







文章目录
Java基础
try finally return执行顺序
https://juejin.cn/post/7081317835930075173
两个对象的 hashCode()相同,则 equals()是否也一定为 true
两个对象equals相等,则它们的hashcode必须相等,反之则不一定。
两个对象==相等,则其hashcode一定相等,反之不一定成立。
重写一个对象的hashcode
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && i == person.i && j == person.j && Objects.equals(name, person.name) && Objects.equals(p_Field, person.p_Field) && Objects.equals(sex, person.sex);
}
@Override
public int hashCode() {
return Objects.hash(age, name, i, j, p_Field, sex);
}
// Object的equals判断
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
// Object的hash判断
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
// Arrays的hashcode,注意31和result的作用和写法
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
final关键字
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改,引用类型不能指向其他值。
继承与多态
父类
package javabasic.exceptionTest.inherit;
public class Person {
public int age;
public String name;
// 静态变量
public static String staticField = "父类--静态变量";
protected int i = 1;
protected int j = 8;
// 变量
public String p_Field = "父类--变量";
// 静态初始化块
static {
System.out.println(staticField);
System.out.println("父类--静态初始化块");
}
// 初始化块
{
System.out.println(p_Field);
System.out.println("父类--初始化块");
}
public Person(){
System.out.println("父类");
// 子类继承了用子类的方法
say();
System.out.println("父类--构造器");
System.out.println("i=" + i + ", j=" + j);
j = 9;
}
protected void say(){
System.out.println("有人说话。");
}
private String sex;
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
子类
package javabasic.exceptionTest.inherit;
public class SubClass extends Person{
public String school;
public SubClass(){
System.out.println("子类");
}
// 静态变量
// public static String staticField = "子类--静态变量";
// 变量
public String s_Field = "子类--变量";
// 静态初始化块
static {
System.out.println(staticField);
System.out.println("子类--静态初始化块");
}
// 初始化块
{
System.out.println(s_Field);
System.out.println("子类--初始化块");
}
public SubClass(String name, int age){
this.name = name;
this.age = age;
System.out.println("子类--构造器");
System.out.println("i=" + i + ",j=" + j);
}
protected void say(){
System.out.println("子类"+name+age);
}
public void subSelf(){
System.out.println("子类"+"subSelf");
}
}
package javabasic.exceptionTest.inherit;
public class MainTest {
public static void main(String[] args) {
Person person = new SubClass("xiaoma", 10);
person.setSex("girl");
System.out.println(person.getSex());
System.out.println(SubClass.staticField);
// 多态
person.say();
}
}
父类--静态变量
父类--静态初始化块
父类--静态变量
子类--静态初始化块
父类--变量
父类--初始化块
父类
学生null0
父类--构造器
i=1, j=8
子类--变量
子类--初始化块
子类--构造器
i=1,j=9
girl
父类--静态变量
学生xiaoma10
总结:

- 子类方法与父类同名,切参数一致,则修饰符范围要大于等于父类。
- 静态变量也可以继承,如果子类定义了相同的静态变量,则会覆盖。
- 子类和父类,继承时可以理解为父类的类空间在子类中,使用子类内容时,先在子类中寻找,找不到去父类空间寻找。
自动装箱和拆箱
1 package cn.zpoor.test;
2 /**
4 * 自动装箱拆箱*/
5 public class Main {
6 public static void main(String[] args) {
7 Integer i = 10;
8 int n = i;
9 }
10 }

