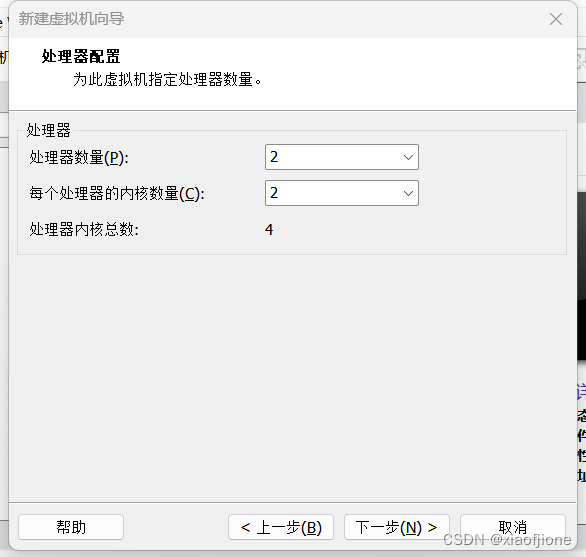
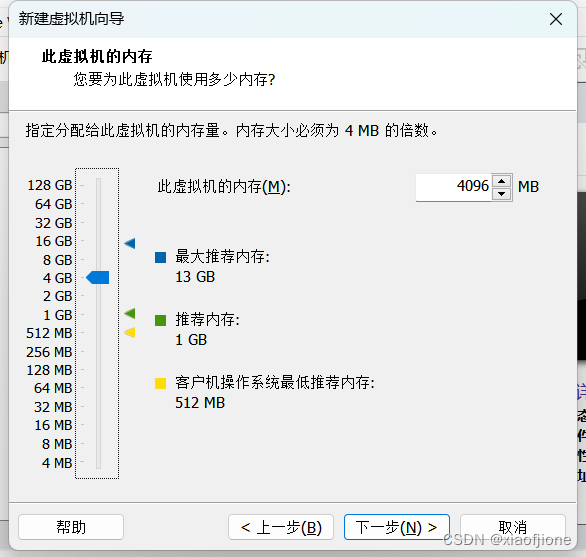
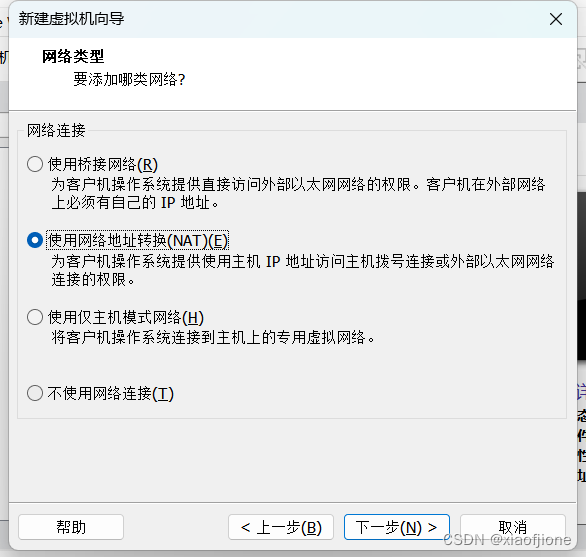
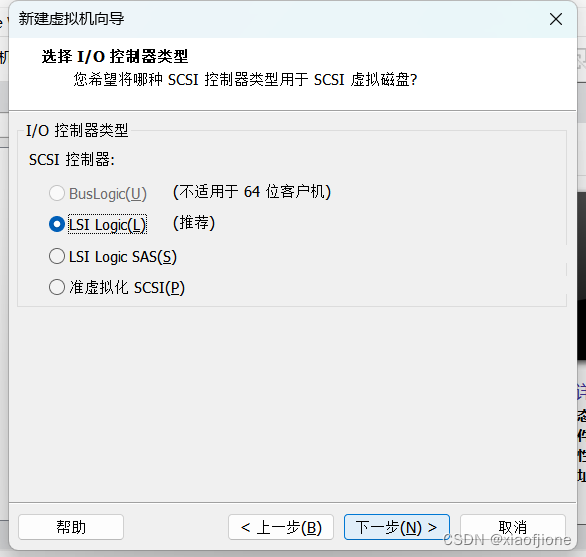
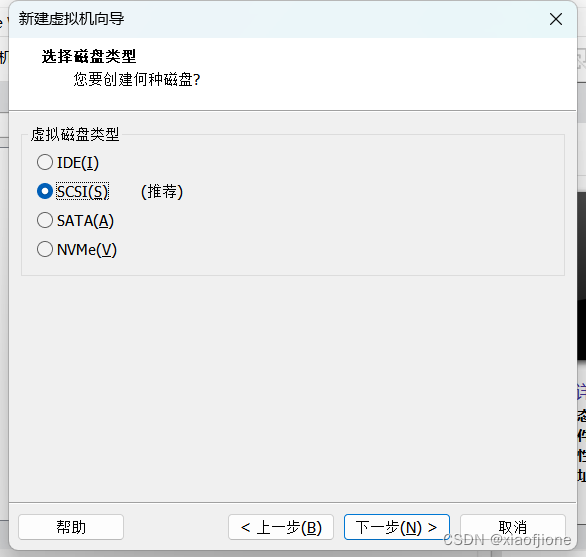
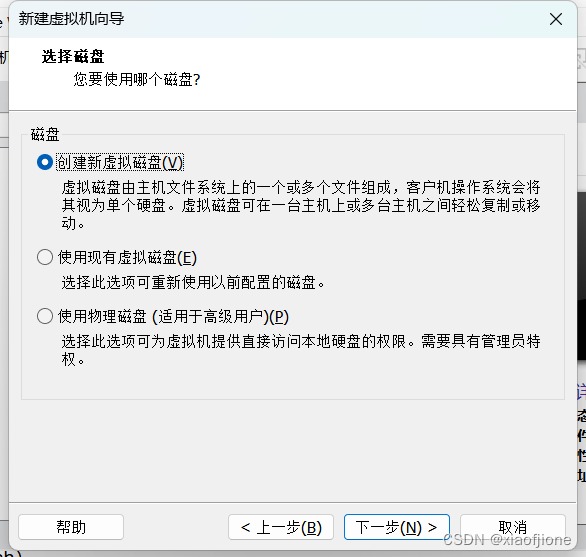

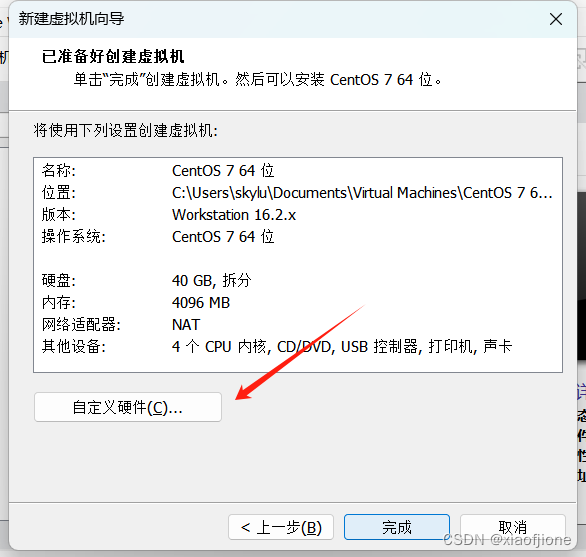
三、Centos 系统安装

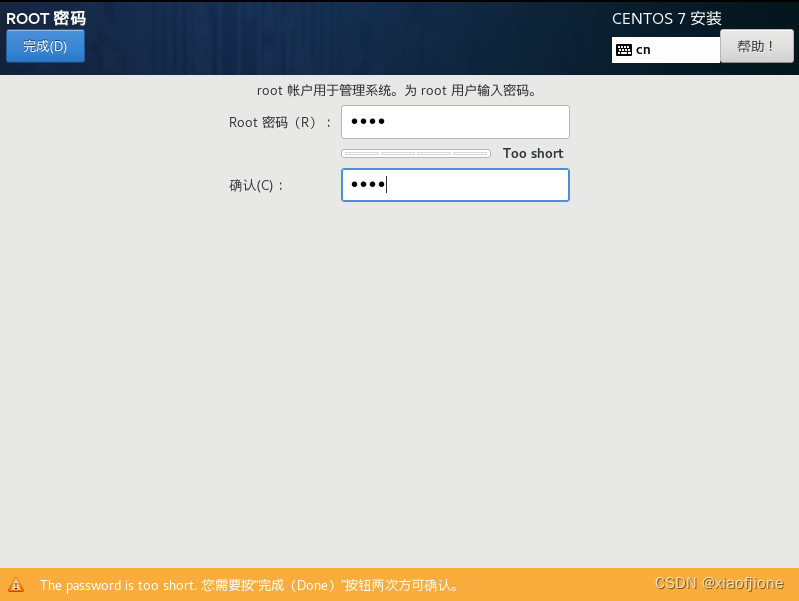
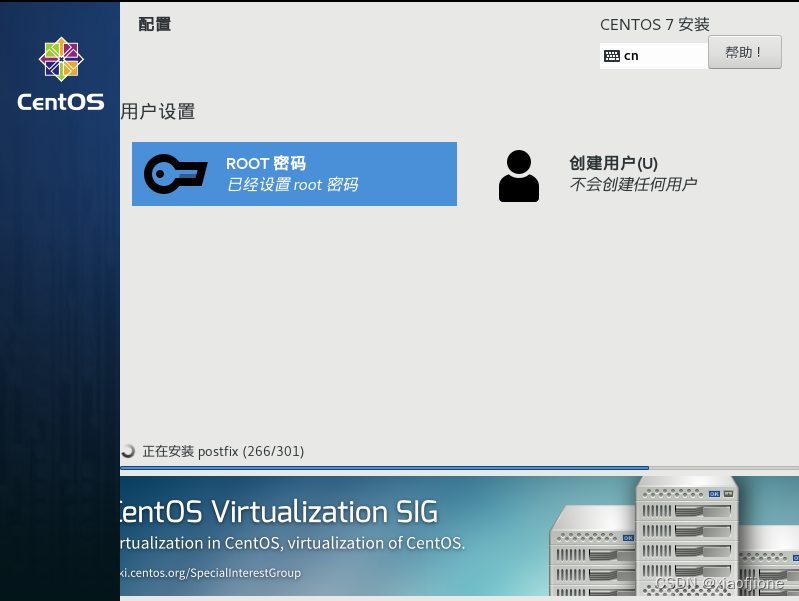
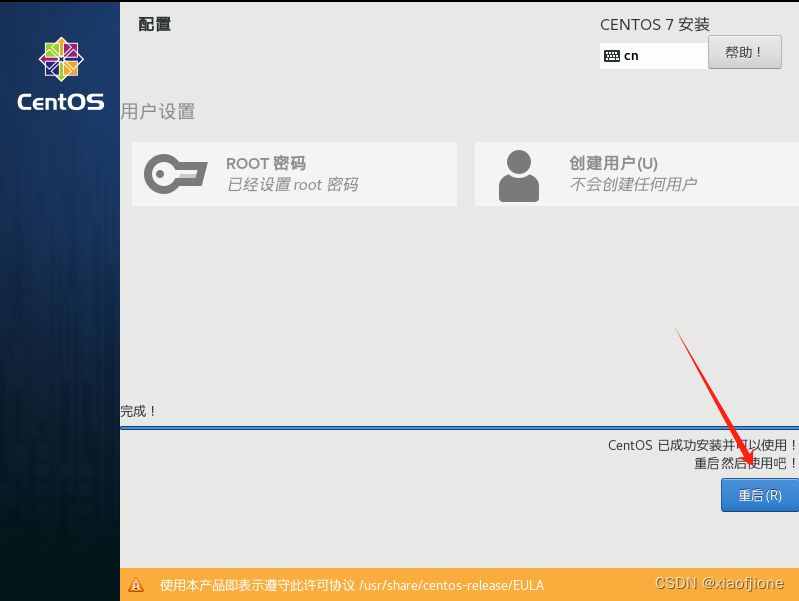

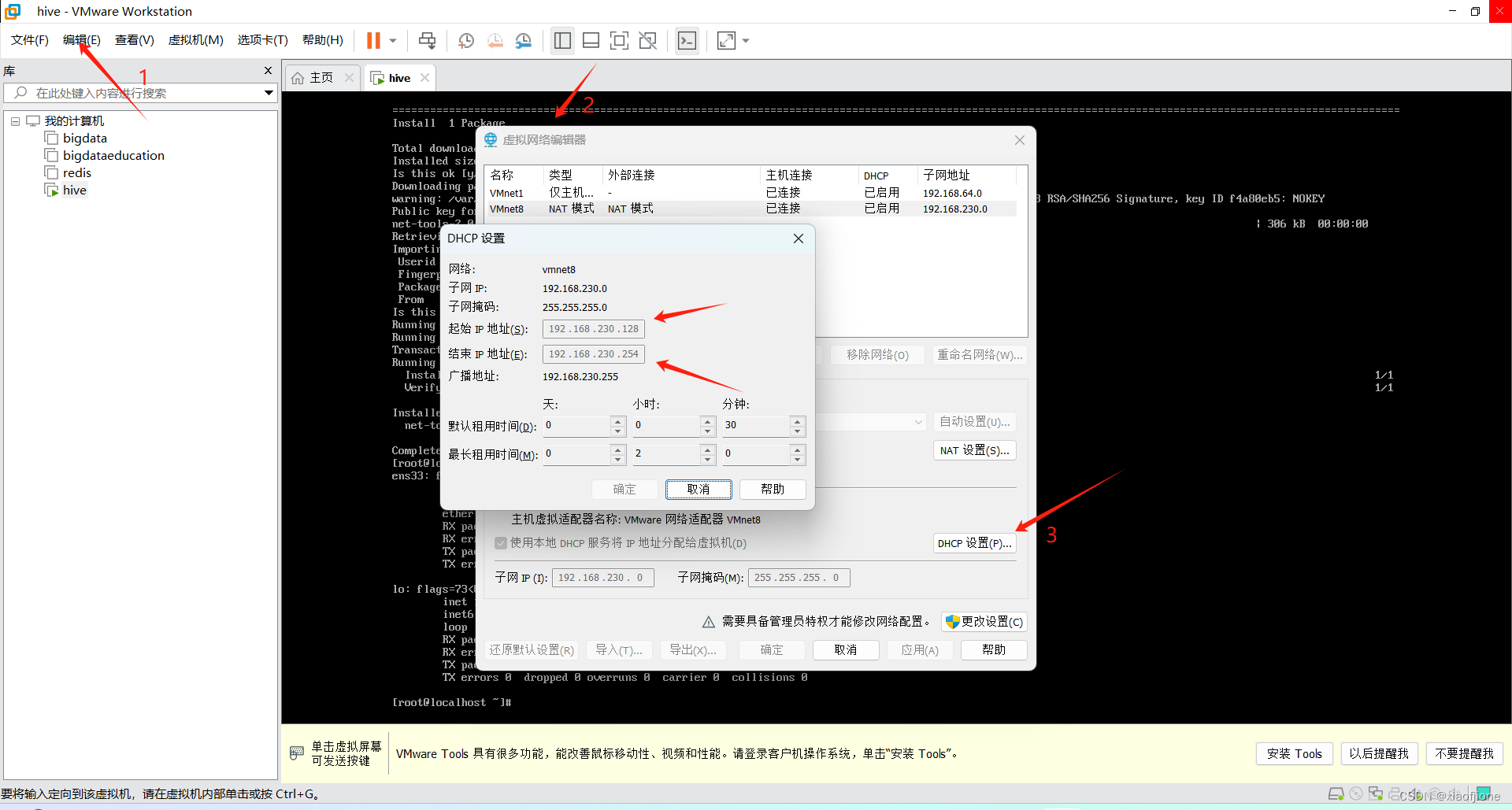
四、静态网络配置
ping www.baidu.comyum upgrade
yum install net-toolsifconfip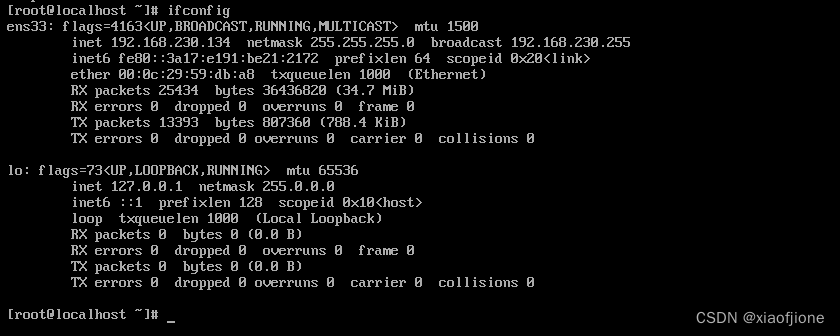
vi /etc/sysconfig/network-scripts/ifcfg-ens33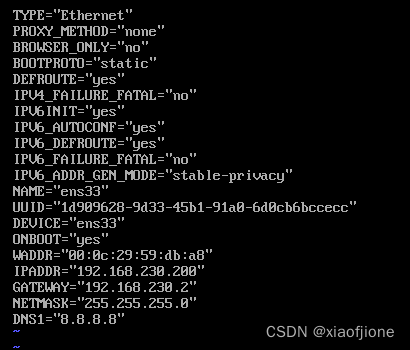
systemctl restart network
ping www.baidu.com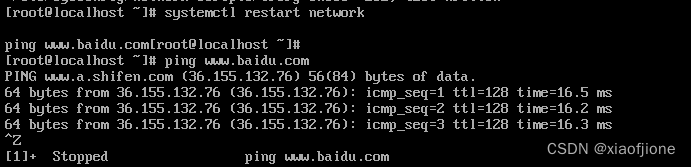
7.重启虚拟机后,查看是否连通网络(ip 地址并未改变,且能连通网络)
reboot
ifconfig
ping www.baidu.com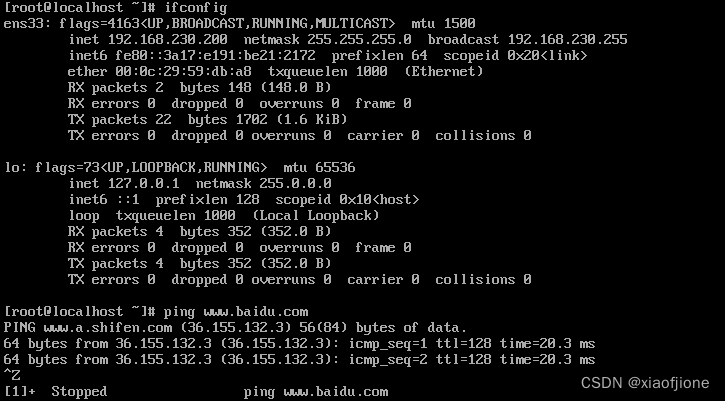
五、虚拟配置
(一)X-Shell远程连接Linux
1.新建会话连接
2.设置名称主机
3.设置用户身份认证(Linux的账号 密码 )
4.连接成功
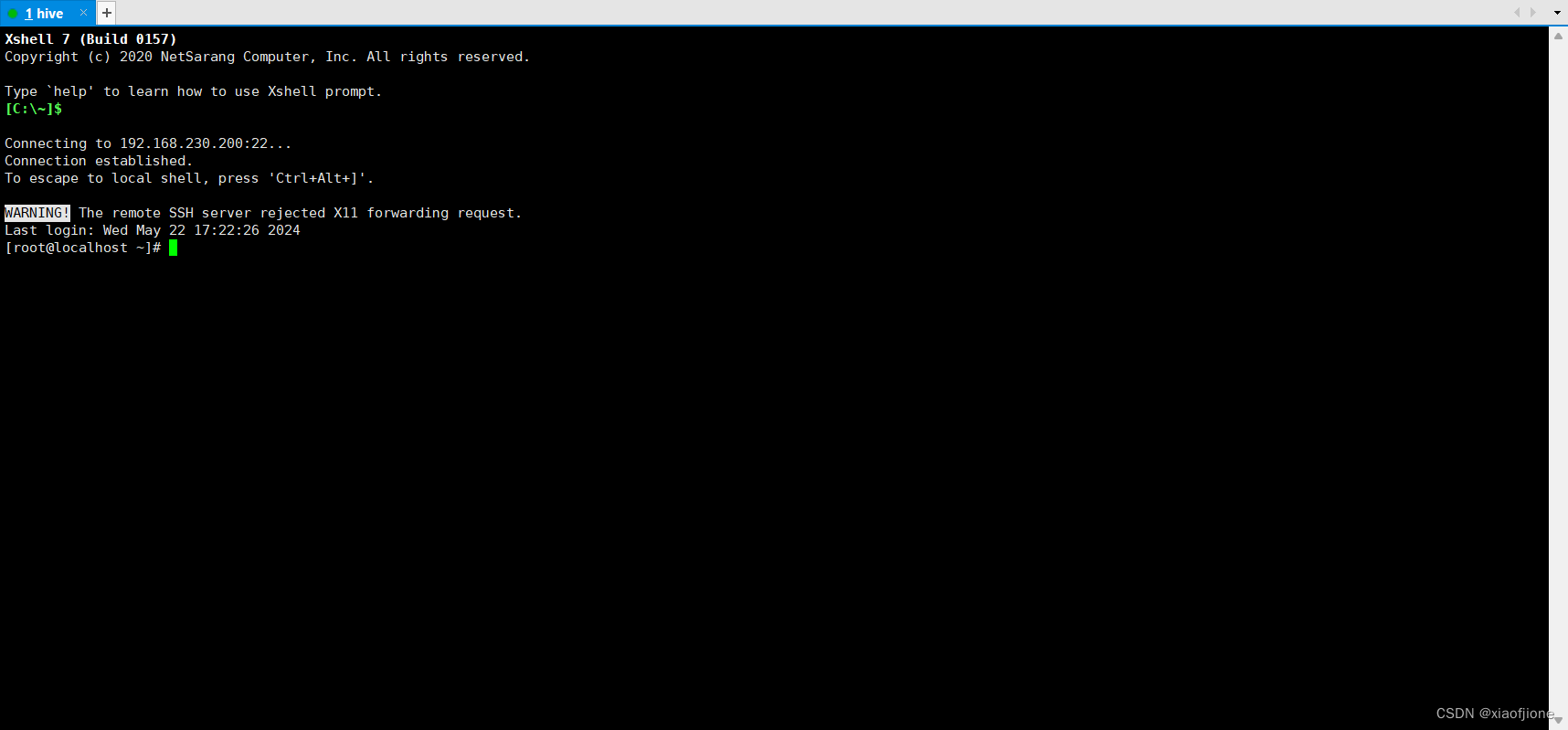
(二)Hadoop 的部署
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software
cd /export/software
yum -y install lrzsz
rz
4.ls查看安装包是否导入

5.安装 JDK(所有虚拟机都要操作)
cd /export/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/cd /export/servers
mv jdk1.8.0_161 jdkvi /etc/profile
#tip:在配置文件末尾追加
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar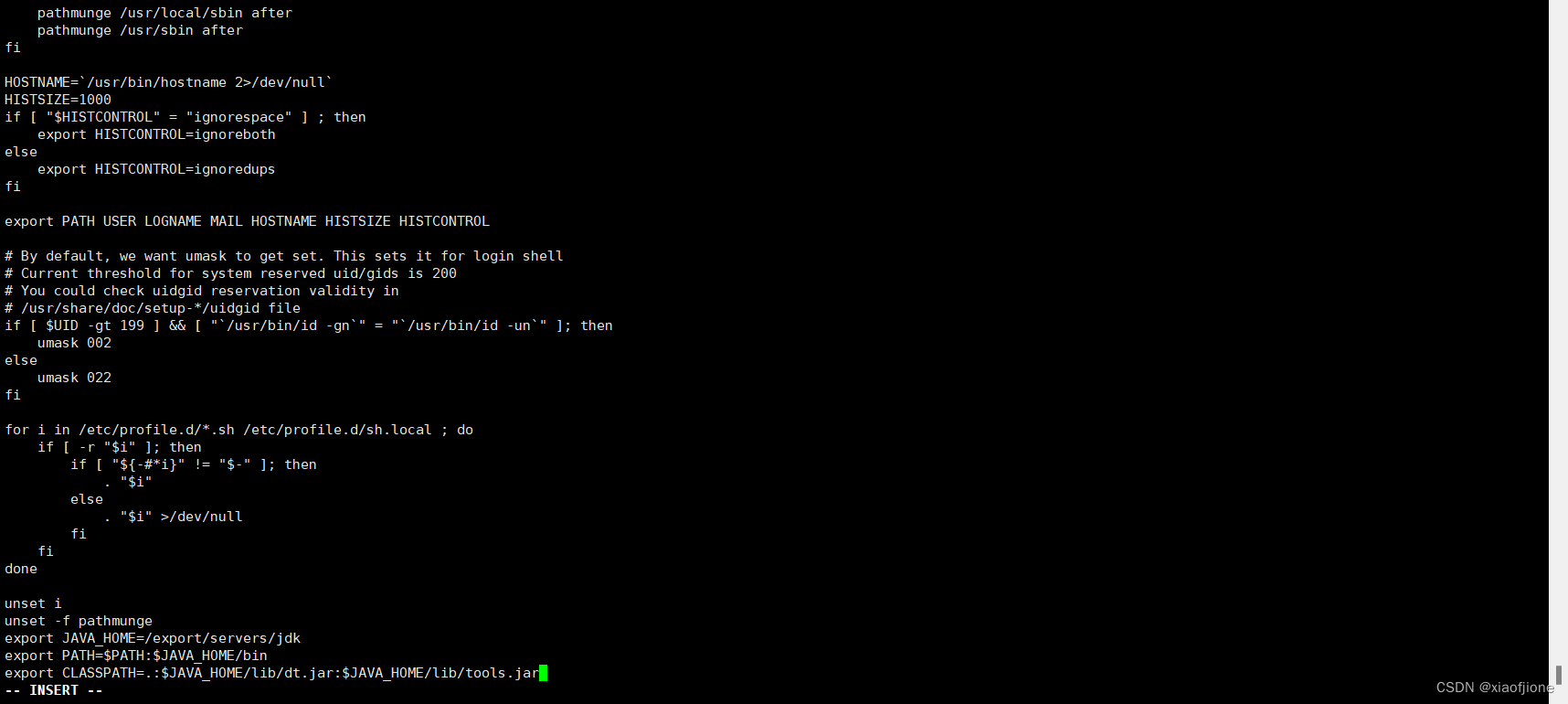
source /etc/profilejava -version
cd /export/software
