







数据库的设计
多表之间的关系
1. 一对多(多对一):
* 如:部门和员工
* 实现方式:在多的一方建立外键,指向一的一方的主键。
2. 多对多:
* 如:学生和课程
* 实现方式:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
3. 一对一(了解):
* 如:人和身份证
* 实现方式:一对一关系实现,可以在任意一方添加唯一外键指向另一方的主键。
案例:
– 创建旅游线路分类表 tab_category
– cid 旅游线路分类主键,自动增长
– cname 旅游线路分类名称非空,唯一,字符串 100
CREATE TABLE tab_category(
cid int PRIMARY KEY auto_increment,
cname VARCHAR(100) not NULL UNIQUE
)ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='旅游线路分类表'
扩展:
- ENGINE=INNODB:指定存储引擎,innoDB 是 MySQL 上第一个提供外键约束的数据存储引擎,除了提供事务处理外,InnoDB 还支持行锁,提供和 Oracle 一样的一致性的不加锁读取,能增加并发读的用户数量并提高性能,不会增加锁的数量
- DEFAULT CHARSET=utf8,默认字符编码为utf8
3.comment 添加注释
案例:
– 创建旅游线路表 tab_route
/*
rid 旅游线路主键,自动增长
rname 旅游线路名称非空,唯一,字符串 100
price 价格
rdate 上架时间,日期类型
cid 外键,来自于上面的旅游分类表
*/
CREATE table tab_route (
rid int PRIMARY key auto_increment comment "旅游线路主键",
rname VARCHAR(100) not NULL UNIQUE comment "旅游线路名称",
price double comment "价格",
rdate DATE comment "上架日期",
cid int comment "外键",
FOREIGN key (cid) REFERENCES tab_category(cid)
)ENGINE = INNODB DEFAULT CHARSET=utf8 comment "旅游线路表"
/*创建用户表 tab_user
uid 用户主键,自增长
username 用户名长度 100,唯一,非空
password 密码长度 30,非空
name 真实姓名长度 100
birthday 生日
sex 性别,定长字符串 1
telephone 手机号,字符串 11
email 邮箱,字符串长度 100
*/
CREATE TABLE tab_user(
uid INT PRIMARY KEY AUTO_INCREMENT comment "用户主键",
username VARCHAR(100) UNIQUE NOT NULL comment "用户名",
PASSWORD VARCHAR(30) NOT NULL comment "密码",
NAME VARCHAR(100) comment "真实姓名",
birthday DATE comment "生日",
sex CHAR(1) DEFAULT '男' comment "性别",
telephone VARCHAR(11) comment "手机号",
email VARCHAR(100) comment "邮箱"
)ENGINE = INNODB DEFAULT CHARSET=utf8 comment "用户表"
/*
创建收藏表 tab_favorite
rid 旅游线路 id,外键
date 收藏时间
uid 用户 id,外键
rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次
*/
CREATE TABLE tab_favorite (
rid INT comment "外键id",
DATE DATETIME comment "收藏时间",
uid INT comment"用户id,外键" ,
-- 创建复合主键
PRIMARY KEY(rid,uid), -- 联合主键:指的是把两个列看成是一个整体,这个整体是不为空,唯一,不重复
FOREIGN KEY (rid) REFERENCES tab_route(rid),
FOREIGN KEY(uid) REFERENCES tab_user(uid)
)ENGINE = INNODB DEFAULT CHARSET=utf8 comment "收藏表"
