






 本文介绍了Python可能即将在3.13版本中引入的Copy-and-PatchJIT技术,这是一种无需开发者手动编写汇编代码的JIT编译器,旨在提高代码执行效率。文章详细解释了JIT的概念、工作原理以及与完整JIT的区别,展示了复制加补丁JIT在性能优化上的潜力。
本文介绍了Python可能即将在3.13版本中引入的Copy-and-PatchJIT技术,这是一种无需开发者手动编写汇编代码的JIT编译器,旨在提高代码执行效率。文章详细解释了JIT的概念、工作原理以及与完整JIT的区别,展示了复制加补丁JIT在性能优化上的潜力。

Python 或将迎来新功能 JIT。与完整的 JIT 不同,这里引入的 Copy-and-Patch JIT 技术的优点是开发者无需手写汇编代码就可以生成高效的机器码,同时在运行期产生汇编代码的方式是快速的。。
2023 年 12 月下旬,CPython 核心开发人员 Brandt Bucher 向 Python 3.13 分支提交了一个小小的拉取请求(pull-request),要求添加一个 JIT 编译器。
这一改动一旦被接受,将成为自 Python 3.11 中添加专用自适应解释器以来,CPython 解释器最大的改动之一。
在这篇博文中,我们将了解一下 JIT,它是什么、如何工作以及有哪些好处。

什么是 JIT?
JIT(Just in Time)是一种编译设计,意指在首次运行代码时按需进行编译。这是一个非常广泛的术语,可以有很多含义。我想,从技术上讲,Python 编译器已经是 JIT 了,因为它能将 Python 代码编译成字节码。
当不少开发者提及 JIT 编译器时,他们往往指的是能输出机器代码的编译器。这与 AOT(Ahead of Time)编译器形成鲜明对比,比如 GNU C 编译器、GCC 或 Rust 编译器 rustc,它们只生成一次机器码,并以二进制可执行文件的形式发布。
当你运行 Python 代码时,它首先被编译成字节码。网上有很多关于这个过程的演讲和视频,我不想过多重复,但关于 Python 字节码,有一点很重要:
-
它们对 CPU 没有任何意义,需要一个特殊的字节码解释器循环才能执行
-
它们是高级代码,相当于 1000 条机器指令
-
它们与类型无关
-
它们是跨平台
对于一个非常简单的 Python 函数 f(),它定义了一个变量 a 并赋值 1:
def func():
a = 1
return a
它编译成 5 条字节码指令,运行 dis.dis 即可看到:
>>> import dis
>>> dis.dis(func)
34 0 RESUME 0
35 2 LOAD_CONST 1 (1)
4 STORE_FAST 0 (a)
36 6 LOAD_FAST 0 (a)
8 RETURN_VALUE
如果你想尝试更复杂的反汇编,还有一个交互性更强的反汇编器,名为 dissy。
对于这个函数,Python 3.11 编译成了 LOAD_CONST、STORE_FAST、LOAD_CONST 和 RETURN_VALUE 指令。当函数由用 C 语言编写的大规模循环运行时,这些指令将被解释。
如果要在 Python 中编写一个与 C 语言中的循环相当的 Python 评估循环,它应该是这样的:
import dis
def interpret(func):
stack = []
variables = {}
for instruction in dis.get_instructions(func):
if instruction.opname == "LOAD_CONST":
stack.append(instruction.argval)
elif instruction.opname == "LOAD_FAST":
stack.append(variables[instruction.argval])
elif instruction.opname == "STORE_FAST":
variables[instruction.argval] = stack.pop()
elif instruction.opname == "RETURN_VALUE":
return stack.pop()
def func():
a = 1
return a
如果将我们的测试函数交给这个解释器,它就会执行这些函数并打印结果:
print(interpret(func))
这个带有大量 switch/if-else 语句的循环相当于 CPython 解释器循环的工作方式,尽管是简化版。CPython 由 C 语言编写,并由 C 编译器编译。为了简单起见,我将用 Python 编写这个示例。
对于解释器来说,每次要运行函数 func 时,它都要对每条指令进行循环,并将字节码名称(称为操作码)与每个 if 语句进行比较。这种比较和循环本身都会增加执行的开销。如果运行函数 10,000 次,而字节码从未改变(因为它们是不可变的),那么这种开销就显得多余了。与其每次调用函数时都评估这个循环,不如按顺序生成代码来得更有效率。
这就是 JIT 的作用。JIT 编译器有多种类型。Numba 就是一个 JIT。PyPy 有一个 JIT。Java 有很多 JIT。Pyston 和 Pyjion 就是 JIT。
为 Python 3.13 提议的 JIT 是一个复制加补丁的 JIT。