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/vi /etc/profile#tip:在文件末尾追加
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profilehadoop version
ssh-keygen -t rsa
输入上面的代码后回车四次

ssh-copy-id localhost

cd /export/servers/hadoop-2.7.4/etc/hadoop/vi hadoop-env.sh
#tip:找到相应位置,添加这段话
export JAVA_HOME=/export/servers/jdk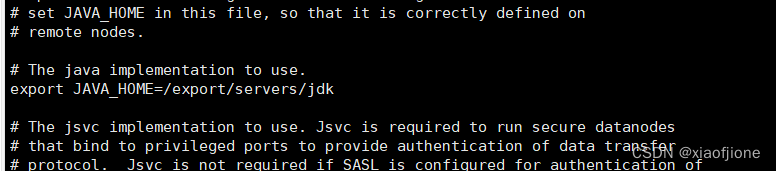
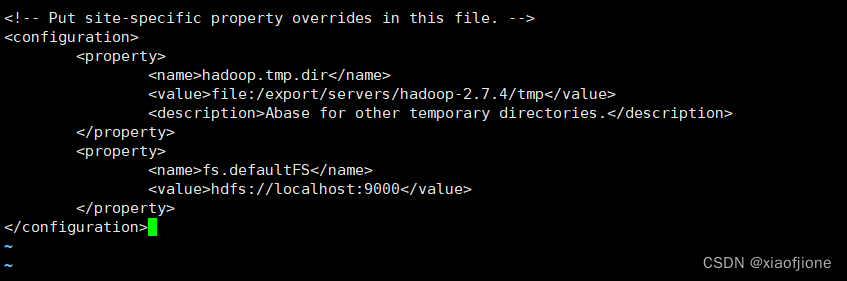
vi core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/export/servers/hadoop-2.7.4/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
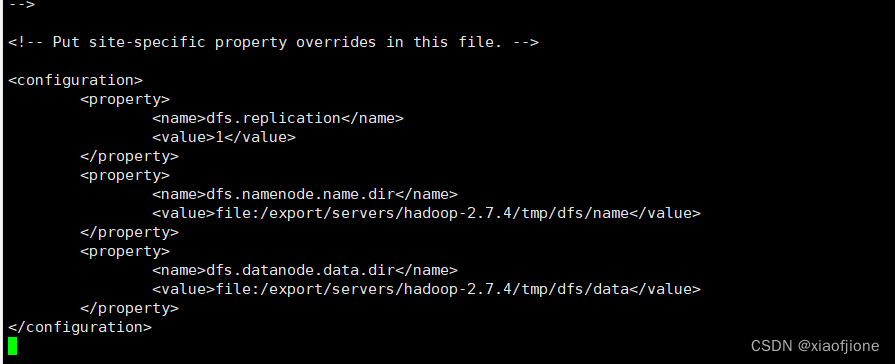
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/servers/hadoop-2.7.4/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/servers/hadoop-2.7.4/tmp/dfs/data</value>
</property>
</configuration>
mv mapred-site.xml.template mapred-site.xml
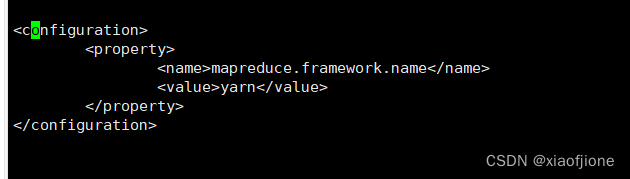
vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.6修改yarn-site.xml
vi yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>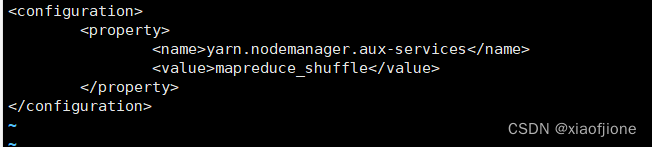
hdfs namenode -format
三、Hadoop 启动
start-dfs.sh
start-yarn.sh
start-all.sh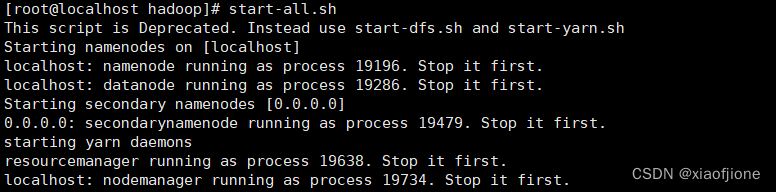
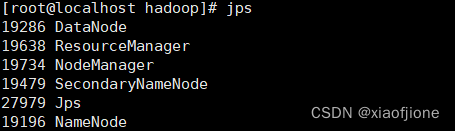
2.关闭防火墙(所有虚拟机都要操作)
systemctl stop firewalld
#关闭防火墙systemctl disable firewalld.service
#关闭防火墙开机启动
3.打开 window 下
firewall-cmd --state
# 查看防火墙状态![]()
的 C:\Windows\System32\drivers\etc 打开 hosts 文件,在文件末
