







这两天在看varnish,感慨一句,这软件真不错!!!
============
功能&程序包:
首先varnish是反向HTTP代理,是具有强大缓存功能的代理,因此也被称之为web加速器或http加速器。官网对它的描述是不仅是代理,还说它具有web应用防火墙、抵御DDOS、热链接保护、负载均衡等功能,看上去很厉害的样子。下面看看它是由哪些部分组成的吧,先贴一张图:

varnish软件包中的关键程序:
1.varnishd
2.varnishadmin
1.varnishd
2.varnishadmin
3.varnish日志管理&状态查询工具集
-----
1. varnishd
varnishd是主程序
,启动后生成两个进程,Manager Process(父进程)和Cacher Process(子进程),前者在启动时读入配置文件(稍后会讲到)并fork()出后者,同时具有CLI接口接收管理员的指令以用于管理后者,后者是真正处理缓存业务的进程,其下又可以生成若干线程,这些线程各司其职,完成缓存业务的处理并记录日志。这里的Manager进程和Cacher进程类似于Nginx的Master和Worker,可见服务器软件的设计思路多么相似。
既然Cacher Process是处理缓存业务的进程,那它监听在哪个端口?又是如何处理http请求的呢?哪些数据应该缓存,哪些数据不要缓存?如果请求的数据缓存区中没有又该怎么处理?缓存的对象是怎么组织存储的?Don't worry,下文会给出所有的答案。
两类配置文件
/etc/varnish/any_name.vcl
varnish是如何制定缓存策略的呢?(所谓缓存策略就是控制http请求要如何拿到所请求的资源,查不查缓存,怎么查,查不到怎么办等)就是通过varnish自己的语言VCL(Varnish Configuration Language)来控制的,我们使用这种语言把要对报文如何处理的动作写到 .vcl 文件中,然后让 varnishd 加载这个文件就ok了,下文会详细介绍如何使用。使用yum安装varnish后,系统会在/etc/varnish下生成一个default.vcl文件,我们可以把vcl控制语句写在这里面,也可以写在该目录下自建的 .vcl 文件中。该文件的具体配置将在后文详细说明,需要额外强调的是 .vcl 文件需要被gcc编译之后才能够被加载使用,所以要一定要预先安装gcc。
/etc/varnish/varnish.params
主要定义了启动的时候使用哪个vcl作为启动时的缓存策略,作为反向代理监听在哪个IP的哪个Port上,开启的CLI接口监听在哪个IP的哪个Port上。启动的时候设定Cacher Process有多少线程池,每个线程池有多少线程。还有很多与缓存业务处理相关的参数(如 default_grace),这些参数可以在启动时设定(有缺省值),也可以在启动后修改(启动时也可以指定哪些参数是启动后只读的)。
2. varnishadmin
我们已经知道Master Process具有CLI接口,且 /etc/varnish/varnish.params 中定义了Manager Process的监听接口,那 varnishd 启动后如何接受管理员的调整指令如变更缓存策略,增大线程池中最大线程数等指令呢?用varnishadm,varnishadm可以理解为就是 varnishd 服务的专用客户端。不过官网强烈建议Manager Process的CLI接口仅监听在本地127上,远程链接的话仅有一层保障,即双方都知道的一个Secret文件(/etc/varnish下)。若要连接到本地的varnishd,则直接键入varnishadm即可;若要连接到远程的varnishd,则需要执行 varnishadm -S path_of_secret_file -T remote_host:port, -S选项指明了用哪个Secret文件验证身份,客户端和服务器端要持有相同的Secret文件。
3. 日志管理工具集
和普通的web服务器类似,varnish做了什么工作,也会写在日志里。由于varnish产生的日志量较大,所以说其日志是存在内存中的,这样就减少了磁盘IO。内存中的日志区默认是80M左右,分为两部分,第一部分是counter区(计数器区),第二部分是http请求数据区。80M的空间写满了怎么办?从空间开始处继续写,那不就覆盖了之前的日志吗?对!覆盖了。那能否把日志记录在磁盘上呢?可以!不过这个不是本文重点要说的。
下面就开始看看如何配置使用varnish,实验拓扑如下:

实验前各个服务器的服务都正常运行。
7A上启动varnishd,作为缓存服务器使用。/etc/varnish/varnish.params 配置如下:
RELOAD_VCL=1 //设置不重启varnishd时可重载vcl
VARNISH_VCL_CONF=/etc/varnish/test.vcl //启动varnishd时加载的缓存策略文件,如果不给出,则varnishd启动时会报错。
VARNISH_LISTEN_ADDRESS=192.168.10.133 //作为反代,监听的地址
VARNISH_LISTEN_PORT=80 //作为反代,监听的端口,若直接面向互联网则需要设置为80;若前面有调度器,就随意了。
VARNISH_ADMIN_LISTEN_ADDRESS=127.0.0.1 //CLI管理接口监听的IP
VARNISH_ADMIN_LISTEN_PORT=6666 //CLI管理接口监听的端口
VARNISH_STORAGE="malloc,256M" //缓存对象存储方式
VARNISH_USER=varnish //设置Cacher Process进程的uid和gid,yum安装varnish过程中会创建varnish用户。Manage Process的uid和gid是root。
VARNISH_GROUP=varnish
DAEMON_OPTS="-p thread_pool_min=5 -p thread_pool_max=500 -p thread_pool_timeout=300" //另一种形式的varnishd启动时的参数配置,如果与上面的参数配置冲突,则以这里的为准。默认配置中该行被注释掉,也就是说未设置的参数使用默认配置。
补充知识点1:缓存对象被缓存在哪里?