什么是复制加补丁(copy-and-patch) JIT?
没听说过复制和补丁 JIT?别担心,我和大多数人都没听说过。这个想法在 2021 年才被提出,旨在作为动态语言运行时的快速算法。
我将尝试通过扩展解释器循环并将其重写为 JIT 来解释什么是复制和补丁 JIT。之前,解释器循环做了两件事,首先是解释(查看字节码),然后是执行(运行指令)。我们可以做的是将这些任务分开,让解释器输出指令,而不是执行指令。
复制加补丁 JIT 的想法是,复制每条指令的指令,并为字节码参数(或补丁)填空。下面是一个重写的示例,我保持了非常相似的循环,但每次都附加了一个要执行的 Python 代码字符串:
def copy_and_patch_interpret(func):
code = 'def f():\n'
code += ' stack = []\n'
code += ' variables = {}\n'
for instruction in dis.get_instructions(func):
if instruction.opname == "LOAD_CONST":
code += f' stack.append({instruction.argval})\n'
elif instruction.opname == "LOAD_FAST":
code += f' stack.append(variables["{instruction.argval}"])\n'
elif instruction.opname == "STORE_FAST":
code += f' variables["{instruction.argval}"] = stack.pop()\n'
elif instruction.opname == "RETURN_VALUE":
code += ' return stack.pop()\n'
code += 'f()'
return code
原始函数的结果是:
def f():
stack = []
variables = {}
stack.append(1)
variables["a"] = stack.pop()
stack.append(variables["a"])
return stack.pop()
f()
这一次,代码是连续的,不需要循环执行。我们可以存储生成的字符串,然后运行任意多次:
compiled_function = compile(copy_and_patch_interpret(func), filename="<string>", mode="exec")
print(exec(compiled_function))
print(exec(compiled_function))
print(exec(compiled_function))
这样做有什么意义?结果代码做了同样的事情,但运行速度应该更快。我将两种实现方法进行了比较,结果是复制加补丁方法运行得更快(不过请记住,与 C 语言相比,Python 的循环速度非常慢)。

为什么要使用复制加补丁 JIT?
与“完整”的 JIT 编译器相比,这种为每个字节码编写指令并修补值的技术有好有坏。完整的 JIT 编译器通常会将 LOAD_FAST 这样的高级字节码编译成 IL(中间语言)中的低级指令。由于每种 CPU 架构都有不同的指令和功能,要编写一个能将高级代码直接转换为机器代码的编译器,并支持 32 位和 64 位 CPU,以及苹果的 ARM 架构和所有其他类型的 ARM,是一件非常复杂的事情。
相反,大多数 JIT 首先编译的是 IL,即类似于通用机器码的指令集。这些指令包括“PUSH 一个 64 位整数”、“POP 一个 64 位浮点数”、“MULTIPLY 堆栈中的值”等。然后,JIT 可以在运行时将 IL 编译成机器码,方法是发出特定于 CPU 的指令并将其存储在内存中,以便以后执行(类似于我们在示例中的方法)。
一旦有了 IL,就可以对代码进行各种有趣的优化,如常量传播和循环提升。你可以在 Pyjion 的实时编译器 UI 中看到一个例子。
“完整”JIT 的最大缺点是,一次编译成 IL 后,再编译成机器代码的过程非常缓慢。不仅速度慢,而且占用大量内存。为了说明这一点,最近的一项有关“Python 与 JIT 编译器的相遇”的研究提供了数据:一个简单的实现和一个比较评估中的数据显示,基于 Java 的 Python JIT(如 GraalPy 和 Jython)比普通的 CPython 启动时间长 100 倍,编译时需要消耗额外的 Gigabyte 内存。目前已经有针对 Python 的完整 JIT 实现。
之所以选择“复制加补丁”,是因为字节码到机器码的编译是以一组“模板”的形式完成的,然后在运行时将这些模板拼接在一起,并用正确的值进行修补。这意味着普通 Python 用户不会在 Python 运行时中运行这种复杂的 JIT 编译器架构。Python 编写自己的 IL 和 JIT 也是不合理的,因为像 LLVM 和 ryuJIT 这样的现成编译器已经很多了。但完整的 JIT 需要将这些工具与 Python 捆绑在一起,并增加所有开销。复制和补丁 JIT 只需要在编译 CPython 源代码的机器上安装 LLVM JIT 工具,对大多数人来说,这意味着为 python.org 编译和打包 CPython 的 CI 机器。