192.168.230.222 hadoop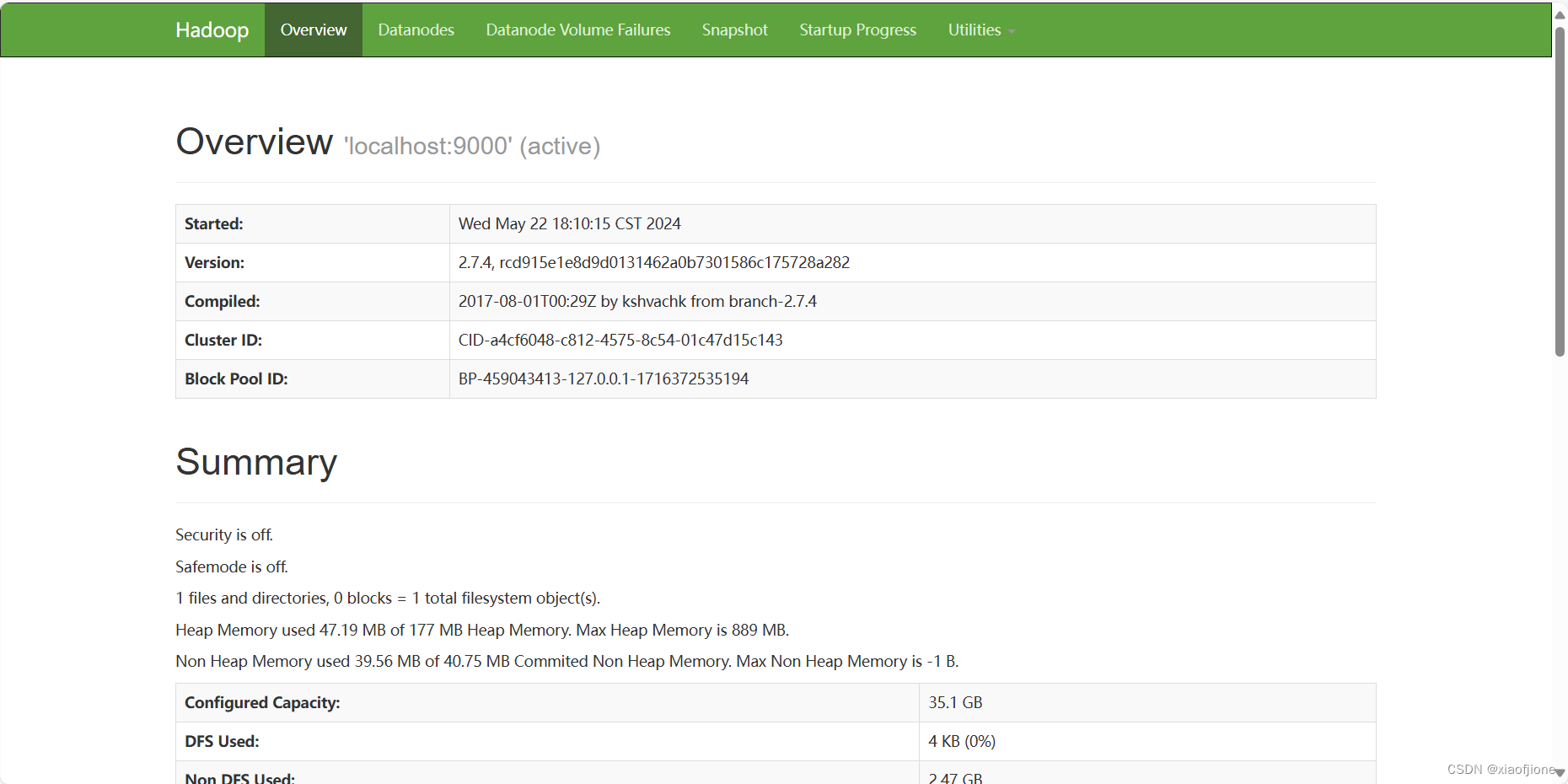
(二)Hive 的部署
cd /export/software/tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /export/servers/cd /export/servers/mv apache-hive-2.3.9-bin hive-2.3.9
ls

vi /etc/profile
export HIVE_HOME=/export/servers/hive-2.3.9
export PATH=$PATH:$HIVE_HOME/bin
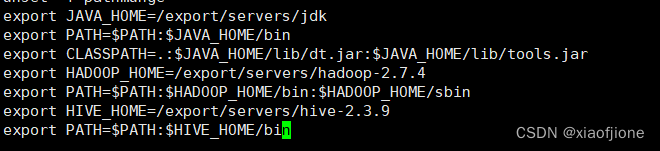
source /etc/profile
2.安装mysql病配置sql服务器
2.1上传mysql安装包rz mysql-community-release-el7-5.noarch.rpm
2.2 安装 rpm
cd /export/sofrware
rpm -ivh mysql-community-release-el7-5.noarch.rpm
2.3 执行安装
yum install mysql-community-server
2.4 设置开机启动并启动mysql服务
systemctl enable mysqld
systemctl start mysqld
ok,因为版本的原因,安装的mysql未自动生成密码,8.x版本以上会自动生成
2.5 输入mysql ,启动mysql
mysql
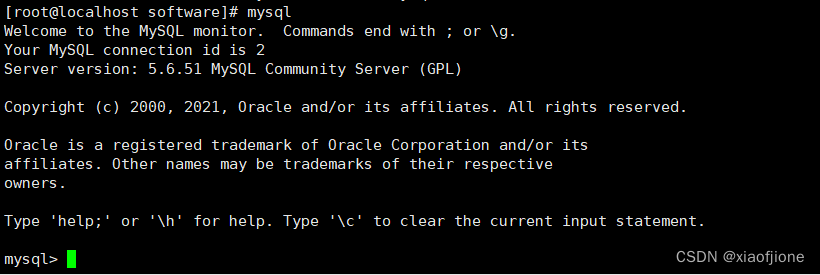
abc123 为root密码
grant all privileges on *.* to 'root'@'%' identified by 'abc123' with grant option;
2.6 启动、关闭、重启服务
systemctl start mysqld
systemctl stop mysqld
systemctl restart mysqld

cd /export/servers/hive-2.3.9/confcp hive-env.sh.template hive-env.shvi hive-env.shHADOOP_HOME=/export/servers/hadoop-2.7.4
export HIVE_CONF_DIR=/export/servers/hive-2.3.9/conf
export HIVE_AUX_JARS_PATH=/export/servers/hive-2.3.9/lib

cd /export/servers/hive-2.3.9/conf/
cp hive-log4j2.properties.template hive-log4j2.propertiesvi hive-site.xml注:下述代码中,192.168.230.200为本机虚拟机ip地址,编辑时需要修改成自己的
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.230.200:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>abc123</value>
