






点击上方 "程序员小乐",关注公众号
8点20分,第一时间与你相约
每日英文
The most precious thing is not what you have, but the people around you. You can't force people to love you,but you can work hard to be a person who worth to be loved.
最宝贵的东西不是你拥有的物质,而是陪伴在你身边的人。不能强迫别人来爱自己,只能努力让自己成为值得爱的人。
每日掏心话
思索人生,是一种精神性活动,再执着的未来,也会有以往;生活才是讲故事的真正高手。
来自:超级小小黑 | 责编:乐乐
链接:cnblogs.com/hello-shf/p/11342907.html

图片来自 Pexels
祝大家周日愉快,往日回顾干货文章,看看有没有你错过?
更多精彩干货查看历史文章,一切贵在坚持,加油 。
。
01 简介
之前小乐发了有几篇关于二叉搜索树的文章(深入理解树(二叉、二叉搜索树)、深入剖析二分搜索树的原理与Java源码实现),没看的可以去了解下。今天小乐再次发篇,让我们从新学习巩固下。
本文将从二叉搜索树的定义和性质入手,带领大家实现一个二分搜索树,通过代码实现让大家深度认识二分搜索树。
后面会持续更新数据结构相关的博文。
数据结构专栏:https://www.cnblogs.com/hello-shf/category/1519192.html
git传送门:https://github.com/hello-shf/data-structure.git
02 二叉树
说树这种结构之前,我们要先说一下树这种结构存在的意义。在我们的现实场景中,比如图书馆,我们可以根据分类快速找到我们想要找到的书籍。比如我们要找一本叫做《Java编程思想》这本书,我们只需要根据,理工科 ==> 计算机 ==>Java语言分区就可以快速找到我们想要的这本书。这样我们就不需要像数组或者链表这种结构,我们需要遍历一遍才能找到我们想要的东西。再比如,我们所使用的电脑的文件夹目录本身也是一种树的结构。
从上面的描述我们可知,树这种结构具备天然的高效性可以巧妙的避开我们不关心的东西,只需要根据我们的线索快速去定位我们的目标。所以说树代表着一种高效。
在了解二分搜索树之前,我们不得不了解一下二叉树,因为二叉树是实现二分搜索树的基础。就像我们后面会详细讲解和实现AVL(平衡二叉树),红黑树等树结构,你不得不在此之前学习二分搜索树一样,他们都是互为基础的。
2.1、二叉树的定义:
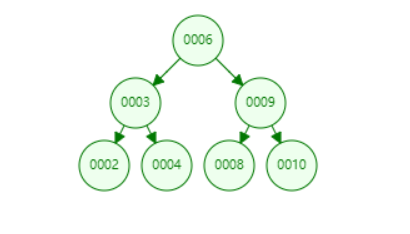
二叉树也是一种动态的数据结构。每个节点只有两个叉,也就是两个孩子节点,分别叫做左孩子,右孩子,而没有一个孩子的节点叫做叶子节点。每个节点最多有一个父亲节点,最多有两个孩子节点(也可以没有孩子节点或者只有一个孩子节点)。对于二叉树的定义我们不通过复杂的数学表达式来叙述,而是通过简单的描述,让大家了解一个二叉树长什么样子。
1 只有一个根节点。
2 每个节点至多有两个孩子节点,分别叫左孩子或者右孩子。(左右孩子节点没有大小之分哦)
3 每个子树也都是一个二叉树
满足以上三条定义的就是一个二叉树。如下图所示,就是一颗二叉树
2.2、二叉树的类型
根据二叉树的节点分布大概可以分为以下三种二叉树:完全二叉树,满二叉树,平衡二叉树。对于以下树的描述不使用数学表达式或者专业术语,因为那样很难让人想象到一棵树到底长什么样子。
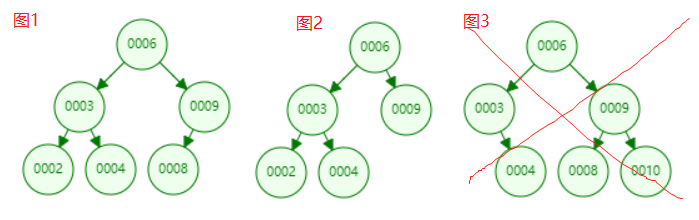
满二叉树:从根节点到每一个叶子节点所经过的节点数都是相同的。