那么这个 JIT 是如何工作的呢?
Python 的复制加补丁编译器是通过在 Python 3.13 的 API 中扩展一些新的(老实说并不广为人知的)API 来工作的。这些变化使得 CPython 在运行时可以发现可插拔的优化器,并控制代码的执行方式。这个新的 JIT 是这个新架构的可选优化器。我认为,一旦主要错误被解决,它将成为未来版本的默认优化器。
当你从源代码编译 CPython 时,可以在 configure 脚本中提供一个–enable-experimental-jit 标志。这将为 Python 字节码生成机器码模板。首先复制每个字节码的 C 代码,例如最简单的 LOAD_CONST:
frame->instr_ptr = next_instr;
next_instr += 1;
INSTRUCTION_STATS(LOAD_CONST); // Not used unless compiled with instrumentation
PyObject *value;
value = GETITEM(FRAME_CO_CONSTS, oparg);
Py_INCREF(value);
stack_pointer[0] = value;
stack_pointer += 1;
DISPATCH();
这种字节码的指令首先由 C 编译器编译成一个小的共享库,然后存储为机器码。由于有些变量(如 oparg)通常在运行时确定,因此 C 代码在编译时会将这些参数留为 0。就 LOAD_CONST 而言,有 2 个孔需要填入,即 oparg 和下一条指令:
static const Hole _LOAD_CONST_code_holes[3] = {
{0xd, HoleKind_X86_64_RELOC_UNSIGNED, HoleValue_OPARG, NULL, 0x0},
{0x46, HoleKind_X86_64_RELOC_UNSIGNED, HoleValue_CONTINUE, NULL, 0x0},
};
然后,所有机器码都会以字节序列的形式保存在 jit_stencil.h 文件中,该文件会在新的编译阶段自动生成。反汇编代码以注释的形式保存在每个字节码模板的上方,其中 JIT_OPARG 和 JIT_CONTINUE 是需要填补的漏洞:
0000000000000000 <__JIT_ENTRY>:
pushq %rbp
movq %rsp, %rbp
movq (%rdi), %rax
movq 0x28(%rax), %rax
movabsq $0x0, %rcx
000000000000000d: X86_64_RELOC_UNSIGNED __JIT_OPARG
movzwl %cx, %ecx
movq 0x28(%rax,%rcx,8), %rax
movl 0xc(%rax), %ecx
incl %ecx
je 0x3d <__JIT_ENTRY+0x3d>
movq %gs:0x0, %r8
cmpq (%rax), %r8
jne 0x37 <__JIT_ENTRY+0x37>
movl %ecx, 0xc(%rax)
jmp 0x3d <__JIT_ENTRY+0x3d>
lock
addq $0x4, 0x10(%rax)
movq %rax, (%rsi)
addq $0x8, %rsi
movabsq $0x0, %rax
0000000000000046: X86_64_RELOC_UNSIGNED __JIT_CONTINUE
popq %rbp
jmpq *%rax
新的 JIT 编译器启动后,会将每个字节码的机器码指令复制到一个序列中,并将每个模板的值替换为代码对象中该字节码的参数。生成的机器码存储在内存中,然后每次运行 Python 函数时,都会直接执行该机器码。
如果你编译我的分支并在测试脚本上试用,然后将其交给 Ada Pro 或 Hopper 等反汇编器,就能看到 JIT 化的代码。目前,只有在函数包含 JUMP_BACKWARD 操作码(用于 while 语句)时才会使用 JIT,但将来会有所改变。

速度更快了吗?
最初的基准测试显示性能提高了 2-9%。你可能会对这个数字感到失望,尤其是这篇博文一直在讨论汇编和机器代码,没有什么比它们更快了吧?
那么,请记住 CPython 已经是用 C 编写的,并且已经被 C 编译器编译成了机器代码。在大多数情况下,JIT 执行的机器码指令与之前几乎相同。
不过,可以把 JIT 看作是一系列更大规模优化的基石。没有它,所有优化都不可能实现。要让这种变化在开源项目中得到接受、理解和维护,必须从简单开始。