</property>
</configuration>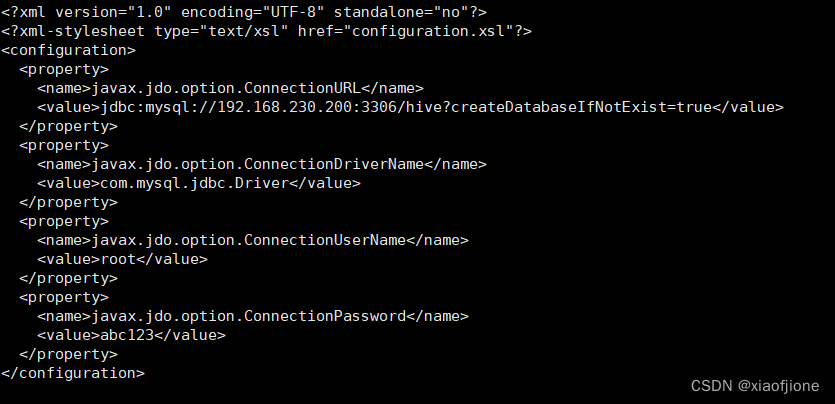
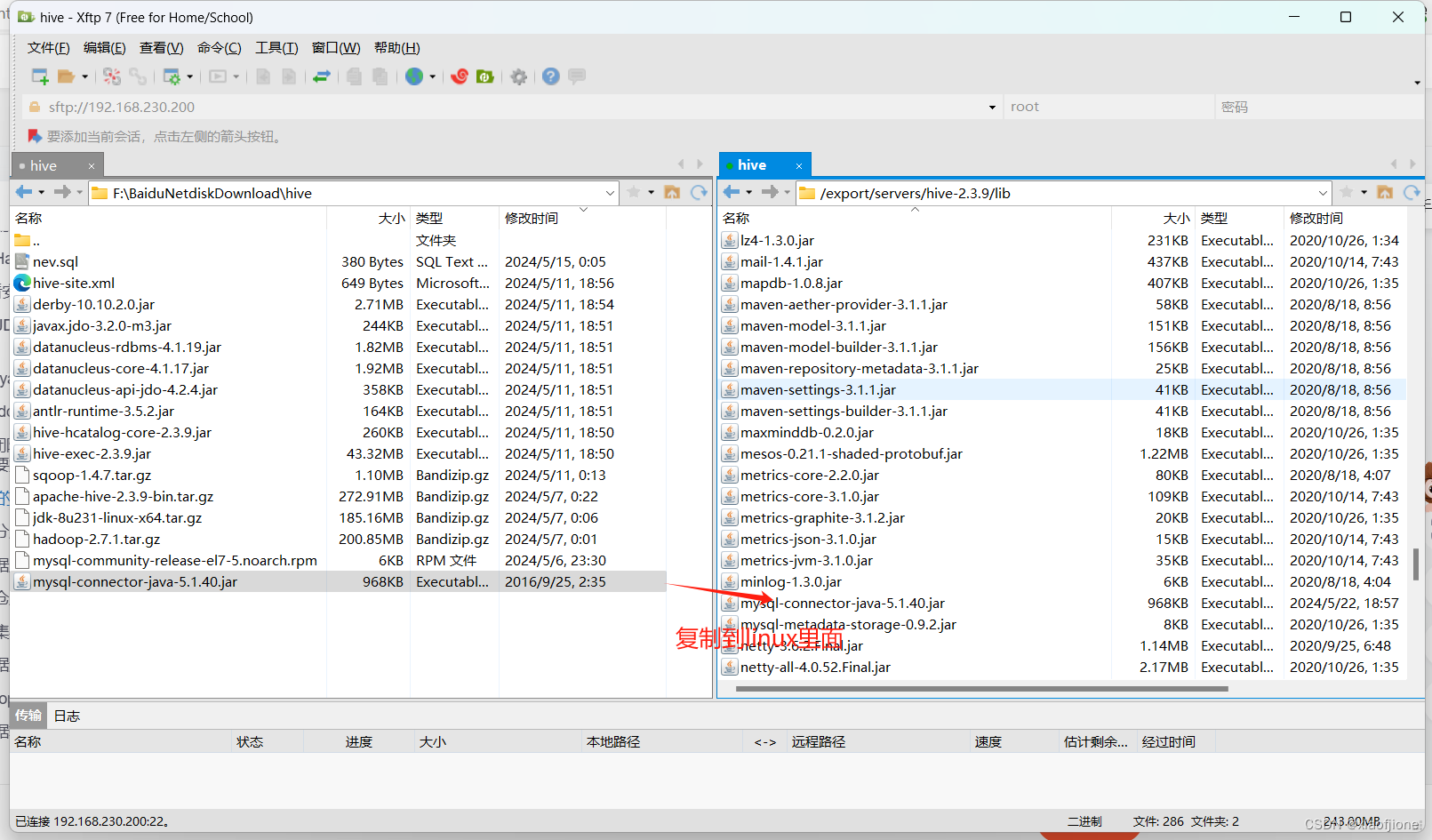
schematool -dbType mysql -initSchema
4.4启动hive

二、数据仓库分层
(一)源数据层的实现
CREATE DATABASE IF NOT EXISTS itcast_ods;Set hive.exec.orc.compression.strategy=COMPRESSION;CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_ems (
id INT comment '主键',
create_date_time STRING comment '数据创建时间',
session_id STRING comment '七陌sessionId',
sid STRING comment '访客id',
create_time STRING comment '会话创建时间',
seo_source STRING comment '搜索来源',
seo_keywords STRING comment '关键字',
ip STRING comment 'IP地址',
area STRING comment '地域',
country STRING comment '所在国家',
province STRING comment '省',
city STRING comment '城市',
origin_channel STRING comment '投放渠道',
user_match STRING comment '所属坐席',
manual_time STRING comment '人工开始时间',
begin_time STRING comment '坐席领取时间 ',
end_time STRING comment '会话结束时间',
last_customer_msg_time_stamp STRING comment '客户最后一条消息的时间',
last_agent_msg_time_stamp STRING comment '坐席最后一下回复的时间',
reply_msg_count INT comment '客服回复消息数',
msg_count INT comment '客户发送消息数',
browser_name STRING comment '浏览器名称',
os_info STRING comment '系统名称')
comment '访问会话信息表'
PARTITIONED BY(starts_time STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orc
location '/user/hive/warehouse/itcast_ods.db/web_chat_ems_ods'
TBLPROPERTIES ('orc.compress'='ZLIB');CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_text_ems_ods