如下图所示就是一颗满二叉树。

完全二叉树:除去最后一层叶子节点,就是一颗完全二叉树,并且最后一层的节点只能集中在左侧。
对于上面的性质,我们从另一个角度来说就是将满二叉树的叶子节点从右往左删除若干个后就变成了一棵完全二叉树,也就是说,满二叉树一定是一棵完全二叉树,反之不成立。如下图所示:除了图3都是一棵完全二叉树。
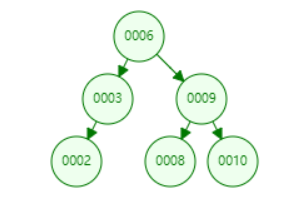
平衡二叉树:平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉树,又是一棵二分搜索树,平衡二叉树的任意一个节点的左右两个子树的高度差的绝对值不超过1,即左右两个子树都是一棵平衡二叉树。
03 二分搜索树
3.1、二分搜索树的定义
1 二分搜索树是一颗二叉树
2 二分搜索树每个节点的左子树的值都小于该节点的值,每个节点右子树的值都大于该节点的值
3 任意一个节点的每棵子树都满足二分搜索树的定义
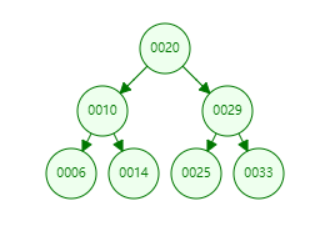
上面我们给出了二分搜索树的定义,根据定义我们可知,二分搜索树是一种具备可比较性的树,左孩子 < 当前节点 < 右孩子。这种可比较性为我们提供了一种高效的查找数据的能力。比如,对于下图所示的二分搜索树,如果我们想要查询数据14,通过比较,14 < 20 找到 10,14 > 10。只经过上面的两步,我们就找到了14这个元素,如下面gif所示。可见二分搜索树的查询是多么的高效。
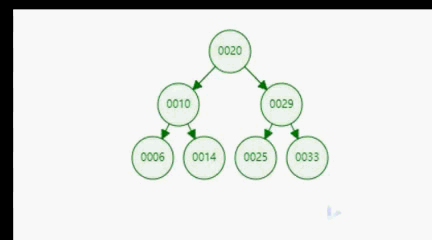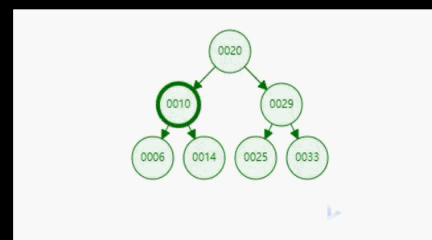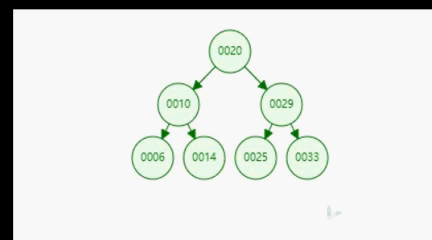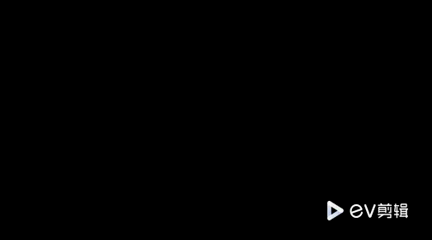
3.2、二分搜索树的实现
本章我们的重点是实现一个二分搜索树,那我们规定该二分搜索树应该具备以下功能:
1 以Node作为链表的基础存储结构
2 使用泛型,并要求该泛型必须实现Comparable接口
3 基本操作:增删改查
3.2.1、基础结构实现
通过上面的分析,我们可知,如果我们要实现一个二分搜索树,我们需要我们的节点有左右两个孩子节点。
根据要求和定义,构建我们的基础代码如下:
/*** 描述:二叉树的实现* 需要泛型是可比较的,也就是泛型必须实现Comparable接口** @Author shf* @Date 2019/7/22 9:53* @Version V1.0**/public class BST<E extends Comparable> {/*** 节点内部类*/private class Node{private E e;private Node left, right;//左右孩子节点public Node(E e){this.e = e;this.left = right;}}/*** BST的根节点*/private Node root;/*** 记录BST的 size*/private int size;public BST(){root = null;size = 0;}/*** 对外提供的获取 size 的方法* @return*/public int size(){return size;}/*** 二分搜索树是否为空* @return*/public boolean isEmpty(){return size == 0;}}
