







6.4 有效的字母异位词【242】
6.4.1 题目描述
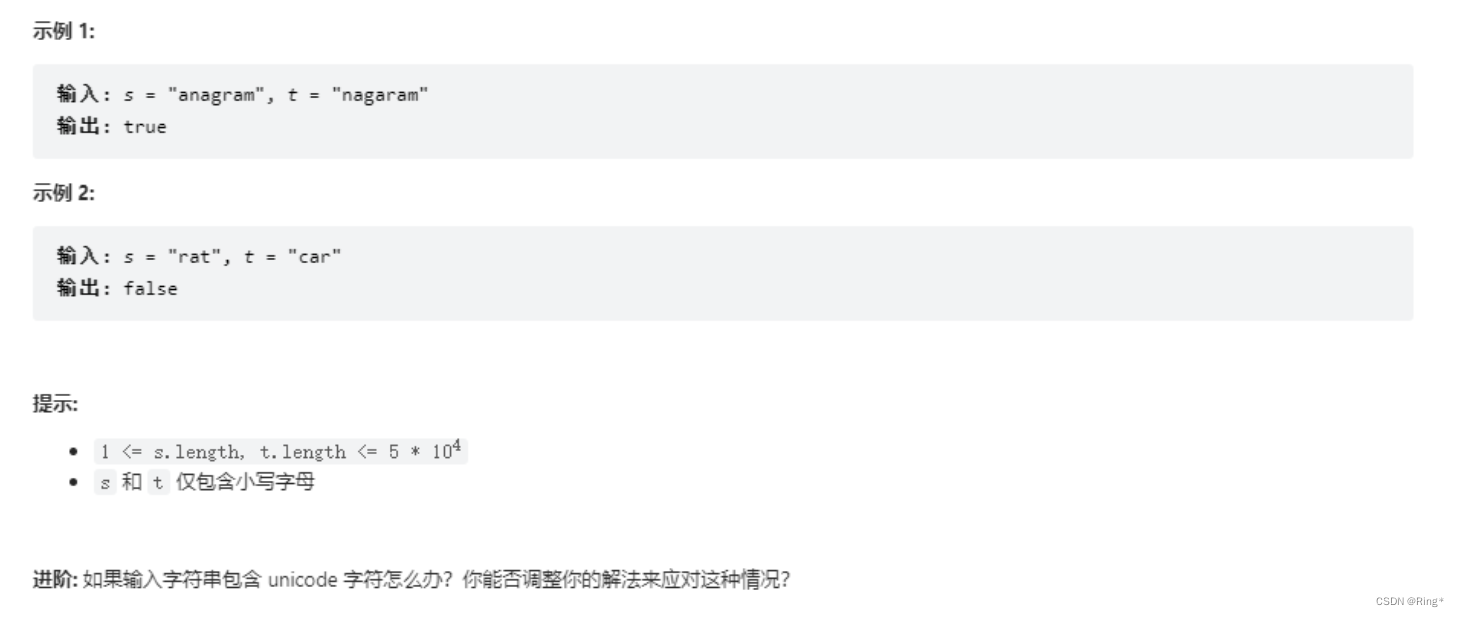
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
6.4.2 方法一:排序
t 是 s 的异位词等价于「两个字符串排序后相等」。因此我们可以对字符串 s 和 t 分别排序,看排序后的字符串是否相等即可判断。此外,如果 s 和 t 的长度不同,t 必然不是 s 的异位词。
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
char[] str1 = s.toCharArray();
char[] str2 = t.toCharArray();
Arrays.sort(str1);
Arrays.sort(str2);
return Arrays.equals(str1, str2);
}
}
复杂度分析

6.4.3 方法二:哈希表
从另一个角度考虑,t 是 s 的异位词等价于「两个字符串中字符出现的种类和次数均相等」。由于字符串只包含 26 个小写字母,因此我们可以维护一个长度为 26 的频次数组 table,先遍历记录字符串 s 中字符出现的频次,然后遍历字符串 t,减去 table 中对应的频次,如果出现 table[i]<0,则说明 t 包含一个不在 s 中的额外字符,返回 false 即可。
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] table = new int[26];
for (int i = 0; i < s.length(); i++) {
table[s.charAt(i) - 'a']++;
}
for (int i = 0; i < t.length(); i++) {
table[t.charAt(i) - 'a']--;
if (table[t.charAt(i) - 'a'] < 0) {
return false;
}
}
return true;
}
}
对于进阶问题,Unicode 是为了解决传统字符编码的局限性而产生的方案,它为每个语言中的字符规定了一个唯一的二进制编码。而 Unicode 中可能存在一个字符对应多个字节的问题,为了让计算机知道多少字节表示一个字符,面向传输的编码方式的UTF−8 和 UTF−16 也随之诞生逐渐广泛使用,具体相关的知识读者可以继续查阅相关资料拓展视野,这里不再展开。
回到本题,进阶问题的核心点在于「字符是离散未知的」,因此我们用哈希表维护对应字符的频次即可。同时读者需要注意 \text{Unicode}Unicode 一个字符可能对应多个字节的问题,不同语言对于字符串读取处理的方式是不同的。
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
Map<Character, Integer> table = new HashMap<Character, Integer>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
table.put(ch, table.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < t.length(); i++) {
char ch = t.charAt(i);
table.put(ch, table.getOrDefault(ch, 0) - 1);
if (table.get(ch) < 0) {
return false;
}
}
return true;
}
}
复杂度分析
- 时间复杂度:O(n),其中 n 为 s的长度。
- 空间复杂度:O(S),其中 S 为字符集大小,此处 S=26。
6.4.4 my answer—排序/map计数
class Solution {
// 排序
public static boolean isAnagram(String s, String t) {
String s1 = myStrSort(s);
String t1 = myStrSort(t);
if(s1.length() != t1.length())return false;
if(s1.equals(t1))return true;
else return false;
}
public static String myStrSort(String s){
// 先将字符传转为 char 型数组
char[] chars = s.toCharArray();
// 使用 Arrays.sort(chars) 方法进行排序
Arrays.sort(chars);
// 然后再将char型数组作为参数传递给String类构造器
String sortStr = new String(chars);
// 返回排序好的字符串
return sortStr;
}
// map计数比较
// public boolean isAnagram(String s, String t) {
// Map<Character,Integer> maps = new HashMap<>();
// Map<Character,Integer> mapt = new HashMap<>();
// for (int i = 0; i < s.length(); i++) {
// Character ch = s.charAt(i);
// maps.put(ch,maps.getOrDefault(ch,0)+1);
// }
// for (int i = 0; i < t.length(); i++) {
// Character ch = t.charAt(i);
// mapt.put(ch,mapt.getOrDefault(ch,0)+1);
// }
// if(maps.size() != mapt.size())return false;
// for (Map.Entry<Character, Integer> characterIntegerEntry : mapt.entrySet()) {
// if(maps.containsKey(characterIntegerEntry.getKey())){
// if(!characterIntegerEntry.getValue().equals(maps.get(characterIntegerEntry.getKey()))){
// return false;
// }
// }else {
// return false;
// }
// }
// return true;
// }
}















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