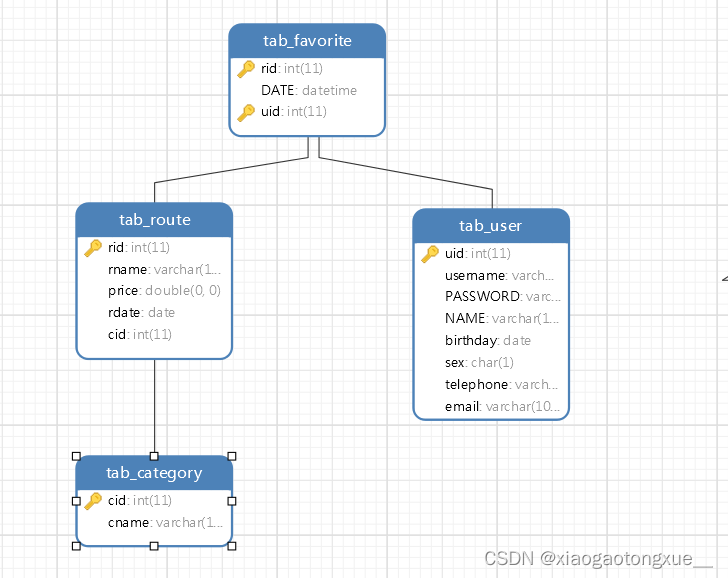
好了,现在表已经都建好了
tab_route和tab_category 是多对一关系(每条路线都对应一个类别)
tab_route和tab_user是多对多关系(每个人都可以选择不同的路线),这里借助中间表tab_favorite来实现
生成的模型表
数据库设计的范式
- 概念:设计数据库时,需要遵循的一些规范。要遵循后边的范式要求,必须先遵循前边的所有范式要求
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
第一范式(1NF):每一列都是不可分割的原子数据项
(一般在任何一个关系数据库中,第一范式是对关系模式设计的基本要求)
举例:数据表中某一列表示“联系方式”,这一列里面包括“手机号,微信,qq,邮箱”,是可以继续拆分的,不符合第一范式。
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 几个概念:
1. 函数依赖:A–>B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
例如:学号–>姓名。 (学号,课程名称) --> 分数
2. 完全函数依赖:A–>B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。
例如:(学号,课程名称) --> 分数
3. 部分函数依赖:A–>B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
例如:(学号,课程名称) – > 姓名
4. 传递函数依赖:A–>B, B – >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A
例如:学号–>姓名,姓名–>系主任
5. 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
* 主属性:码属性组中的所有属性
* 非主属性:除去码属性组的属性
判断一个关系是否属于第二范式:
找出数据表中的所有码;
找出所有主属性和非主属性;
判断所有的非主属性对码的部分函数依赖。
第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(也就是说只能依赖于主属性,在2NF基础上消除传递依赖)
这是一个很舒服的东西,让我的打字变得非常的快,、好吧 ,谢谢我的宝贝
巴斯-科德范式(BCNF):在3NF基础上,任何主属性不能对主键子集依赖(在3NF基础上消除主属性对主码子集的依赖)
(它只是在第二,第三范式中规范要求更强,相当于对第三范式的修改。因为范式规则是递增的,它还达不到那种要求,所以称为BCNF)
理解: 根据定义我们可以得到结论,一个满足BC范式的关系模式有:
1.所有非主属性对每一个码都是完全函数依赖。
2.所有的主属性对每一个不包含它的码,也是完全函数依赖。
3.没有任何属性完全函数依赖于非码的任何一组属性。
举例:就是X→Y时,X一定含有码(候选码中的任意一个)
规范化目的是使结构更合理,消除存储异常,使数据冗余尽量小。便于插入、删除和更新。
遵从概念单一化“一事一地”原则,即一个关系模式描述一个实体或实体间的一种联系。规范的实质就是概念的单一化。
一个关系模式接着分解可以得到不同关系模式集合,也就是说分解方法不是惟一的。最小冗余的要求必须以分解后的数据库能够表达原来数据库所有信息为前提来实现。其根本目标是节省存储空问,避免数据不一致性,提高对关系的操作效率,同时满足应用需求。实际上,并不一定要求全部模式都达到BCNF不可。有时故意保留部分冗余可能更方便数据查询。尤其对于那些更新频度不高,查询频度极高的数据库系统更是如此。
反范式
规范化的优点是明显的,它避免了大量的数据冗余,节省了存储空间,保持了数据的一致性。当一个库里的数据经常发生变化时,达到3NF的库可以使用户不必在超过两个以上的地方更改同一个值。那么是不是只要把所有的表都规范为3NF后,数据库的设计就是最优的呢?这可不一定。范式越高意味着表的划分更细,一个数据库中需要的表也就越多,用户不得不将原本相关联的数据分摊到多个表中。当用户同时需要这些数据时只能采用连接表的形式将数据重新合并在一起。同时把多个表联接在一起的花费是巨大的,尤其是当需要连接的两张或者多张表数据非常庞大的时候,表连接操作几乎是一个噩梦,这严重地降低了系统运行性能















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