varnish支持4种方式存储缓存对象:
1. malloc(key-value均存储在内存中)
2. file(key存储在内存中,varlue即content存储在disk)
3. persistent(官方手册不建议使用)
4. mse(商业版varnish plus才提供) 所以我们之关注前两种存储方式如何配置使用。
配置举例:
VARNISH_STORAGE="malloc,256M"
VARNISH_STORAGE="file,/root/mycache.bin,256M" //启动varnishd时,存储缓存对象的文件即建立。要求所在的目录已经存在,否则出错。
在/etc/varnish下创建test.vcl,其内容如下:
vcl 4.0; //写在首个非注释行
backend default {
.host = "192.168.20.133";
.port = "80";
}
设置完成后,启动 systemctl start varnish.service ,在6B上启动Nginx并写一个index.html显示一行文本:This is Nginx test html page. 在6A上 curl 192.168.10.133,发现可以正常访问。在7A上执行 varnishstat 观察 MAIN.cache_miss=1,无 MAIN.cache_hit。 再在6A上执行 curl 192.168.10.133,此时7A上有MAIN.cache_hit=1 表明页面确实缓存了。(q键退出varnishstat)
===============
如何写 vcl 代码?
理解subroutine
下面看下如何写vcl文件,在写vcl文件之前,我们得先明白什么是“状态引擎”,这个词听上去有点装x,其实就是subroutine,也就是一段处理http请求的代码段而已。客户端的http请求到了varnish服务器,如何处理?查不查缓存?从backend拿到的数据,何时缓存何时不缓存?这些都可以通过vcl文件中的subroutine来控制。vcl对报文的处理颗粒度是每 req/resp/bereq/beresp 的,即客户端与varnish服务器间的请求/响应,varnish服务器与backend间的请求/响应,req/resp/bereq/beresp报文各自被单独处理,互不影响。
我们先看一段简单的代码,找找感觉。
sub vcl_recv {
if(req.method != "GET" && req.method != "HEAD"){
return (pass);
}
return (hash);
}
这段代码的意思就是vcl_recv这个subroutine对某次来自客户端的请求http报文检查其方法是否为GET或HEAD以判断接下来哪一个subroutine处理,如果不是则进入pass处理,如果是则进入hash处理。return()的括号中指定的是下一步处理动作,括号中的动作一般都是指示处理流程跳转到其他的subroutine中。代码中的 req.method 是内置变量,对每一个req/resp/bereq/beresp,varnish会把报文中的某些字段和内置变量做映射,读写这些内置变量就是读写http报文内容。
现在我们可以认为subroutine要完成的工作就是处理http报文,再讲的细一点就是,判断报文中的信息是否满足指定条件,满足的话如何处理,不满足的话如何处理。所以subroutine的结构很简单,就是判断+下一步动作,仅此而已。
subroutine分为内置subroutine和自定义subroutine,自定义的subroutine需要在内置subroutine中使用call调用之才能使用。varnish内置的subroutine是以vcl_开头的,而自定义的subroutine不能以vcl_开头。个人感觉,如果要处理的问题不复杂,不必自定义subroutine,直接将要处理的逻辑写在内置subroutine既可。
回头看看我们刚才做过的实验,在test.vcl下并没有加vcl代码,为什么页面依然被缓存了呢?就是因为有内置subroutine,而内置subroutine中有缺省的vcl代码。用varnishadm连接到本机的varnishd,然后执行
vcl.show -v boot就可以看到内置subroutine及其内部定义的缺省处理代码了。如果我们要把自己的vcl处理代码写到内置subroutine,如vcl_recv,如何操作?在test.vcl把你的处理代码直接加到sub vcl_recv后的{}中即可。内置subroutine中的缺省vcl代码总在我们的代码之后才执行(目的就是为了兜底),当然如果我们的代码执行过程中return到其他subroutine就另当别论了。
sub vcl_recv {
把你的处理代码写到这里
}
内置subroutine
vcl_recv
vcl_deliver
vcl_synth
vcl_hash
vcl_hit
vcl_miss
vcl_pass
vcl_pipe
vcl_purge
vcl_backend_fetch
vcl_backend_response
vcl_backend_error
内置函数:
regsub(str,regex,sub) //在字符串str中匹配模式regex,并将匹配到的第一个结果替换为sub
