









最终得出最代表垃圾邮件的五个词为gun,moral,israel,jew,faith
将上一篇的main函数替换为这个
def main():
trainMatrix, tokenlist, trainCategory = readMatrix('MATRIX.TRAIN')
testMatrix, tokenlist, testCategory = readMatrix('MATRIX.TEST')
state0, state1, proportion_state0, proportion_state1 = nb_train(trainMatrix,tokenlist,trainCategory)
proportion_p1_p0=[]
for i in range(len(state0)):
proportion_p1_p0.append((state0[i]/state1[i]))
largest_five=heapq.nlargest(5, proportion_p1_p0)
location=[]
for i in range(len(largest_five)):
j=proportion_p1_p0.index(largest_five[i])
location.append(j)
print tokenlist[j]
return

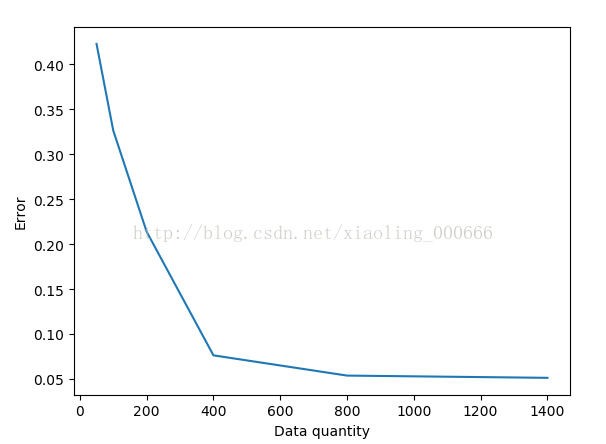
随着数据量的增大,误差不断减小
将上一篇的main函数替换为这个
def main(): trainfile=['MATRIX.TRAIN.50','MATRIX.TRAIN.100','MATRIX.TRAIN.200','MATRIX.TRAIN.400','MATRIX.TRAIN.800','MATRIX.TRAIN.1400'] error= np.zeros(len(trainfile)) x=[50,100,200,400,800,1400] for i in range(len(trainfile)): trainMatrix, tokenlist, trainCategory = readMatrix(trainfile[i]) testMatrix, tokenlist, testCategory = readMatrix('MATRIX.TEST') state0, state1, proportion_state0, proportion_state1 = nb_train(trainMatrix,tokenlist,trainCategory) output = nb_test(testMatrix,state0, state1, proportion_state0, proportion_state1) error[i]=evaluate(output, testCategory) plt.xlabel('Data quantity') plt.ylabel('Error') plt.plot(x,error) plt.show() return
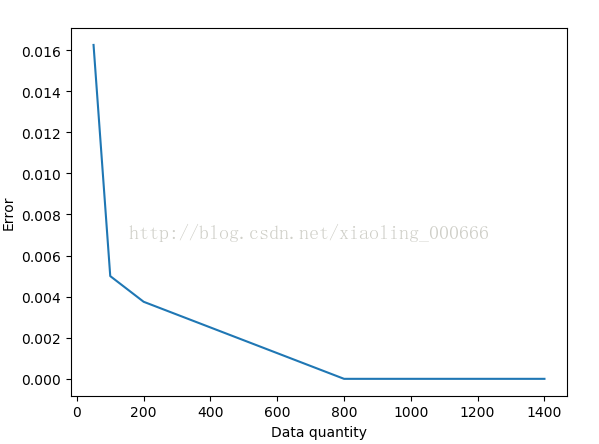
svm的误差更小一些















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