对于二分搜索树这种结构我们要明确的是,树是一种天然的可递归的结构,为什么这么说呢,大家想想二分搜索树的每一棵子树也是一棵二分搜索树,刚好迎合了递归的思想就是将大任务无限拆分为一个个小任务,直到求出问题的解,然后再向上叠加。所以在后面的操作中,我们都通过递归实现。相信大家看了以下实现后会对递归有一个深层次的理解。
3.2.2、增
为了让大家对二分搜索树有一个直观的认识,我们向二分搜索树依次添加[20,10,6,14,29,25,33]7个元素。我们来看一下这个添加的过程。
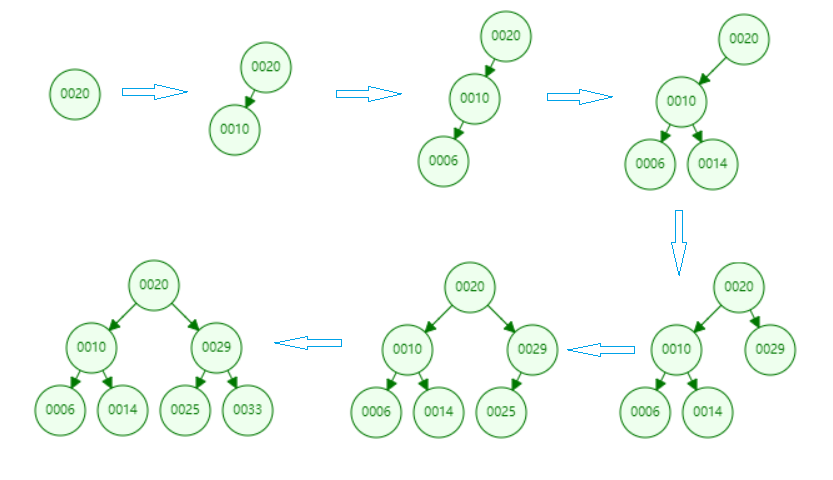
增加操作和上面的搜索操作基本是一样的,首先我们要先找到我们要添加的元素需要放到什么位置,这个过程其实就是搜索的过程,比如我们要在上图中的基础上继续添加一个元素15。如下图所示,我们经过一路寻找,最终找到节点14,我们15>14所以需要将15节点放到14节点的右孩子处。
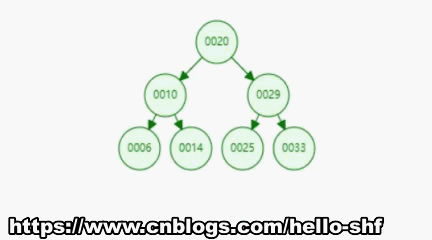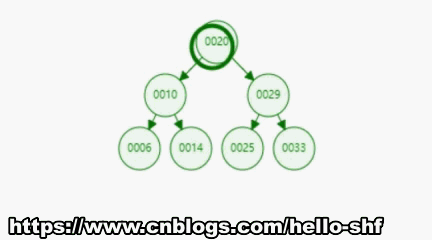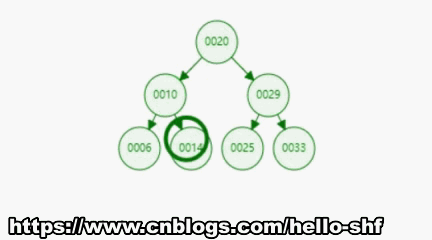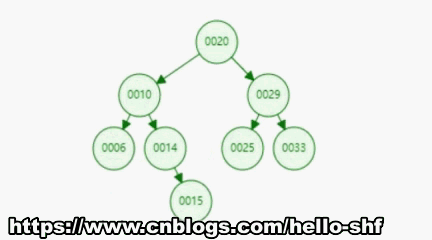
有了以上的基本认识,我们通过代码实现一下这个过程。
/*** 添加元素* @param e*/public void add(E e){root = add(root, e);}/*** 添加元素 - 递归实现* 时间复杂度 O(log n)* @param node* @param e* @return 返回根节点*/public Node add(Node node, E e){if(node == null){// 如果当前节点为空,则将要添加的节点放到当前节点处size ++;return new Node(e);}if(e.compareTo(node.e) < 0){// 如果小于当前节点,递归左孩子node.left = add(node.left, e);} else if(e.compareTo(node.e) > 0){// 如果大于当前节点,递归右孩子node.right = add(node.right, e);}return node;}
如果你还不是很理解上面的递归过程,我们从宏观角度分析一下,首先明确 add(Node node, E e) 这个方法是干什么的,这个方法接收两个参数 node和e,如果node为null,则我们将实例化node。我们的递归过程正是这样,如果node不为空并按照大小关系去找到左孩子节点还是右孩子,然后对该孩子节点继续执行 add(Node node, E e) 操作,通过按照大小规则一路查找直到找到一个符合条件的节点并且该节点为null,执行node的实例化即可。
如果看了上面的解释你还是有点懵,没问题,继续往下看。刘慈欣的《三体》不仅让中国的硬科幻登上了世界的舞台,更是给广大读者普及了诸如“降维打击”之类的热门概念。“降维打击”之所以给人如此之震撼,在于它以极简的方式,从更高的、全新的技术视角有效解决了当前困局。那么在算法的世界中,“递归”就是这种牛叉哄哄的“降维打击”技术。递归思想及:当前问题的求解是否可以由规模小一点的问题求解叠加而来,后者是否可以再由更小一点的问题求解叠加而来……依此类推,直到收敛为一个极简的出口问题的求解。如果你能从这段话归纳出递归就是一种将大的问题不断的进行拆分为更小的问题,直到拆分到找到问题的解,然后再向大的问题逐层叠加而最终求得递归的解。
看了以上解释相信大家应该对以上递归过程有了一个深层次的理解。如果大家还有疑问建议画一画递归树,通过压栈和出栈以及堆内存变化的方式详细分析每一个步骤即可。在我之前写的文章,在分析链表反转的时候对递归的微观过程进行了详细的分析,希望对大家有所帮助。