未来是光明的,未来是 JIT 编译的
现有的解释器是提前编译的,这带来的挑战是进行认真优化的机会较少。Python 3.11 的自适应解释器是朝着正确方向迈出的一步,但要使 Python 在性能上实现质的飞跃,还需要更进一步。
我认为,虽然 JIT 的第一个版本不会严重影响任何基准测试(目前还不会),但它为一些巨大的优化打开了大门,而不仅仅是那些有利于标准基准测试套件中玩具基准测试程序的优化。
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
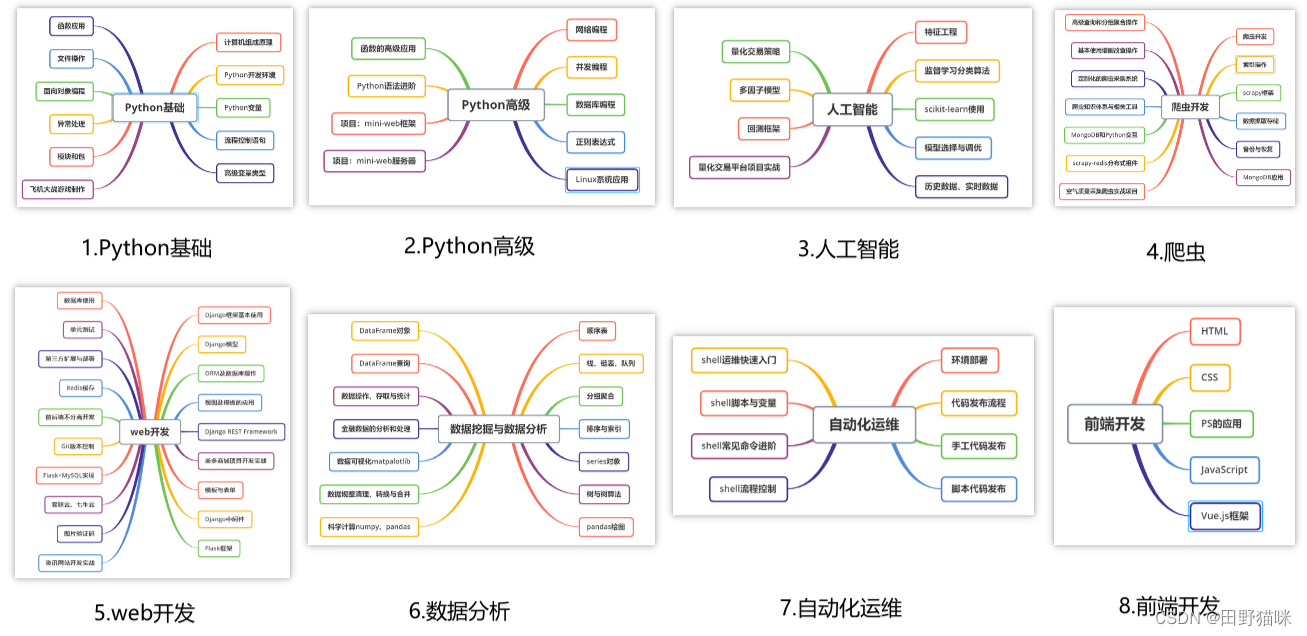
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
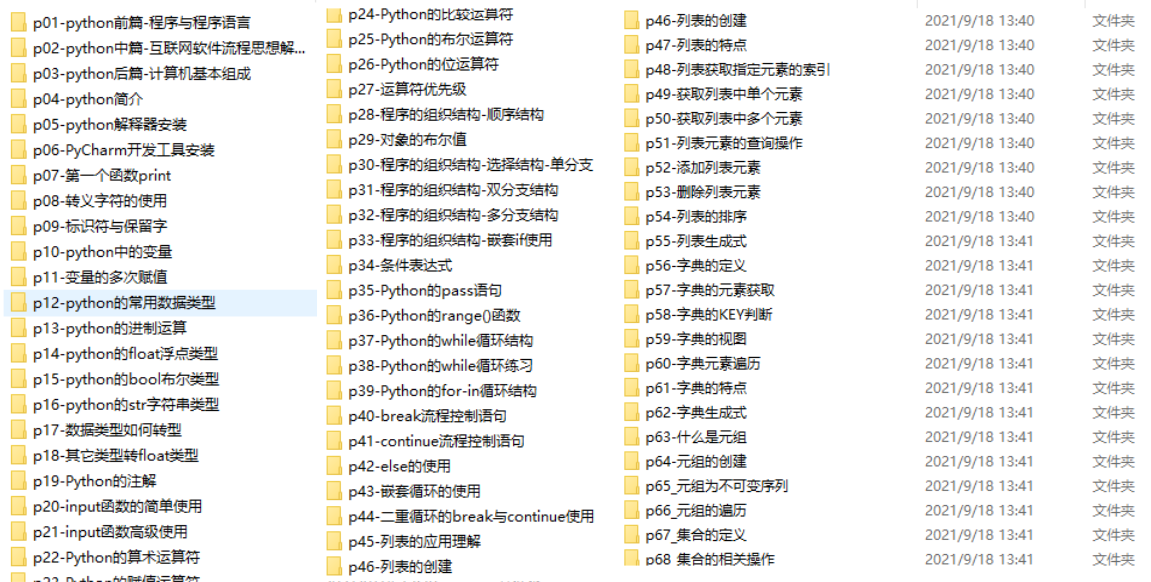
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









