






因为资源有限,不再设置新的节点来代替原来的namenode,所以在原来namenode节点上,
将dfs.name.dir指定的目录中(这里是name目录)的内容清空,以此来模拟故障发生。

方法一:将集群关闭后,再重新启动我们会看到namenode守护进程消失
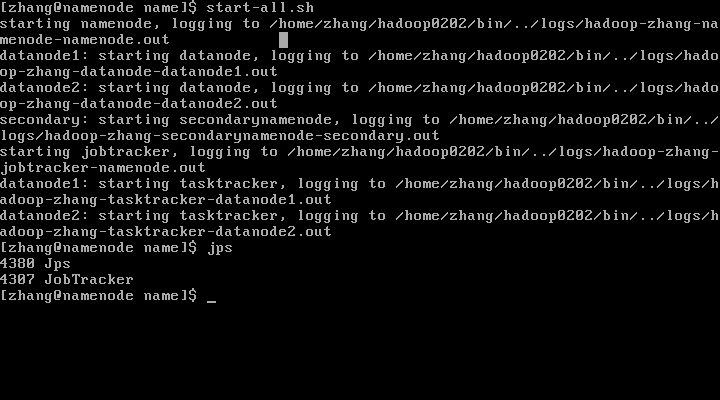
并且查看HDFS中的文件失败

关闭集群,格式化namenode

从任意datanode中获取namenode格式化之前namespaceID 并修改namenode的namespaceID跟datanode一致
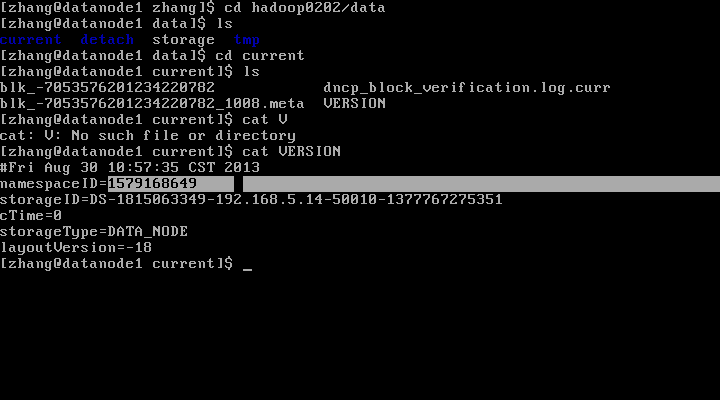
修改namenode的namespaceID
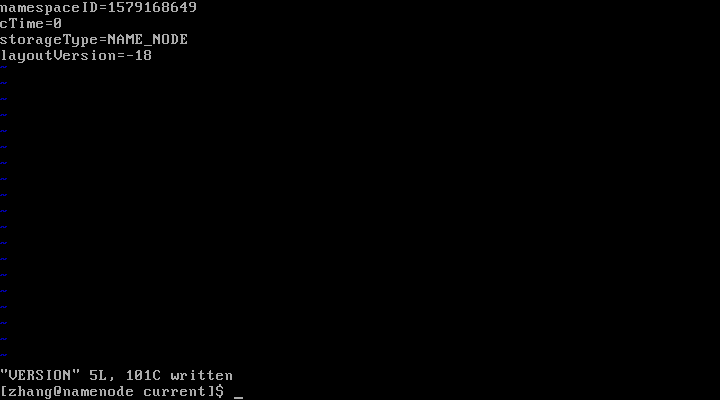
删除新NameNode 的 fsimage文件
从 SecondaryNameNode 拷贝fsimage 到 NameNode的current目录下
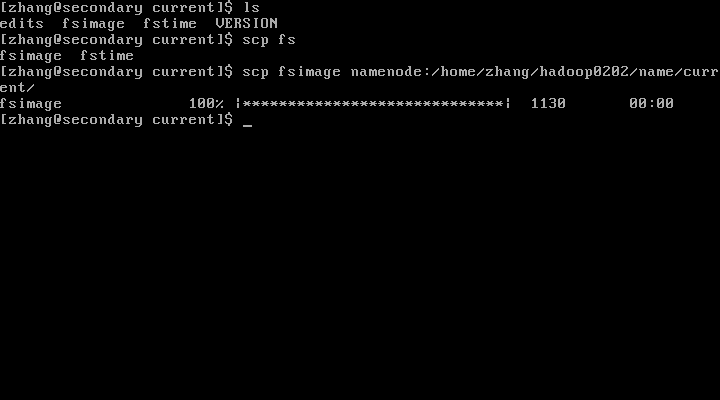
重启集群
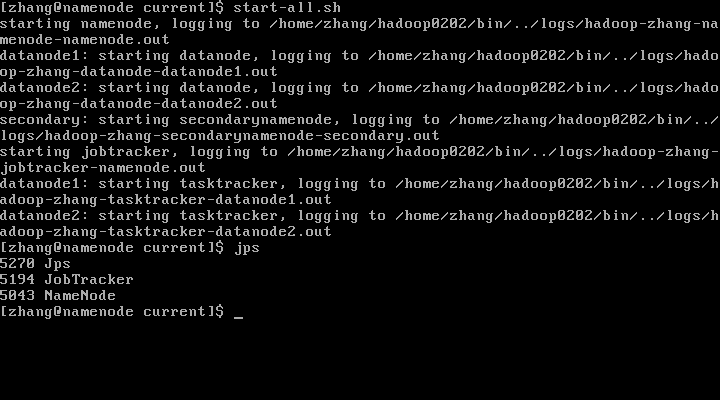
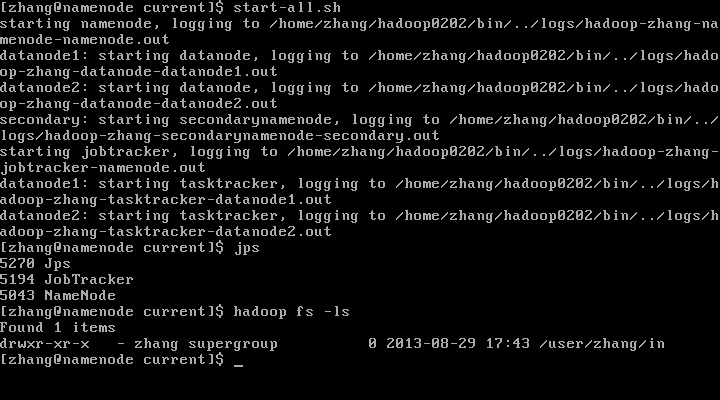
此时就恢复好了,并且可以查看hdfs上的文件和目录了。
方法二
方法二需要说明的是:
(1)集群崩溃之前,要确保在namenode的core-siet.xml文件中配置fs.checkpoint.dir,
创建相应的文件夹。(本来fs.checkpoint.dir配置只需要在secondarynamenode中配置的,
这里还不太清楚为什么这里还要配置)
(2)dfs.name.dir目录下的内容一定全部删除干净(此处恰好是崩溃的原因,如果不是也要删除干净)
执行如下:
1、把SecondaryNameNode节点中 fs.checkpoint.dir的所有内容拷贝到新的NameNode
节点的 fs.checkpoint.dir指定目录中
2、在namenode节点上执行 hadoop namenode -importCheckpoint
此命令是将fnamenode节点上s.checkpoint.dir目录中的内容恢复dfs.name.dir所指定的目录中
(这里可能解释了为什么要在namenode中配置fs.checkpoint.dir了)
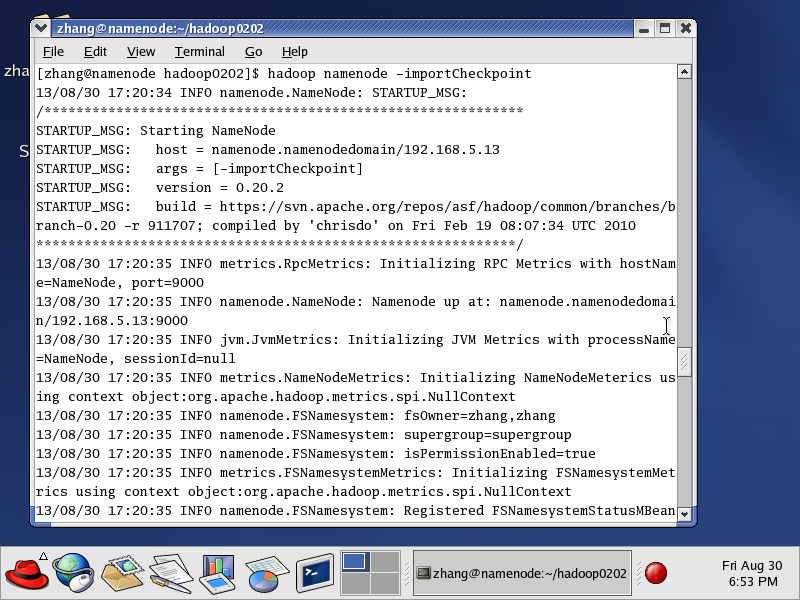
出现最后一个starting结尾的语句之后,可能要进入等待,
这时候可以按ctrl+c 跳出。
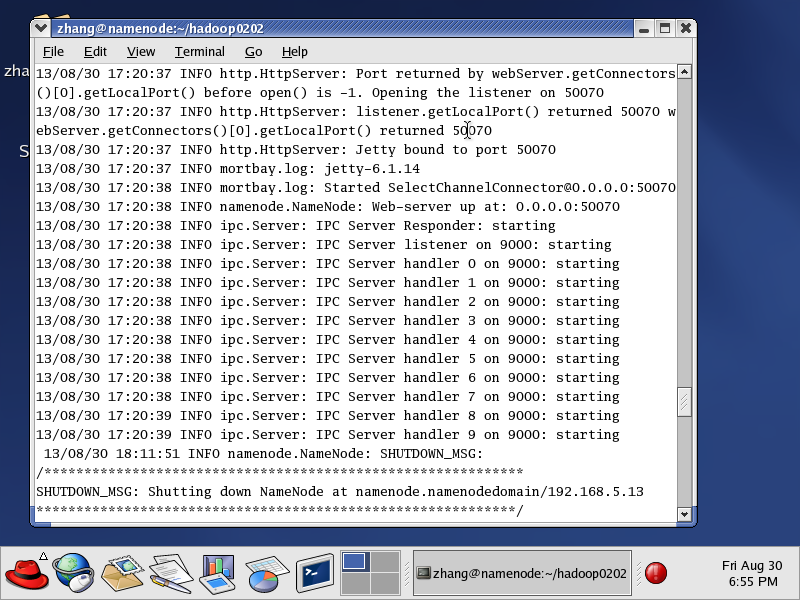
这时候重启集群
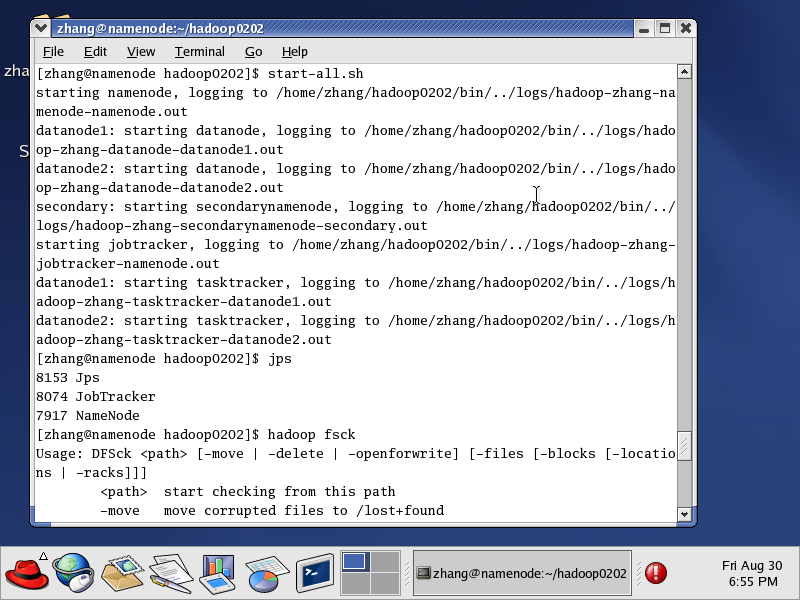
可以看到NameNode进程在运行了