3.2.3、查
有了上面的基础我们实现一个查询的方式,应该也不存在很大的难度了。我们设计一个方法叫 contains 即判断是否存在某个元素。
/*** 搜索二分搜索树中是否包含元素 e* @param e* @return*/public boolean contains(E e){return contains(root, e);}/*** 搜索二分搜索树中是否包含元素 e* 时间复杂度 O(log n)* @param node* @param e* @return*/public boolean contains(Node node, E e){if(node == null){return false;} else if(e.compareTo(node.e) == 0){return true;} else if(e.compareTo(node.e) < 0){return contains(node.left, e);} else {return contains(node.right, e);}}
从上面代码我们不难发现其实和add方法的递归思想是一样的。那在此我们就不做详细解释了。
为了后面代码的实现,我们再设计两个方法,即查找树中的最大和最小元素。
通过二分搜索树的定义我们不难发现,左孩子 < 当前节点 < 右孩子。按照这个顺序,对于一棵二分搜索树中最小的那个元素就是左边的那个元素,最大的元素就是最右边的那个元素。
通过下图我们不难发现,最大的和最小的节点都符合我们上面的分析,最小的在最左边,最大的在最右边,但不一定都是叶子节点。比如图1中的6和33元素都不是叶子节点。
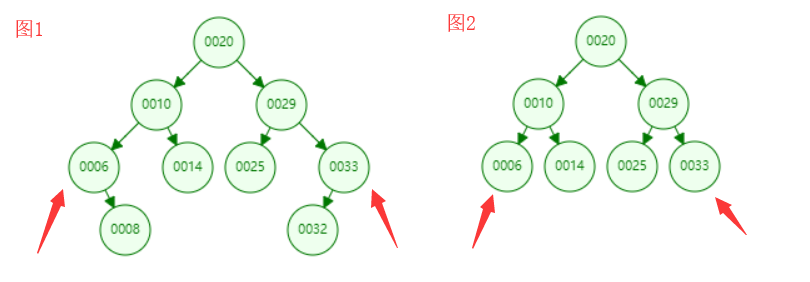
通过上面的分析,我们应该能很容易的想到,查询最小元素,就是使用递归从根节点开始,一直递归左孩子,直到一个节点的左孩子为null。我们就找到了该最小节点。查询最大值同理。
/*** 搜索二分搜索树中以 node 为根节点的最小值所在的节点* @param node* @return*/private Node minimum(Node node){if(node.left == null){return node;}return minimum(node.left);}/*** 搜索二分搜索树中的最大值* @return*/public E maximum(){if (size == 0){throw new IllegalArgumentException("BST is empty");}return maximum(root).e;}/*** 搜索二分搜索树中以 node 为根节点的最大值所在的节点* @param node* @return*/private Node maximum(Node node){if(node.right == null){return node;}return maximum(node.right);}
3.2.4、删
删除操作我们设计三个方法,即:删除最小,删除最大,删除任意一个元素。
3.2.4.1、删除最大最小元素
通过对上面3.2.3中的查最大和最小元素我们不难想到首先我们要找到最大或者最小元素。
如3.2.3中的图2所示,如果待删除的最大最小节点如果没有叶子节点直接删除。但是如图1所示,如果待删除的最大最小元素还有孩子节点,我们该如何处理呢?对于删除最小元素,我们需要将该节点的右孩子节点提到被删除元素的呃位置,删除最大元素同理。然后我们再看看图2所示的情况,使用图1的删除方式,也就是对于删除最小元素,将该节点的右孩子节点提到该元素位置即可,只不过对于图2的情况,右孩子节点为null而已。