regsuball(str,regex,sub) //在字符串str中匹配模式regex,并将匹配到的所有结果替换为sub
ban(bollean expression) //清理缓存中满足表达式条件的缓存对象
hash_data(input)
systhetic(str)
内置关键字:
call subroutine
return(action) //这里的action就是下一步要处理的动作,即哪个subroutine要接续处理。合法的action有:
lookup,synth,purge,pass,pipe,fetch,deliver,hash,restart,retry,abandon。并非所有的action都对应一个subroutine
new
set
unset
常见的内置变量:
client.ip //客户端ip
req.backend_hint //要选择哪个后端资源服务器(或集群)做资源fetching
req.http.* //http头部
req.method //请求方法
req.url //请求的url
req.restarts //请求被重新投入状态机处理的次数
bereq.http.* //http头部
bereq.method //请求方法
bereq.url //请求的url
resp.http.* //响应报文的http头部
resp.status //相应给客户端的状态码
resp.reason //相应给客户端的原因短语
beresp.http.* //后端返回响应报文的http头部
beresp.status //后端返回的状态码
beresp.reason //后端返回的原因短语
beresp.backend.ip //后端资源服务器的ip
beresp.backend.name //后端资源服务器的name
beresp.ttl //资源的ttl值
beresp.grace //资源的grace值
beresp.keep //资源的keep值
beresp.uncacheable //置位则be-response中的对象将不被缓存
obj.hits //资源被命中的次数
obj.http.* //资源的http头部
obj.status //后端返回资源时给出的状态码
obj.reason //后端返回资源时给出的原因短语
obj.ttl //资源剩余的ttl值
obj.grace //资源剩余的grace值
obj.keep //资源剩余的keep值
obj.uncacheable //资源是否不被缓存的标志值
一般来讲变量req.*的值会赋给对应的bereq.*,而变量beresp.*的值会赋给对应的resp.* 改变前者会影响后者。obj.*的初始值大多来自beresp.*,它们可以被赋给resp.*并传给客户端浏览器缓存。
写完vcl后如何执行?
可以通过 varnishadm 连接到 varnishd,然后执行
vcl.load obj_name test.vcl 把test.vcl编译成名为obj_name(自己取名)的策略对象,然后使用
vcl.use obj_name 即可使用该策略对象。在这之前,请先使用 vcl.list 查看服务启动后使用的是哪一个策略对象,没错,名为boot的策略对象。
=====详解内置subroutine=====
典型的内置subroutine有如下几个:
vcl_recv
vcl_pass
vcl_backend_fetch
vcl_backend_response
vcl_hash
vcl_hit
vcl_miss
vcl_deliver
vcl_synth
内置rubroutine中有基于安全考虑加进去兜底的缺省vcl代码,所以官方手册强烈建议用户把自己的处理逻辑放到内置的vcl subroutine中。我们启动varnishd后,test.vcl会被变异并加载,通过varnishadm vcl.show -v boot 即可查看系统内置的vcl subroutine以及subroutine中缺省的vcl代码。
--------------------------------
vcl_recv
vcl_recv是客户端请求报文被解析后第一个被执行的subroutine,在该subroutine我们可以添加vcl代码完成诸多功能,如:
1.缓存未命中的话去后端哪台主机请求资源 2.控制缓存策略,如仅仅针对某些url做缓存 3.完成url重写 等功能。
在vcl_recv中我们可以return如下action:
pass:对于http请求,跳过缓存查找这一步去后端server请求资源,虽然没有跳过了查缓存这一步,但是后续的步骤该走的还是得走,该过的subroutine还得过。这种情况下从后端server拿到的资源不会被缓存。
pipe:对于http请求,跳过所有步骤,也就是不用过任何subtoutine的处理,直接去后端server请求资源,这种情况下拿到的资源也不缓存,就像经过varnish搭建了一条客户端到服务器的一条管道。且后续同一个tcp连接的所有request都会直接被送进管道处理。被pipe处理的请求不记录日志。
hash:进行哈西计算并查找缓存。
purge:在缓存中查找缓存对象并清除之。
synth:合成http响应报文,通常是错误报文,此外,synth也可以用于重定向客户端请求。