(
id INT COMMENT "主键 ID",
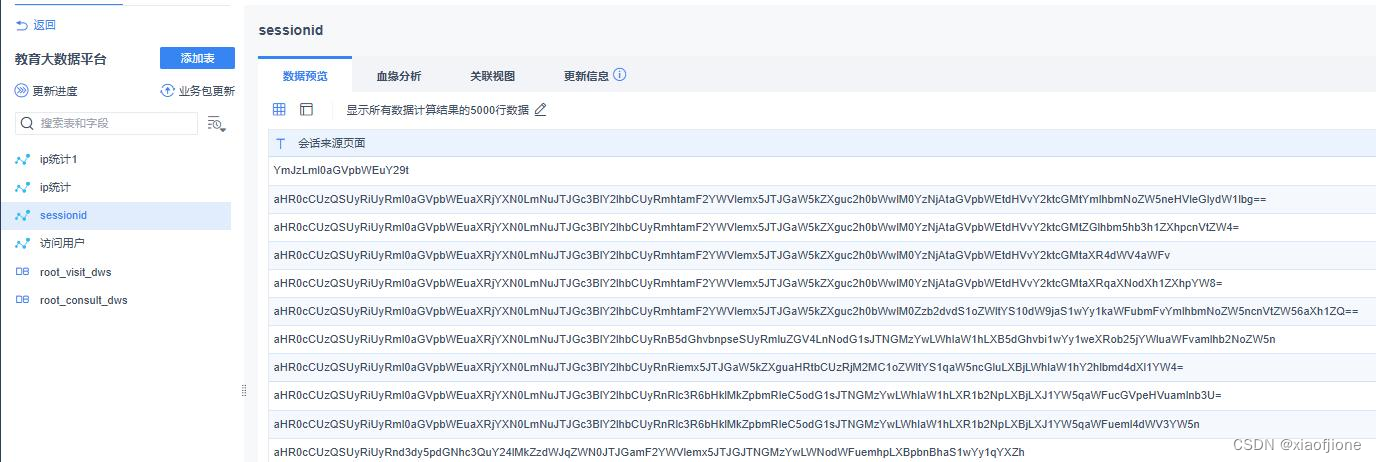
referrer STRING COMMENT "上级来源页面",
from_url STRING COMMENT "会话来源页面",
landing_page_url STRING COMMENT "访客浏览页面",
url_title STRING COMMENT "页面标题",
platform_description STRING COMMENT "用户信息",
other_params STRING COMMENT "扩展字段",
history STRING COMMENT "历史访问记录"
)
COMMENT "用户会话信息附属表"
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
LOCATION "/user/hive/warehouse/itcast_ods.db/web_chat_text_ems_ods"
TBLPROPERTIES ("orc.compress"="ZLIB");(二)数据仓库层的实现
CREATE DATABASE IF NOT EXISTS itcast_dwd;CREATE TABLE IF NOT EXISTS itcast_dwd.visit_consult_dwd (
session_id STRING COMMENT "会话 ID",
sid STRING COMMENT "用户 ID",
create_time BIGINT COMMENT "会话创建时间",
ip STRING COMMENT "IP 地址",
area STRING COMMENT "地区",
msg_count INT COMMENT "客户发送消息数",
origin_channel STRING COMMENT "来源渠道",
from_url STRING COMMENT "会话来源页面"
)
COMMENT "访问咨询用户明细表"
PARTITIONED BY (yearinfo STRING, monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");CREATE DATABASE IF NOT EXISTS itcast_dws;CREATE TABLE IF NOT EXISTS itcast_dws.visit_dws (
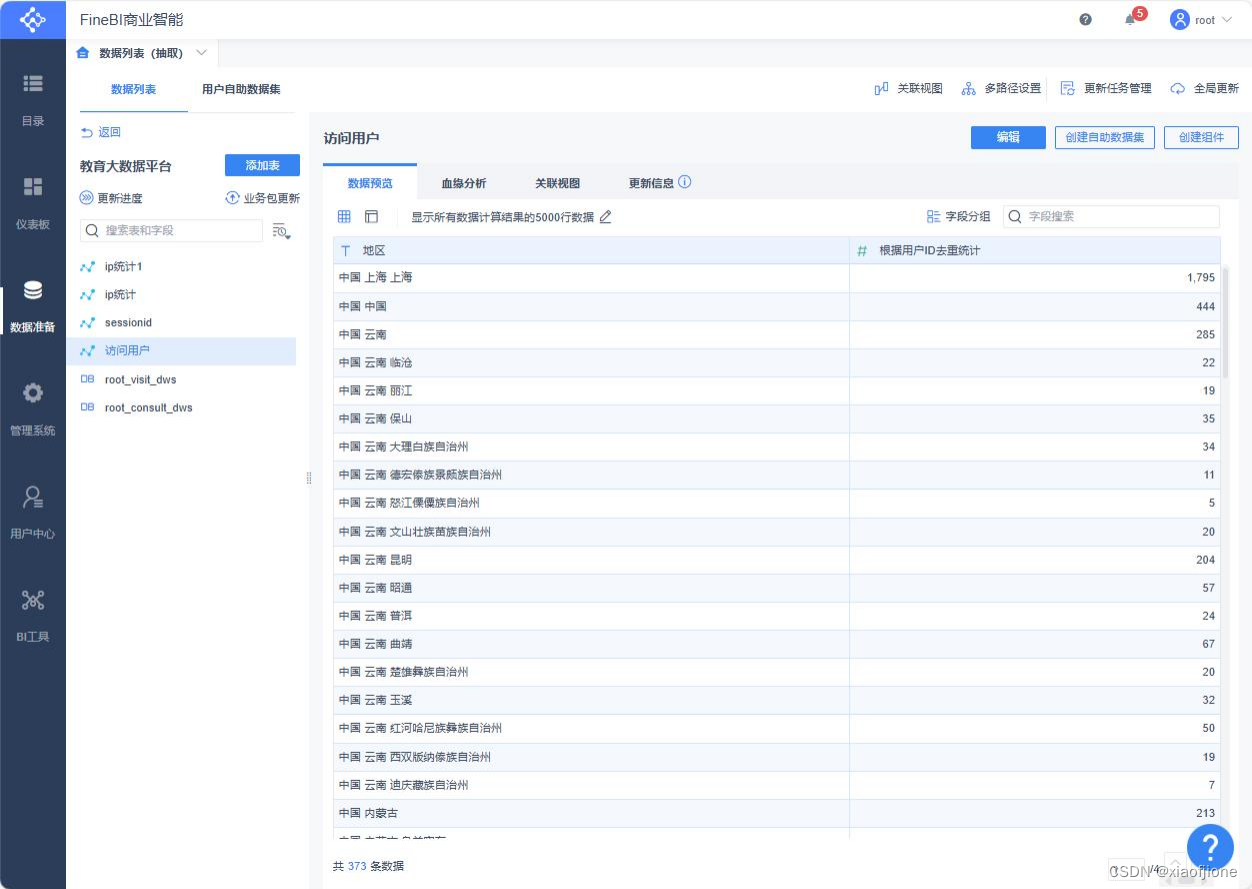
sid_total INT COMMENT "根据用户 ID 去重统计",
sessionid_total INT COMMENT "根据 SessionID 去重统计",
ip_total INT COMMENT "根据 IP 地址去重统计",
area STRING COMMENT "地区",
origin_channel STRING COMMENT "来源渠道",
from_url STRING COMMENT "会话来源页面",
groupType STRING COMMENT "1.地区维度 2.来源渠道维度 3.会话页面维度 4.