不要慌,冷静分析:在装箱的时候自动调用的是Integer的valueOf()方法,拆箱的时候是自动调用Integer的intValue()方法。
装箱过程是通过调用包装器的valueOf方法实现,拆箱过程是通过调用包装器的xxxValue方法实现的(xxx代表基本数据类型)。
package javabasic.exceptionTest.chaixiangzhuangxiang;
import threadtest.DoubleCheckLock;
public class Test {
public static void main(String[] args) {
// 自动装箱
Integer i = 10;
// 自动拆箱
int n = i;
Integer j = Integer.valueOf(20);
Long k = Long.valueOf(10);
Double d = Double.valueOf(2.74);
Character c = Character.valueOf('d');
// 高类型向低类型转换。
short a =10;
n = a;
Short st = Short.valueOf(a);
}
}
//Integer,范围-128~127.
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
//Long,范围-128~127.
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
//Float, 每次都新生成个对象。
public static Float valueOf(float f) {
return new Float(f);
}
// Double,每次都新生成个对象。
public static Double valueOf(double d) {
return new Double(d);
}
// Character, 范围0~127.
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
Byte, 范围-128~127.
public static Byte valueOf(byte b) {
final int offset = 128;
return ByteCache.cache[(int)b + offset];
}
Short, 范围-128~127.
public static Short valueOf(short s) {
final int offset = 128;
int sAsInt = s;
if (sAsInt >= -128 && sAsInt <= 127) { // must cache
return ShortCache.cache[sAsInt + offset];
}
return new Short(s);
}
Boolean, 默认就两个类型。
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
注意:
- java 字面量默认为int和double类型
- byte、char、short三种类型参与运算时,先一律转换成int类型再进行运算。示例如下:
byte b = 97;
int num = b + b; //num的值为194
- 注意float运算不会默认转成double。
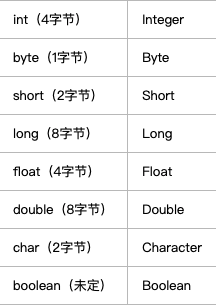
- 低类型金可向高类型转换,高类型不能向低类型转换,(byte, short, char)–>int–>long–>float–>double, char不与byte和short进行转换。虽然float是4字节,但是由于是浮点数,存储方式与整形存储方式不一样,float类型的范围是:一3.403E383.403E38。而long类型的范围是:-2^63263-1(大概是9*1018), float存储数值范围要大于long类型。所以long可以向float进行转换。
集合遍历过程中删除
remove操作 int 时,为操作索引, remove操作Object对象时,移除的是对象。
当集合遍历时,如果使用迭代器的方式遍历,但是不使用迭代器的改变元素数量(remove)或者add . 此时遍历就会报错。
报错原因 :
- 初始化遍历器时,会有 int expectedModCount = modCount;
- 遍历器遍历时,会判断
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
- 集合添加修改元素时,会修改expectedModCount的值。
package study.collectiontest;
import com.google.common.collect.Lists;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class ListTEst {
public static void main(String[] args) {
for(int i=0 ;i<10000;i++){
testRemoveIII();
}
}
public static void testRemove(){
ArrayList<Integer> integers = Lists.newArrayList(1, 2, 3, 4);
System.out.println(integers);
integers.remove(new Integer(1));
//1是索引 ,object是对象
integers.remove(1);
System.out.println(integers);
}
// 会报错
public static void testRemoveII(){
List<String> stringList = Lists.newArrayList("m", "g", "h");
for (String s : stringList) {
if (Arrays.asList("m", "h").contains(s)) {
stringList.remove(s);
}
}
}
// 不会报错
public static void testRemoveIII(){
List<Integer> integers = new ArrayList<>(5);
integers.add(1);
integers.add(2);
integers.add(2);
integers.add(4);
integers.add(5);
for (int i = 0; i < integers.size(); i++) {
if (integers.get(i)%2==0){
integers.remove(i);
}
}
System.out.println(integers);
}
// 会报错,索引错误
public void testRemoveIIII(){
List<String> strings = new ArrayList<>();
strings.add("a");
strings.add("b");
strings.add("c");
strings.add("d");
int size = strings.size();
for (int i = 0; i < size; i++) {
strings.remove(i);
}
}
// 会报错,CurrentModifyTion
public void testRemoveIIIII(){
List<String> strings = new ArrayList<>();
strings.add("a");
strings.add("b");
strings.add("c");
strings.add("d");
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String next = iterator.next();
strings.remove(next);
}
System.out.println(strings);
}
//正确做法
public void testRemoveIIIIII(){
List<String> strings = new ArrayList<>();
strings.add("a");
strings.add("b");
strings.add("c");
strings.add("d");
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String next = iterator.next();
iterator.remove();
}
System.out.println(strings);
}
}
ConcurrentHashMap
- jdk1.7采用的是segment方法,初始化容量为16,每次插入entry时,需要先hash定位segment,在segment的table里定位索引,在插入数据,加锁力度是segment。
- jdk1.8采用node+cas+synchronized方法,实现并发线程安全,
4.如果没有hash冲突,直接通过CAS将数据放置到tab中,如果发生冲突了,则通过synchronized对node上锁,哈希冲突超过8个节点就生成红黑树结构。
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
5.get时,没有使用synchronized,也没有使用cas,因为get时,Node节点结构。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
其中Node的数据结构为这样,其中hash和key是不变的,val,和next都用了violate关键字修饰,保证了可见性,当有修改时,get也能够查找到。

ConcurrentModificationException
举例:
https://blog.csdn.net/zymx14/article/details/78394464?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
其中:
集合类的内部的迭代器使用时,如果集合修改元素会抛出异常,在迭代器初始化时,固定修改值,next会进行比较,如果失败,就会抛出异常。
ConcurrentHashmap是弱一致性的?
针对get,clear, 遍历, 整体理解,因为这三种操作无锁,所以多线程是,元素put时,最终得到的结果可能会发生不一致。所以导致弱一致。
如果加锁,控制集合访问,因为只有一个线程能访问集合,一个线程得到的结果固定(加锁顺序固定)。
理解: 如果两个线程,同时执行get,clear,遍历操作, 另一个线程put,remove时,两个线程得到的结果可能是不一样的。
CopyOnWriteArrayList:
CopyOnWrite 容器即写时复制的容器,也就是当我们往一个容器添加元 素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个 新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指 向新的容器(改变引用的指向)。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写在不同的容器上进行, 注意,写的时候需要加锁。
初始化时,getArray()返回的是一个元素为0的空数组,每次都会add都会生成新的数组。
添加
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
读不加锁,读写分离
public E get(int index) {
return get(getArray(), index);
}
ArrayList、LinkedList、 Vector
- 其中ArrayList是基于数组。
- LinkedList是基于双向链表
- Vector线程安全
HashMap、LinkedHashMap、TreeMap
HashMap
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap不安全的原因:put 操作时如果key值不相等。但是hashcode值相等,同时放入一个table[index]中时会发生消息丢失,会发生消息丢失。
jdk1.7和jdk1.8
jdk1.7
采用头插法,
hash运算方式为4次位运算,5次异或。
hash冲突采用拉链法解决。
先扩容,再将数据放入到hash表中。
两个线程一起扩容时,可能会发生死循环。
jdk1.8
采用尾插法
hash运算方式为1次位运算,一次异或。
hash冲突采用红黑树解决
是想将数据放入hash表中,在进行扩容。
LinkedHashMap
1,底层采用双向链表加hash表的形式存储数据。















 4113
4113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