实例A:
sub vcl_recv {
if (req.httpd.User-Agent ~ "iPad"
req.httpd.User-Agent ~ "iPhone"
req.httpd.User-Agent ~ "Android") {
set req.http.X-Device = "mobile";
} else {
set req.http.X-Device = "desktop";
}
}
作用:根据用户请求报文中的User-Agent判断用户的浏览器类型为mobile或desktop,然后在请求报文中加入名为X-Device的头部,并设置其值为mobile或desktop,表示客户端平台。响应报文(无论来自缓存还是后端server)可以根据客户端平台类型构造并发送给客户端。
实例B:
sub vcl_recv {
set req.http.host = regsub(req.http.host,"^www\.","");
}
作用:把 www.xxx.yyy 按照xxx.yyy处理,如 www.web1.com 按照 web1.com 处理
实例C:
sub vcl_recv {
if (req.http.host == "sport.web1.com") {
set req.http.host = "web1.com";
set req.url = "/sport" + req.url;
}
}
作用:重写 http://sport.web1.com/ 到 http://web1.com/soprt/
实例D:
sub vcl_recv {
if (req.http.host ~ "^sport\.") {
set req.http.host = regsub(req.http.host,"^sport\.","");
set req.url = regsub(req.url,"^","/sport");
}
}
作用:重写 http://sport.xxxx/ 到 http://xxxx/sport/
--------------------------------
vcl_pass
当一个subroutine执行return(pass)时,即跳到vcl_pass执行处理逻辑,vcl_pass会把一个请求设置为pass模式,在vcl_pass中我们可以return: 1.fetch 2.synth 3.restart。 当return一个fetch时,被设置为pass模式的请求得到的对象不会被缓存而直接响应给客户端。返回synth时进入vcl_synth合成响应报文,返回restart则从状态机开始处再开启一轮处理请求报文的动作。
--------------------------------
补充:hit-for-pass
有些请求得到的响应对象不应该被缓存,一个典型的例子就是当响应报文中含有Set-Cookie头部时,因为该响应对象仅仅是针对单个用户的。这种场景下,我们可以设置varnish生成一个hit-for-pass对象,然后缓存之,而不是直接缓存响应对象。
当一个从后端server拿到的对象不需要被缓存时,我们可以 set bereq.uncacheable = true 这样的话Cacher Process就会维护一个指向hit-for-pass的键值对,当再次有请求查到该哈西键时,会找到一个hit-for-pass的缓存对象,然后跳转到vcl_pass处理,在vcl_pass中请求被设置为pass模式。
和正常的缓存对象一样,hit-for-pass也有其ttl,当ttl一过时一样会被从缓存区清理掉。
--------------------------------
vcl_backend_fetch
sub vcl_backend_fetch {
return (fetch);
}
vcl_backend_fetch可以在vcl_miss或vcl_pass中被调用(当然是通过return),当其被vcl_miss调用时在后端server拿到的对象会被缓存,而当其被vcl_pass调用时在后端拿到的对象就不会被缓存,即使对象的obj.ttl和obj.keep变量值大于0。
还有一个与缓存相关的变量 bereq.uncacheable, 该变量指明了后端返回的被请求的资源对象是否被缓存。然而,从pass中的请求得到的对象会忽略bereq.uncacheable的值,而不缓存之,上文也提到了。
vcl_backend_fetch中我们自己加入的代码可以return到fetch或者abandon。前者会将请求代理发送到后端,而后者会调用vcl_synth。vcl_backend_fetch中的缺省代码return的是fetch。来自后端的响应会被vcl_backend_response或vcl_backend_error处理,这取决于响应报文。
如果varnish接收到一个语法正确的http响应(含5xx错误码的http响应),则进入vcl_backend_response处理。若varnish没有收到http响应则进入vcl_backend_error处理。
--------------------------------
vcl_hash
vcl_hash的作用是对一个http请求做哈西计算。