总访问量维度"
)
COMMENT "访问用户量宽表"
PARTITIONED BY (yearinfo STRING,monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
Stored as orc
TBLPROPERTIES ("orc.compress"="SNAPPY");CREATE TABLE IF NOT EXISTS itcast_dws.consult_dws
(
sid_total INT COMMENT "根据用户 ID 去重统计",
sessionid_total INT COMMENT "根据 SessionID 去重统计",
ip_total INT COMMENT "根据 IP 地址去重统计"
)
COMMENT "咨询用户量宽表"
PARTITIONED BY (yearinfo STRING, monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");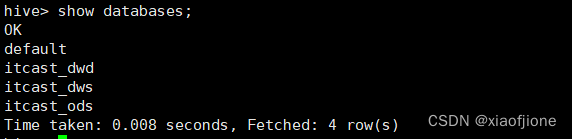
三、数据采集与转换
(一)数据迁移过程
1、Sqoop 的简介
cd /export/software
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /export/servers/cd /export/servers
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7

vi /etc/profile# SQOOP_HOME
export SQOOP_HOME=/export/servers/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/binsource /etc/profilecd /export/servers/sqoop-1.4.7/conf
cp sqoop-env-template.sh sqoop-env.sh
#指定Hadoop安装目录
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.4/
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.4/
#指定Hive安装目录
export HIVE_HOME=/export/servers/hive-2.3.9将 MySQL 的驱动包放到 sqoop 的 lib 下面
cp /export/servers/hive-2.3.9/lib/mysql-connector-java-5.1.40.jar /export/servers/sqoop-1.4.7/lib/sqoop help
sqoop list-databases \
--connect jdbc:mysql://192.168.230.200:3306/ \
--username root --password abc123
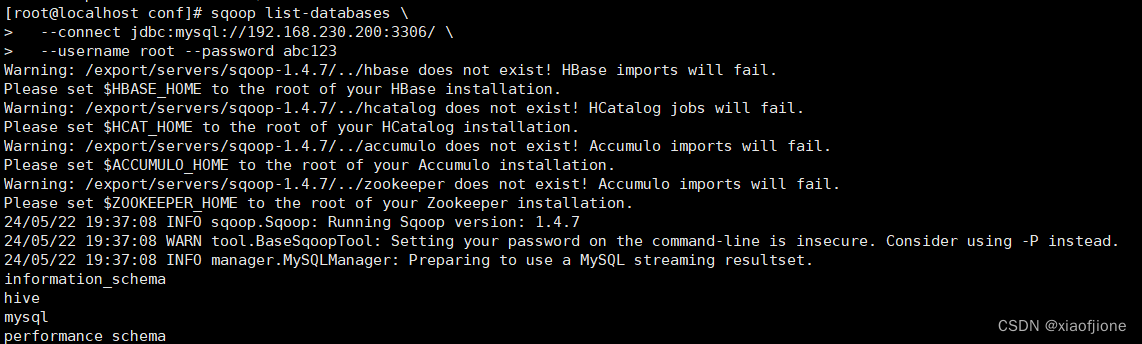
导入数据文件
以root身份登录MySQL数据库,在MySQL数据库的命令行交互界面执行“source /export/data/nev.sql”命令,将数据库文件导入到MySQL数据库。数 据库文件导入完成后执行“showdatabases;”命令查看数据库列表。
source /export/data/nev.sql
show databases;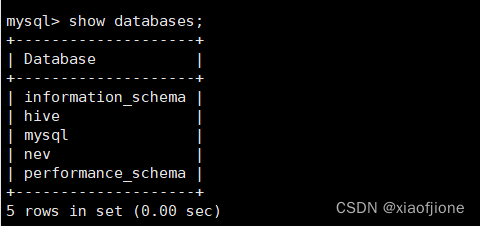
在MySQL的命令行交互界面执行“use nev;”命令,切换到数据库nev,然后执行“show tables;”命令查看数据库nev中的数据表。
use nev;
show tables;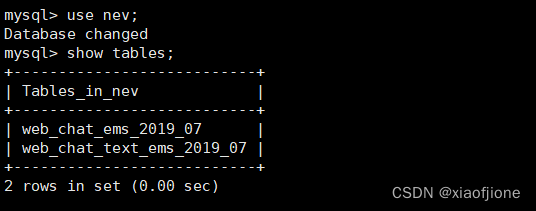
导入依赖包
由于Sqoop向Hive表中导入数据时依赖于Hive的相关jar包,所以需要将Hive的相关jar包导入到Sqoop的lib目录中,具体命令如下。
cp /export/servers/hive-2.3.9/lib/{antlr-runtime-3.5.2.jar,hive-hcatalog-core-2.3.9.jar,hive-exec-2.3.9.jar,datanucleus-api-jdo-4.2.4.jar,datanucleus-core-4.1.17.jar,datanucleus-rdbms-4.1.19.jar,derby-10.10.2.0.jar,javax.jdo-3.2.0-m3.jar} /export/servers/sqoop-1.4.7/lib/cp /export/servers/hive-2.3.9/lib/derby-10.10.2.0.jar /export/servers/hadoop-2.7.4/share/hadoop/yarn/lib/
导入配置文件
由于Sqoop向Hive表中导入数据时需要获取Hive的配置信息,所以需要将Hive 的配置文件hive-site.xml导入到Sqoop的conf目录下,具体命令如下。
cp /export/servers/hive-2.3.9/conf/hive-site.xml /export/servers/sqoop-1.4.7/conf/(二)数据转换过程
sqoop import \
--connect jdbc:mysql://192.168.230.200:3306/nev \
--username root \