/*** 删除二分搜索树中的最小值* @return*/public E removeMin(){if (size == 0){throw new IllegalArgumentException("BST is empty");}E e = minimum();root = removeMin(root);return e;}/*** 删除二分搜索树中以 node 为根节点的最小节点* @param node* @return 删除后新的二分搜索树的跟*///// 12 12 //// / \ / \ //// 8 18 -----> 10 18 //// \ / / //// 10 15 15 ////private Node removeMin(Node node){if(node.left == null){Node rightNode = node.right;// 将node.right(10) 赋值给 rightNode 保存node.right = null;// 将node的right与树断开连接size --;return rightNode; // rightNode(10)返回给递归的上一层,赋值给 12 元素的左节点。}node.left = removeMin(node.left);return node;}public E removeMax(){E e = maximum();root = removeMax(root);return e;}/*** 删除二分搜索树中以 node 为根节点的最小节点* @param node* @return*///// 12 12 //// / \ / \ //// 8 18 -----> 8 15 //// \ / \ //// 10 15 10 ////private Node removeMax(Node node){if(node.right == null){Node leftNode = node.left; // 将node.right(15) 赋值给 leftNode 保存node.left = null;// 将 node 的 left 与树断开连接size --;return leftNode; // leftNode (10)返回给递归的上一层,赋值给 12 元素的右节点。}node.right = removeMax(node.right);return node;}
3.2.4.2、删除指定元素
待删除元素可能存在的情况如下:
1 第一种,只有左孩子;
2 第二种,只有右孩子;
3 第三种,左右孩子都有;
4 第四种,待删除元素为叶子节点;
第一种情况和第二种情况的树形状类似3.2.3中的图1,其实他们的处理方式和删除最大最小元素的处理方式是一样的。这个就不过多解释了,大家可以自己手动画出来一棵树试试。那对于第四种情况就是第一种或者第二种的特殊情况了,也不需要特殊处理。和3.2.3中的图1和图2的处理方式都是一样的。
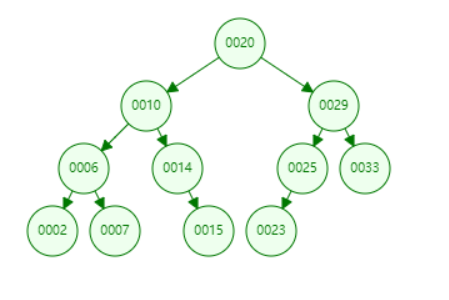
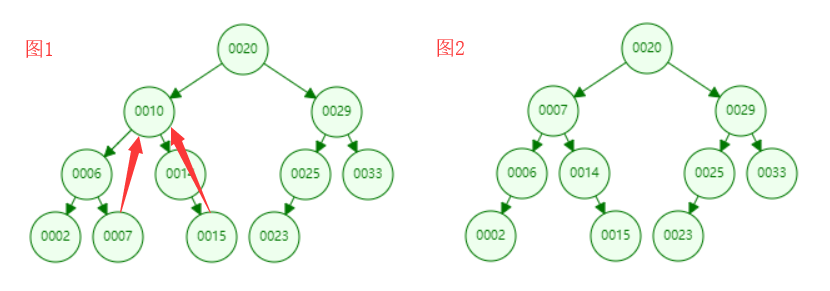
那我们重点说一下第三种情况,这个情况有点复杂。如上图所示,如果我们想删除元素10,我们该怎么做呢?我们通过二分搜索树的定义分析一下,其实很简单。首先10这个元素一定是大于他的左子树的任意一个节点,并小于右子树的任意一个节点。那我们删除了10这个元素,仍然不能打破平衡二叉树的性质。一般思路,我们得想办法找个元素顶替下10这个元素。找谁呢?这个元素放到10元素的位置以后,仍然还能保证大于左子树的任意元素,小于右子树的任意元素。所以我们很容易想到找左子树中的最大元素,或者找右子树中的最小元素来顶替10的位置,如下图1所示。
