







一、概述
Sqoop即SQL-to-Hadoop,是连接传统关系型数据库和Hadoop 的桥梁,用于把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS HBase 和 Hive) 中;也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。Sqoop利用MapReduce加快数据传输速度,并且采用批处理方式进行数据传输。
Sqoop具有以下优势:
- 高效、可控地利用资源,例如任务并行度,超时时间等
- 可自行设置数据类型映射与转换
- 可自动进行,用户也可自定义
- 支持多种数据库,例如:MySQL,Oracle,PostgreSQL等。
二、Sqoop的基本架构和操作
Sqoop的基本架构图如下:
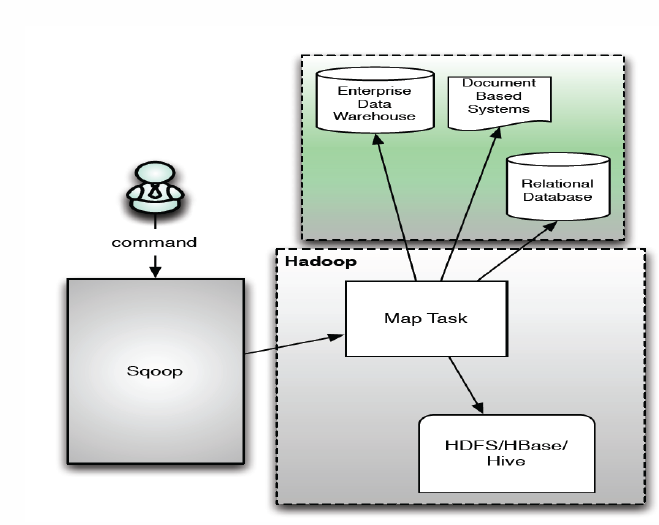
1、运行流程
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。其运行流程如下:
1.读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
2.设置好job,主要也就是设置好以上第六章中的各个参数
3.这里就由Hadoop来执行MapReduce来执行Import命令了,
1)首先要对数据进行切分,也就是DataSplit
DataDrivenDBInputFormat.getSplits(JobContext job)2)切分好范围后,写入范围,以便读取
DataDrivenDBInputFormat.write(DataOutput output) 这里是lowerBoundQuery and upperBoundQuery
3)读取以上2)写入的范围
DataDrivenDBInputFormat.readFields(DataInput input)4)然后创建RecordReader从数据库中读取数据
DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)5)创建Map
TextImportMapper.setup(Context context)6)RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给Map
DBRecordReader.nextKeyValue()7)运行map
TextImportMapper.map(LongWritable key, SqoopRecord val, Context context)最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()
2、命令详解
Sqoop总共有14个命令,包括:codegen,create-hive-table, eval, export, help, import, import-all-tables, import-mainframe, job, list-databases, list-tables, merge, metastore, version。其中常用命令为create-hive-table, export, import, help等。
sqoop命令格式:sqoop <command> <generic-options> <command-options>,也就是说sqoop的所有命令有公用的参数列表,除此之外每个命令都有自己特定的执行参数。
- help
help命令主要作用是查看sqoop提供的帮助信息,命令格式如下:sqoop help [<command>]。
help后面的参数为sqoop支持的命令名称。如果不给定help后面的参数,那么表示显示sqoop命令的帮助信息,如果给定后面的参数,那么表示显示具体sqoop命令的帮助信息。 实例:
1. sqoop help
2. sqoop help list-tables- list-tables&list-databases
list-tables和list-databases两个命令都是针对关系型数据库(可以通过jdbc连接的数据库/数据仓库)而言的,我们一般可以通过该命令查看对应数据库中的table&database的列表。基本命令格式为: sqoop (list-tables|list-databases) --connect jdbc_url --username user_name --password user_pwd
实例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