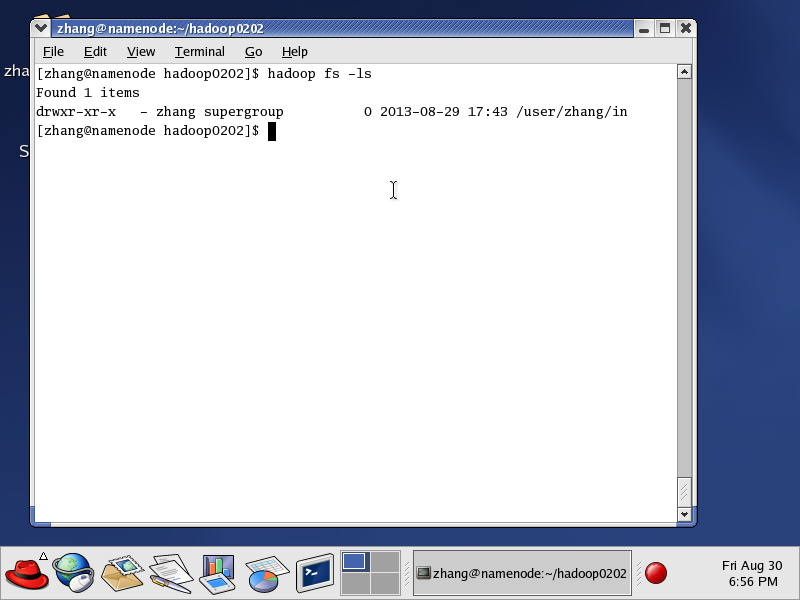
此种方法可以不进行namenode的格式化
注意:恢复的namenode中 secondarynamenode的最近一次check到故障发生这段时间的内容将丢失,
所以fs.checkpoint.period参数值在实际设定中要尽可能的权衡。并且也时常备份secondarynamenode
节点中的内容,因为secondarynamenode也是单点的,以防发生故障。
补充说明:如果是用新的节点来恢复namenode,则要注意
1、 新节点的Linux环境,目录结构,环境变量等等配置需要跟原来的namenode一模一样,
包括conf目录下的所有文件配置。
2、 新namenode的主机名要与原namenode保持一致,如果是重新命名主机名的话,则需要批量
替换datanode和secondarynamenode的 hosts文件,并且重新配置以下文件的部分
core-site.xml文件中的fs.default.name
hdfs-site.xm文件中的 dfs.http.address (secondarynamenode节点上)
mapred-site.xml文件中的mapred.job.tracker(如果jobtracker与namenode在同一台机器上,
一般都在同一台机器上)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