缺省的vcl_recv代码是跳到vcl_hash的,任何subroutine都可以通过return(hash)跳转到vcl_hash。
内置的vcl_hash代码如下:
sub vcl_hash {
hash_date(req.url);
if (req.http.host) {
hash_data(req.http.host);
}
else {
hash_data(server.ip);
}
return (lookup);
}
vcl_hash为将要缓存的对象定义一个哈西键,缓存对象的键是特有的,不同的缓存对象具有不同的键。vcl_hash中的内置代码使用请求的url和hostname/IP来计算哈西键。
vcl_hash的一个用途就是使用user-name来计算哈西键以标识一个特定用户的数据,然而此功能应该谨慎使用。一个更好的替代方案是基于session来哈西某个对象。
vcl_hash运行到最后会return到lookup,lookup并不是subroutine,而只是一个操作。vcl_hash之后进入哪个subroutine处理,取决于lookup在缓存中找到了什么。
当lookup没有匹配到任何哈西键,它会创建一个具有busy标志的对象并把它扔到缓存区。之后跳到vcl_miss处理http请求,当http请求被后端处理后,缓存对象内容就会被后端返回的内容更新,同时busy标志也会被移除。
若一个请求命中了有busy标志的缓存对象,则该请求会被送到waiting list,waiting list是为了提高响应性能而设计的。
--------------------------------
vcl_hit
lookup若匹配到哈西键,则会跳转到vcl_hit。vcl_hit的默认代码如下:
sub vcl_hit {
if (obj.ttl >= 0s) {
return (deliver);
}
if (obj.ttl + obj.grace > 0s) {
return (deliver);
}
return (fetch);
}
vcl_hit执行到最后一般都是return: deliver,restart或synth。
deliver会使处理流程跳转到vcl_deliver,如果该对象的ttl+grace没有过时的话。{153页未翻译完}
restart是把http请求扔到状态机的入口当作一个新的http请求重新处理,同时restart counter这个计数器加一,还记得存放log的内存分为两部分吗?所有的counter都存储在第一部分。当restart counter的值高于 max_restarts 时,varnish会抛出一个guru meditation错误。(max_restarts是一个参数,可以通过varnishadm param.show max_restarts查看其值)
synth(status_code,reason)会丢弃本次request,并返回一个指定的http状态码给客户端。
--------------------------------
vcl_miss
lookup若没有匹配到哈西键,则会跳转到vcl_miss。
vcl_miss中可以加入代码,以决定是否去后端server请求资源,去哪台后端server请求资源。
vcl_miss的默认代码如下:
sub vcl_miss {
return (fetch);
}
我们很少在vcl_hit和vcl_miss这两个subroutine中添加自己的处理逻辑,因为对http请求头部的修改通常都是在vcl_recv中完成的。然而,如果不想让X-Varnish这个http头部发送给后端server的花,可以在vcl_miss或vcl_pass中通过 unset bereq.http.x-varnish; 来实现。
--------------------------------
vcl_deliver
通常来说,对于一个http请求流程,vcl_deliver都是最后一个处理动作。但是经由vcl_pipe代理转发到后端server的请求除外。
该subroutine常常被用来删除debug-headers
vcl_deliver的默认代码如下:
sub vcl_deliver {
return (deliver);
}
如果我们想修改响应给客户端的报文头部,如删除或增加一个新头部且不想改动后被缓存,则可以在此操作。在vcl_deliver中我们常常用到 rest.http.* , resp.status , resp.reason , obj.hits , req.restarts
--------------------------------
vcl_synth
生成含有指定内容的http响应报文,并通过return(deliver)发送给客户端。vcl_synth的默认代码如下:
sub vcl_synth {
set resp.http.Content-Type = "text/html; charset=utf-8";
set resp.http.Retry-After = "5";
synthetic( {"<!DOCTYPE html>
<html>
<head>
<title>"} + resp.status + " " + resp.reason + {"</title>
</head>
<body>