--password abc123 \
--query "select id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,ip,area,country,province,city,origin_channel,user as user_match,manual_time,begin_time,end_time,last_customer_msg_time_stamp,last_agent_msg_time_stamp, reply_msg_count,msg_count,browser_name,os_info from web_chat_ems_2019_07 where 1=1 and \$CONDITIONS"\
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_ems_ods \
-m 10 \
--split-by idsqoop import \
--connect jdbc:mysql://192.168.230.200:3306/nev \
--username root \
--password abc123 \
--query "select id,referrer,from_url,landing_page_url,url_title,platform_description,
other_params,history from web_chat_text_ems_2019_07 where 1=1 and \$CONDITIONS" \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_text_ems_ods \
-m 10 \
--split-by id
select count(*) from itcast_ods.web_chat_ems_ods;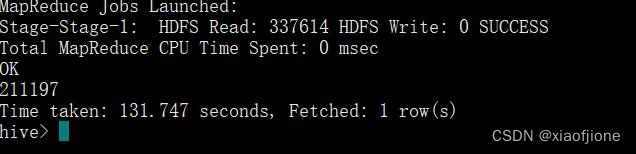
据转换,具体命令如下。
select count(*) from itcast_ods.web_chat_text_ems_ods;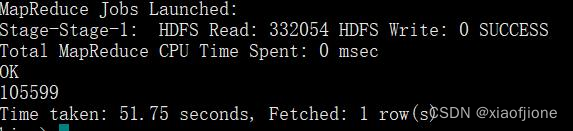
四、数据分析
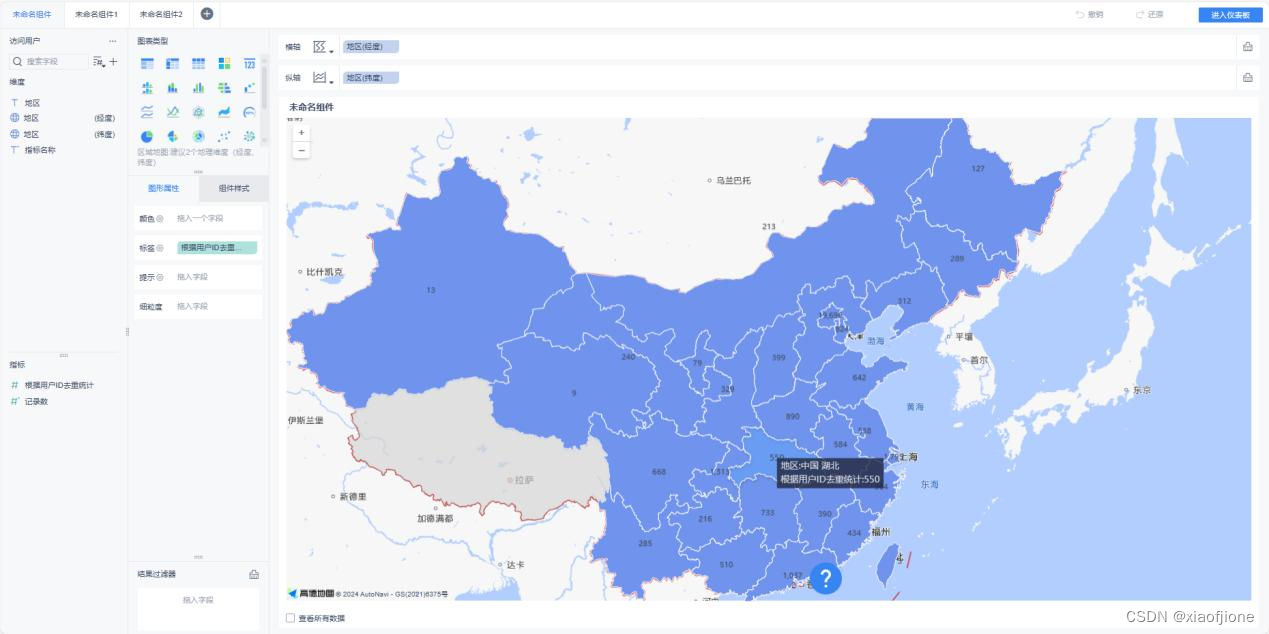
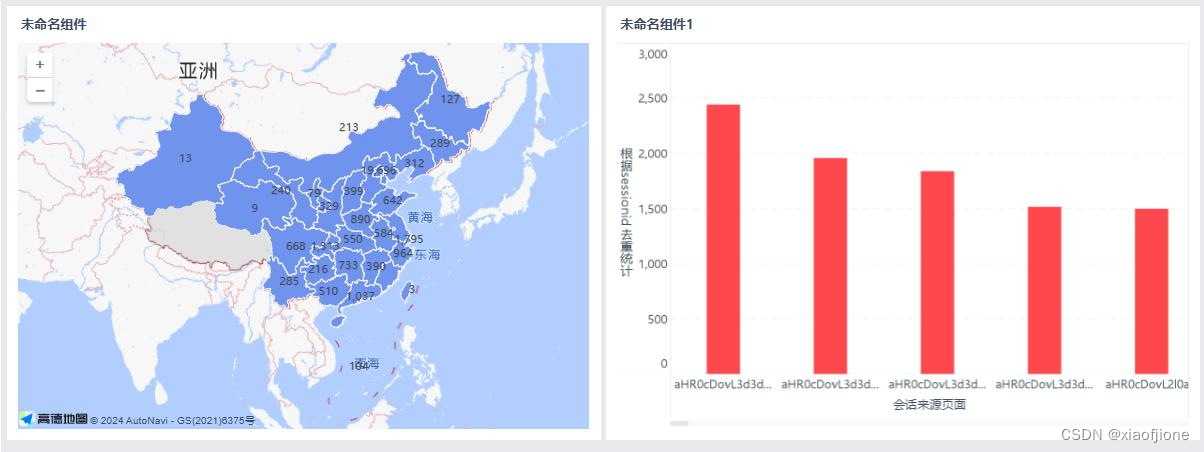
(一)实现地区访问用户量统计
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) sessionid_total,
COUNT(DISTINCT ip) ip_total,
area,
'-1' origin_channel,
'-1' from_url,
'1' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
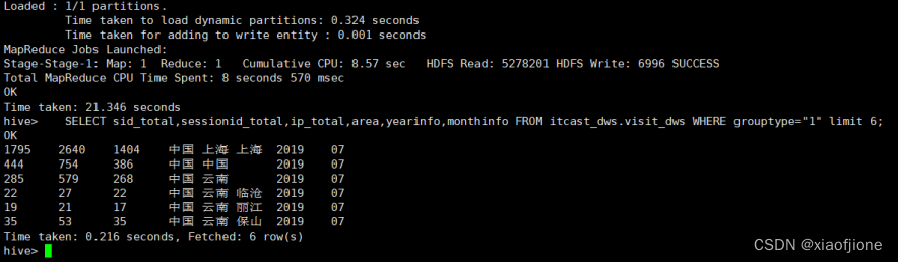
GROUP BY area,yearinfo,monthinfo; SELECT sid_total,sessionid_total,ip_total,area,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="1" limit 6;
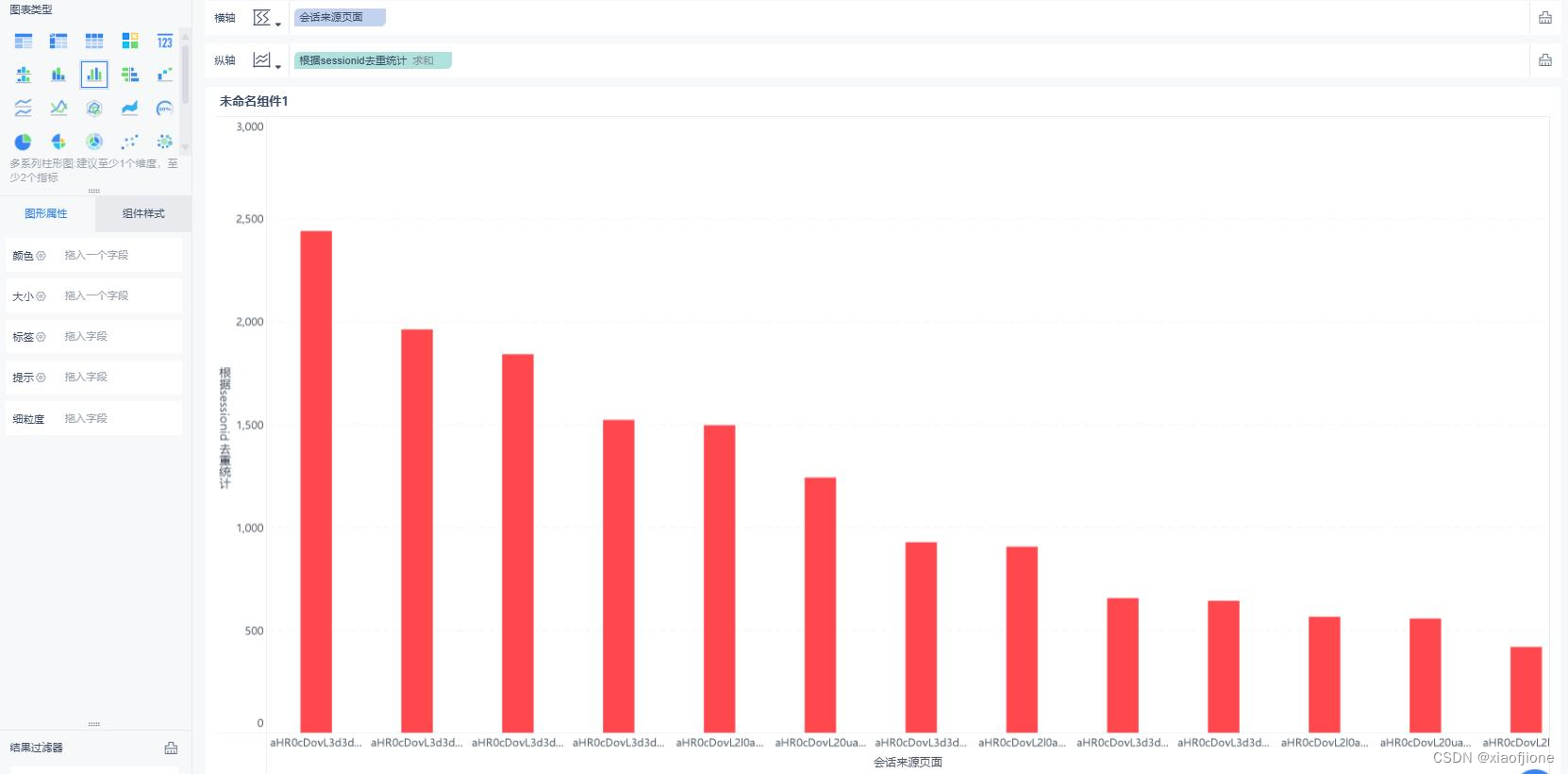
(二)实现会话页面排行榜
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo, monthinfo)
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) sessionid_total,
COUNT(DISTINCT ip) ip_total,
'-1' area,
'-1' origin_channel,
from_url,
'3' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
GROUP BY from_url,yearinfo,monthinfo; SELECT sessionid_total,from_url,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="3" AND from_url!="" ORDER BY sessionid_total DESC LIMIT 1;

(三)实现访问用户量统计
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo, monthinfo)
SELECT
COUNT( DISTINCT sid ) sid_total,
COUNT( DISTINCT session_id ) sessionid_total,
COUNT( DISTINCT ip ) ip_total,
'-1' area,
'-1' origin_channel,
'-1' from_url,
'4' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
GROUP BY yearinfo,monthinfo; SELECT sid_total,sessionid_total,ip_total,yearinfo,monthinfo
FROM itcast_dws.visit_dws WHERE grouptype="4";

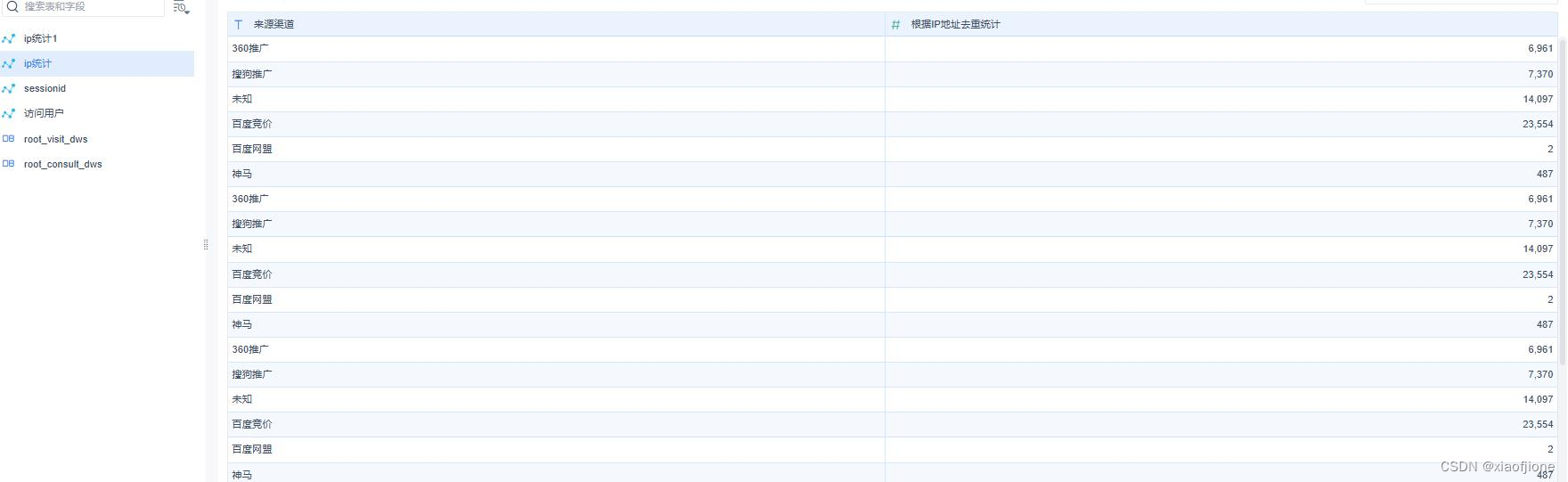