如下图所示,首先我们用7顶替10的位置,如下图2所示。我们删除了10这个元素后,用左子树的最大元素替代10,依然能满足二分搜索树的定义。同理我们用右孩子最小的节点替换被删除的元素也是完全可以的。在我们后面的代码实现中,我们使用右孩子最小的节点替换被删除的元素。
/*** 从二分搜索树中删除元素为e的节点* @param e*/public void remove(E e){root = remove(root, e);}/*** 删除掉以node为根的二分搜索树中值为e的节点, 递归算法* @param node* @param e* @return 返回删除节点后新的二分搜索树的根*/private Node remove(Node node, E e){if( node == null )return null;if( e.compareTo(node.e) < 0 ){node.left = remove(node.left , e);return node;} else if(e.compareTo(node.e) > 0 ){node.right = remove(node.right, e);return node;} else{ // e.compareTo(node.e) == 0 找到待删除的节点 node// 待删除节点左子树为空,直接将右孩子替代当前节点if(node.left == null){Node rightNode = node.right;node.right = null;size --;return rightNode;}// 待删除节点右子树为空,直接将左孩子替代当前节点if(node.right == null){Node leftNode = node.left;node.left = null;size --;return leftNode;}// 待删除节点左右子树均不为空// 找到右子树最小的元素,替代待删除节点Node successor = minimum(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}
04 二分搜索树的遍历
二分搜索树的遍历大概可以分为一下几种:
1,深度优先遍历:
(1)前序遍历:父节点,左孩子,右孩子
(2)中序遍历:左孩子,父节点,右孩子
(3)后序遍历:左孩子,右孩子,父节点
2,广度优先遍历:按树的高度从左至右进行遍历
如上所示,大类分为深度优先和广度优先,深度有点的三种方式,大家不难发现,其实就是遍历父节点的时机。广度优先呢就是按照树的层级,一层一层的进行遍历。
4.1、深度优先遍历
4.1.1、前序遍历
前序遍历是按照:父节点,左孩子,右孩子的顺序对节点进行遍历,所以按照这个顺序对于如下图所示的一棵树,前序遍历,应该是按照编号所示的顺序进行遍历的。
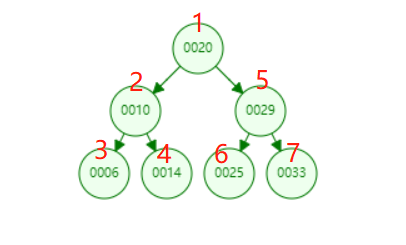
递归实现:虽然看着很复杂,其实递归代码实现是十分简单的。看代码吧,请别惊掉下巴。
/*** 前序遍历*/public void preOrder(){preOrder(root);}/*** 前序遍历 - 递归算法* @param node 开始遍历的根节点*/private void preOrder(Node node){if(node == null){return;}// 不做复杂的操作,仅仅将遍历到的元素进行打印System.out.println(node.e);preOrder(node.left);preOrder(node.right);}-------------前序遍历------------101425