<h1>Error "} + resp.status + " " + resp.reason + {"</h1>
<p>"} + resp.reason + {"</p>
<h3>Guru Meditation:</h3>
<p>XID: "} + req.xid + {"</p>
<hr>
<p>Varnish cache server</p>
</body>
</html> "} );
return (deliver);
}
解释:设置http头部,然后调用synthetic()函数合成一个页面,然后通过return到deliver把页面发送到客户端。我们可以通过在指定的subroutine中return(synth(status_code,"reason_phrase")); 来调用vcl_synth并设置resp.http.status和resp.http.reason。需要注意的是这里return的不是keyword,而是一个内置的具有参数的函数。
{“ 和 ”}用来指示多行字符串
vcl_synth定义的页面对象不会被缓存,而vcl_backend_error定义的页面对象会被缓存。
--------------- 实例 -----------------
test.vcl中如下配置为公共部分,为节省版面,不重复写在下文实例中:
vcl 4.0;
backend default {
.host = "192.168.20.133";
.port = "80";
}
实例1:
sub vcl_recv {
if (req.http.host == "www.web1.com") {
return(synth(750,"Suibianxie."));
}
}
sub vcl_synth {
if (resp.status == 750) {
set resp.http.location = "http://web1.com" + req.url;
set resp.status = 301;
return (deliver);
}
}
作用:当客户端请求www.web1.com时,varnish会设置resp.status和resp.reason分别为750和Suibianxie,然后跳转到vcl_synth中开始合成页面并通过return到deliver把页面发送给客户端。
实例2:
sub vcl_deliver {
unset resp.http.Server;
if (obj.hits > 0) {
set resp.http.X-cache = "HIT";
} else {
set resp.http.X-cache = "MISS";
}
}
作用:给客户端的响应报文中增加一个X-cache头部,当请求的资源命中时该头部值为“HIT”,不命中时头部值为“MISS”。同时把响应报文中的Server头部去掉。
实例3:
sub vcl_backend_error {
if (beresp.status == 503) {
set beresp.status = 200;
synthetic(
{"
<html>
<body>
<h1>We don't like ugly page!</h1>
</body>
</html>
"}
);
return (deliver);
}
}
作用:varnish作为反代去向后端server拿数据,如果拿不到数据,则默认返回一个503的status code给客户端,同时给出一个预定义的页面(该页面是写在vcl_backend_error中的)。我们用实例3的代码重写该页面,给出200返回值和一个更加友好的页面。
至此vcl如何使用应该有个基本的认识了,下面通过实例加深对它的掌握。
================
vcl 代码使用实例:
-----
按需使缓存失效(清理缓存)
缓存失效是缓存策略的一个重要组成部分,varnish会使过期的缓存对象自动失效,我们可以手动设置使缓存对象失效。
1. HTTP PURGE
2. Banning
3. Force Cache Misses 强制不匹配
在vcl_recv中使用变量req.hash_always_miss 变量被设置为true,则varnish忽略已存在的对象而是从后端server请求之。 在vcl_recv中set req.hash_always_miss = true; 会使varnish去查缓存,但是强制不匹配,然后想后端请求资源并缓存,然后响应给客户端。
1.PURGE
一个资源返回给不同的客户端(手机,平板,桌面电脑)可能有不同的Vary头部,因此同一个资源在缓存中可能有多个不同的变体。通常来说HTTP PURGE会清理掉一个资源的所有的变体。就像GET一样,PURGE也是http的一个method,当请求某资源但携带的是PURGE方法时,该请求也会像正常请求一样被哈西计算,然后找到缓存中的对象并清除之。PURGE只能针对单个资源的缓存对象做清除,而不能使用正则表达式匹配清除一类缓存对象。而且并不检查后端server是否状态正常就直接清除,也就是说如果你的后端server挂了,再有请求相同资源的request到来,那就真的只能呵呵了。
通过使用return(purge)来执行某次请求的已缓存资源的清除,return(purge)后会进入vcl_purge继续后续处理,vcl_purge的缺省代码如下:
sub vcl_purge {
return (synth(200,"Purged,Haha"));
}
实例:
acl purgers { //设置acl,定义谁发送的PURGE可以被处理
"127.0.0.1";
"192.168.10.0/24";
}
sub vcl_recv {
if (req.method == "PURGE") {
if (!client.ip ~ purgers) {
return (synth(405,"Purge_Not_Allowed"));
}
return (purge);
}
}
sub vcl_purge {
set req.method = "GET";
return (restart);
}
作用:清除掉某个资源的缓存对象,然后把请求的方法设置为GET,再将请求重新扔到状态机入口从头开始新一轮的处理。这样就会在缓存区中生成一个新的缓存对象。一般来说,缓存对象未失效,但是后端server上的资源更新了,就可以这样操作更新缓存区的缓存对象。(感觉好麻烦,直接shift+F5强制刷新不行吗?)
注意哦,这里http的方法是PURGE是因为约定俗成,大家都这么用。其实改成HAHA,或者HEHE,也可以照常工作。让varnish检查req.method是否为HAHA或HEHE即可。
2.Banning
使用内置的变量ban(regex)
通过匹配正则表达式来失效某个缓存中的对象
通过varnishadm也可以使用banning
至此我们已经知道HTTP PURGE只能针对单个资源的缓存对象做清除操作,如果我们想要对满足某些条件的资源的缓存对象做清除操作怎么办?用Banning,因为它支持正则表达式。两种banning形式
a)通过varnishadm连接到varnishd,通过CLI接口执行 ban regexp,如 ban req.url ~ /image/a*\.jpg
b)通过ban("regexp");实现
sub vcl_recv {
if (req.method == "BAN") {
ban ("req.http.host ==" + req.http.host + "req.url ==" + req.url);
return (tynth(200,"Ban_Rule_Added"));
}
}
已缓存的对象,如果被匹配到,则会像其他obj.ttl==0的缓存对象一样被清除。
Lurker-friendly Ban
正则表达式仅匹配obj.*的ban我们称之为 Lurkerfriendly Ban。 ban lurker是Cacher Process的一个线程,它会定期检查缓存区中的obj是否匹配到表达式并处理之,检查间隔通过varnishadm中 ban_lurker_sleep 参数设置,如果设置为0表示不检查。
sub vcl_recv {
if (req.method=="BAN") {
ban("obj.http.x-url ~" + req.http.x-ban-url + "&& obj.http.x-host ~" + req.http.x-ban-host);
return (synth(200,"Ban_Added"));
}
}
sub vcl_backend_response {
set beresp.http.x-url=bereq.url;
set beresp.http.x-host=bereq.http.host; //beresp.*修改后会赋值给对应的obj.*
}
sub vcl_deliver {
unset resp.http.x-url;
unset resp.http.x-host;
}
通过 curl -X Your_Method http://www.web1.com 来在访问时指定方法,可以用cur -X来对PURGE和BAN进行测试。
-----
varnish作为调度
varnish毕竟不能缓存所有的内容,所以总会有到后端server取数据的时候,这时候就牵扯到调度问题,下面我们就来说说调度。
varnish的强项是缓存而非调度,所以它支持的调度算法有限,有如下几种:
1. round-robin
2. random(随机种子可以是随机数或者哈西键)
3. fallback(就找第一台,第一挂了找第二,第二挂了找第三)
4. hash(保证了会话粘性)
同时varnish应该对后端server集群有个健康状态探测机制,和keepalived一样能剔除有问题的后端server。
我们来看两个完整的例子:
vcl 4.0;
import directors;
backend bkd_srv1 { //注意:定义的backend后面都要被引用,否则报错(vcc_err_unref参数控制)
.host="www.web1.com";
.port="80";
.probe={
.url="/"; //探测粒度为url,还可以细化到req报文的请求方法和头部
.timeout=1s; //超市时间为1s
.interval=4s; //每4s探测一次
.window=5; //最近的5次探测,有3次ok就认为健康
.threshold 3;
}
}
backend bkd_srv2 {
.host="www.web2.com";
.port="80";
.probe={