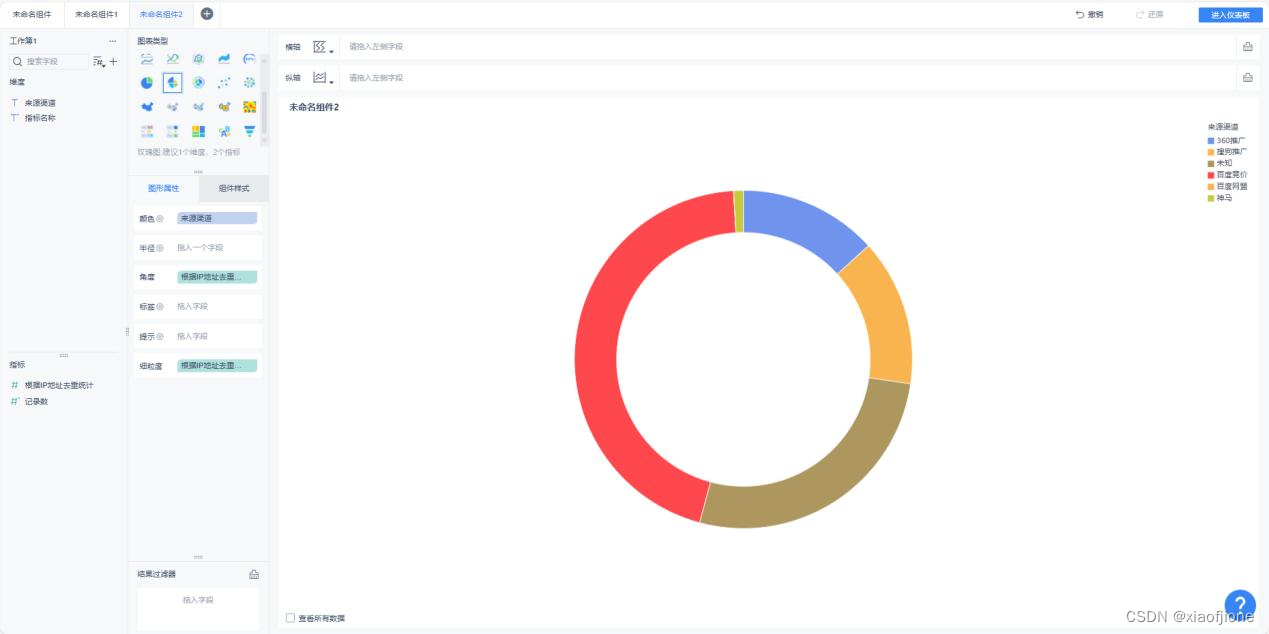
(四)实现来源渠道访问用户量统计
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo,monthinfo)
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) session_total,
COUNT(DISTINCT ip) ip_total,
'-1' area,
origin_channel,
'-1' from_url,
'2' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
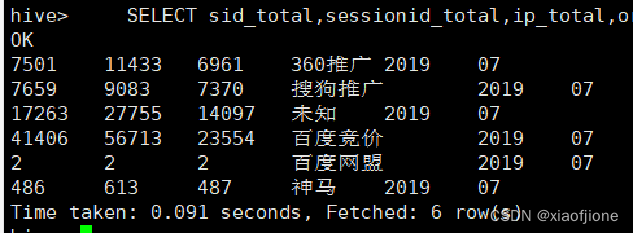
19GROUP BY origin_channel,yearinfo,monthinfo; SELECT sid_total,sessionid_total,ip_total,origin_channel,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="2";
(五)实现咨询率统计
SELECT
CONCAT(ROUND(msgNumber.sid_total / totalNumber.sid_total,4) * 100, '%')
sid_rage,
CONCAT (ROUND (msgNumber.sessionid_total/ totalNumber.sessionid_total,4)*100,
'%') session_rage,
CONCAT (ROUND (msgNumber.ip_total / totalNumber.ip_total,4)* 100, '&')
ip_rage,
msgNumber.yearinfo,
msgNumber.monthinfo
FROM
(
SELECT
sid_total,
sessionid_total,
ip_total,
yearinfo,
monthinfo
FROM itcast_dws.consult_dws
) msgNumber,
(
SELECT
sid_total,
sessionid_total,
ip_total,
yearinfo,
monthinfo
FROM itcast_dws.visit_dws
where grouptype="4"
) totalNumber;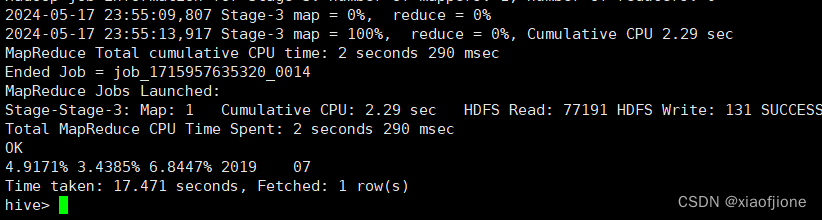
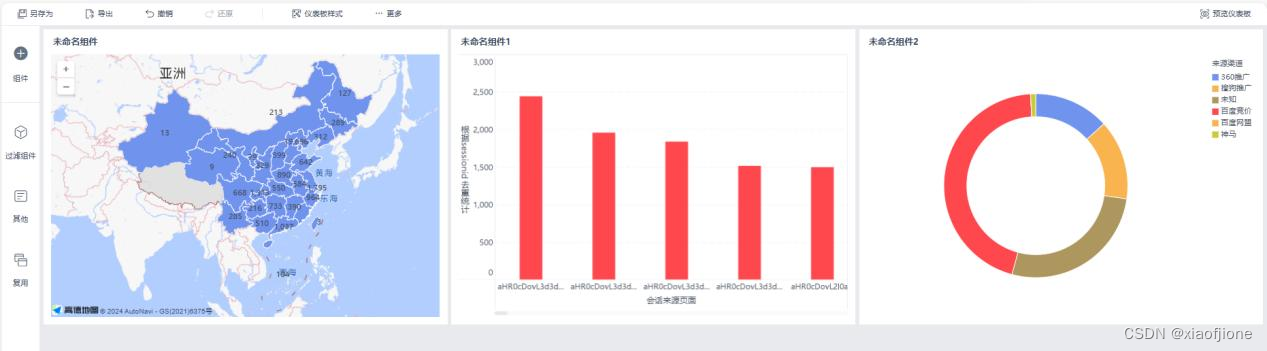
(六)数据可视化
CREATE TABLE nev.visit_dws (
sid_total INT(11) COMMENT '根据用户 ID 去重统计',
sessionid_total INT(11) COMMENT '根据 SessionID 去重统计',
ip_total INT(11) COMMENT '根据 IP 地址去重统计',
area VARCHAR(32) COMMENT '地区', -- 添加单引号并在注释前后加上空格
origin_channel VARCHAR(32) COMMENT '来源渠道', -- 添加单引号并在注释前
后加上空格
from_url VARCHAR(100) COMMENT '会话来源页面', -- 添加单引号并在注释前
后加上空格
groupType VARCHAR(100) COMMENT '1.地区维度 2.来源渠道维度 3.会话页面
维度 4 总访问量维度',
yearinfo VARCHAR(32) COMMENT '年',
monthinfo VARCHAR(32) COMMENT '月'
);CREATE TABLE nev.consult_dws (
sid_total INT(11) COMMENT '根据用户 ID 去重统计',
sessionid_total INT(11) COMMENT '根据 SessionID 去重统计',
21ip_total INT(11) COMMENT '根据 IP 地址去重统计',
yearinfo VARCHAR(32) COMMENT '年',
monthinfo VARCHAR(32) COMMENT '月'
);use nev;show tables;sqoop export \
--connect "jdbc:mysql://192.168.230.222:3306/nev?useUnicode=true&character
Encoding=utf-8" \
--username root \
--password abc123 \
--table visit_dws \
22--hcatalog-database itcast_dws \
--hcatalog-table visit_dwssqoop export \
--connect "jdbc:mysql://192.168.230.222:3306/nev?
useUnicode=true&characterEncoding=utf-8" \
--username root \
--password abc123 \
--table consult_dws \
--hcatalog-database itcast_dws \
--hcatalog-table consult_dws


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