非递归实现:如果我们不使用递归如何实现呢?可是使用栈来实现,这是一个技巧,当我们需要按照代码执行的顺序记录(缓存)变量的时候,栈是一种再好不过的数据结构了。这也是栈的天然优势,因为JVM的栈内存正是栈这种数据结构。
从根节点开始,每次迭代弹出当前栈顶元素,并将其孩子节点压入栈中,先压右孩子再压左孩子。为什么是先右孩子再左孩子?因为栈是后进先出的数据结构。
/*** 前序遍历 - 非递归*/public void preOrderNR(){preOrderNR(root);}/*** 前序遍历 - 非递归实现*/private void preOrderNR(Node node){Stack<Node> stack = new Stack<>();stack.push(node);while (!stack.isEmpty()){Node cur = stack.pop();System.out.println(cur.e);if(cur.right != null){stack.push(cur.right);}if(cur.left != null){stack.push(cur.left);}}}
4.1.2、中序遍历
中序遍历:左孩子,父节点,右孩子。按照这个顺序,我们不难画出下图。红色数字表示遍历的顺序。
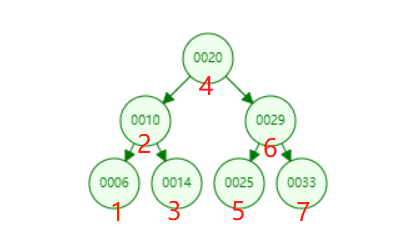
递归实现:
/*** 二分搜索树的中序遍历*/public void inOrder(){inOrder(root);}/*** 中序遍历 - 递归* @param node*/private void inOrder(Node node){if(node == null){return;}inOrder(node.left);System.out.println(node.e);inOrder(node.right);}-------------中序遍历------------102029
我们观察上面的遍历结果,不难发现一个现象,打印结果正是按照从小到大的顺序。其实这也是二分搜索树的一个性质,因为我们是按照:左孩子,父节点,右孩子。我们二分搜索树的其中一个定义:二分搜索树每个节点的左子树的值都小于该节点的值,每个节点右子树的值都大于该节点的值。
非递归实现:依然是用栈保存。
/*** 中序遍历 - 非递归*/public void inOrderNR(){inOrderNR(root);}/*** 中序遍历 - 非递归实现* 时间复杂度 O(n)* @param node*/private void inOrderNR(Node node){Stack<Node> stack = new Stack<>();while(node != null || !stack.isEmpty()){while(node != null){stack.push(node);node = node.left;}node = stack.pop();System.out.println(node.e);node = node.right;}}
4.1.3、后序遍历
后序遍历:左孩子,右孩子,父节点。遍历顺序如下图所示。
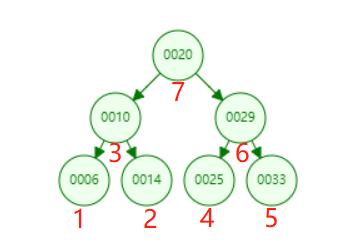
/*** 后序遍历*/public void postOrder(){postOrder(root);}/*** 后续遍历 - 递归* 时间复杂度 O(n)* @param node*/public void postOrder(Node node){if(node == null){return;}postOrder(node.left);postOrder(node.right);System.out.println(node.e);}-------------后序遍历------------6141025332920