.url="/"; //探测粒度为url,还可以细化到req报文的请求方法和头部
.timeout=1s; //超市时间为1s
.interval=4s; //每4s探测一次
.window=5; //最近的5次探测,有3次ok就认为健康
.threshold=3;
}
}
sub vcl_init {
new rr_dir = directors.round_robin();
rr_dir.add_backend(bkd_srv1);
rr_dir.add_backend(bkd_srv2);
new ran_dir = directors.random();
ran_dir.add_backend(bkd_srv1,10);
ran_dir.add_backend(bkd_srv2,5);
}
sub vcl_recv {
set req.backend_hint=rr_dir.backend(); //上面定义了两种调度,这里使用round-robin
//set req.backend_hint=ran_dir.backend(req.http.cookie); //这里的cookie也只是做随机种子而已
}
======
vcl 4.0;
import directors;
backend bkd_srv1 { //注意:定义的backend后面都要被引用,否则报错(vcc_err_unref参数控制)
.host="www.web1.com"; //得保证varnish可以解析该FQDN
.port="80";
.probe={
.url="/"; //探测粒度为url,还可以细化到req报文的请求方法和头部
.timeout=1s; //超市时间为1s
.interval=4s; //每4s探测一次
.window=5; //最近的5次探测,有3次ok就认为健康
.threshold 3;
}
}
backend bkd_srv2 {
.host="www.web2.com";
.port="80";
.probe={
.url="/"; //探测粒度为url,还可以细化到req报文的请求方法和头部
.timeout=1s; //超市时间为1s
.interval=4s; //每4s探测一次
.window=5; //最近的5次探测,有3次ok就认为健康
.threshold=3;
}
}
sub vcl_init {
new img_srvs = directors.random(); //定义集群,调度算法为随机
img_srvs.add_backend(bkd_srv1,5); //定义服务器集群成员,此处仅一台,权重为5
new app_srvs = directors.hash(); //定义集群,调度算法为哈西
app_srvs.add_backend(appsrv1,5); //定义服务器集群成员,此处仅一台,权重为5
}
sub vcl_recv {
if (req.url ~ "(?i)\.(jpg|jpeg|png|gif)$" {
set req.backend_hint = imgsrvs.backend(); //若请求的是图片,缓存不命中则被发往图片集群,集群内轮询
} else {
set req.backend_hint = appsrvs.backend(req.http.cookie); //其他请求法王另一个集群,可以根据cookie做会话粘性
}
}
-----
缓存资源的新鲜度
beresp.ttl标明再过多久资源对象就不新鲜了,对象不新鲜之后还会有个grace时间,某些场景下varnish可以使用处于grace状态的对象响应客户端。
sub vcl_hit {
if (obj.ttl >= 0s) {
return (deliver);
}
elsif (std.healthy(req.backend_hint)) {
return (fetch);
}
else {
if (obj.ttl+obj.grace>0s) {
return (deliver);
}
else {
return (synth(404,"IHAVENOTHING"));
}
}
}
作用:如果资源新鲜,则响应给客户端。如果不新鲜,看看能否去后端server拿,能拿到就缓存并发送给客户端。如果拿不到就看看是否过了grace时间,如果美国就返回之前缓存的对象,如果过了,就合成错误页面。
默认的obj.grace时间是10s,obj.ttl倒计时完之后,obj.grace就开始倒计时。这个定时器的值有三种方式设置:
1.来自后端server的Cache-Control中的stale-while-revalidate
2.在vcl代码中设置beresp.grace变量的值
3.varnishadm中改变default值:param.set default_grace 20s //改为20s

这篇文章中没有涉及日志查询如何使用,有很多知识点还可以更细化,留给下一篇文章吧。
另附上两张状态引擎处理报文的流程图,这两张图务必要非常熟悉。
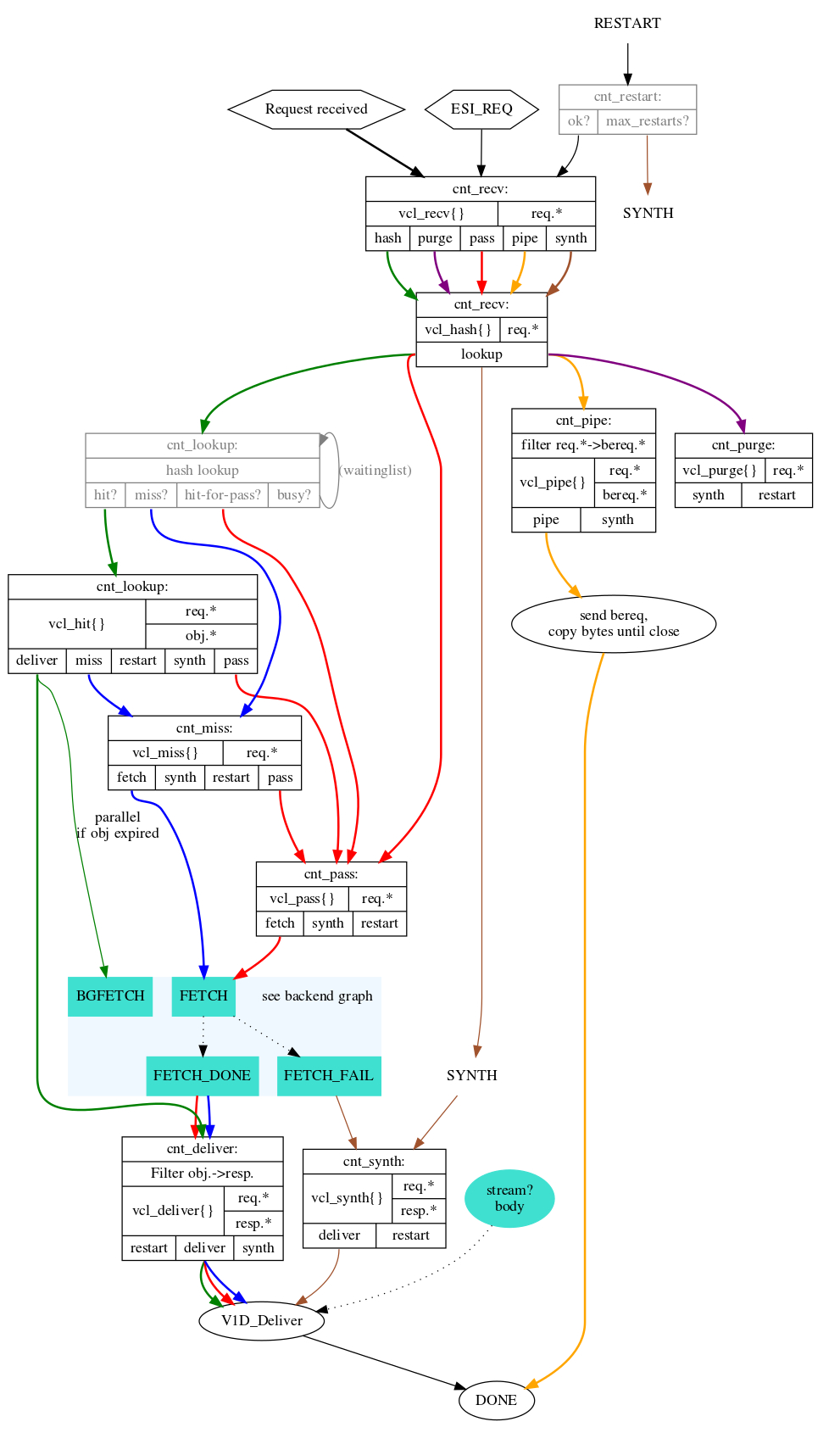
















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