非递归实现:
/*** 后序遍历 - 非递归*/public void postOrderNR(){postOrderNR(root);}/*** 后序遍历 - 非递归实现* 时间复杂度 O(n)* @param node*/private void postOrderNR(Node node){Stack<Node> stack = new Stack<>();Stack<Node> out = new Stack<>();stack.push(node);while(!stack.isEmpty()){Node cur = stack.pop();out.push(cur);if(cur.left != null){stack.push(cur.left);}if(cur.right != null){stack.push(cur.right);}}while(!out.isEmpty()){System.out.println(out.pop().e);}}
4.2、广度优先遍历
广度优先遍历:又称为,层序遍历,按照高度顺序一层一层的访问整棵树,高层次的节点将会比低层次的节点先被访问到。这种遍历方式显然是不适合递归求解的。至于为什么,相信经过我们前面对递归的分析,大家已经很清楚了。
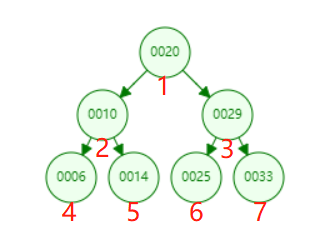
对于层序优先遍历,我们使用队列来实现,利用队列的先进先出(FIFO)的的特性。
/*** 层序优先遍历* 时间复杂度 O(n)*/public void levelOrder(){Queue<Node> queue = new LinkedList<>();queue.add(root);while(!queue.isEmpty()){Node node = queue.remove();System.out.println(node.e);if(node.left != null){queue.add(node.left);}if(node.right != null){queue.add(node.right);}}}
05 二分搜索树存在的问题
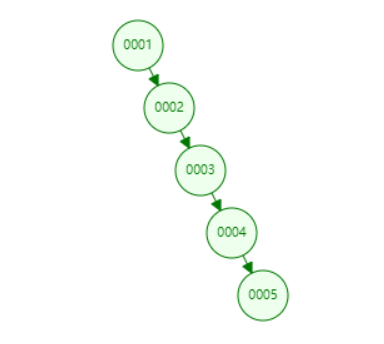
前面我们讲,二分搜索树是一种高效的数据结构,其实这也不是绝对的,在极端情况下,二分搜索树会退化成链表,各种操作的时间复杂度大打折扣。比如我们向我们上面实现的二分搜索树中按顺序添加如下元素[1,2,3,4,5],如下图所示,我们发现我们的二分搜索树其实已经退化成了一个链表。关于这个问题,我们在后面介绍平衡二叉树(AVL)的时候会讨论如何能让二分搜索树保持平衡,并避免这种极端情况的发生。
《祖国》小时候以为你就是远在北京的天安门长大了才发现原来你就在我的心里
参考文献
《玩转数据结构-从入门到进阶-刘宇波》
《数据结构与算法分析-Java语言描述》
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,学习能力的提升上有新的认识,欢迎转发分享给更多人。
欢迎各位读者加入程序员小乐技术群,在公众号后台回复“加群”或者“学习”即可。
猜你还想看
我是程序员,每天5点半下班

关注「程序员小乐」,收看更多精彩内容
嘿,你在看吗?














 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









