







这里紧接着上一节的内容讲:
上一节在这里:http://blog.csdn.net/xiaomai_sysu/article/details/49372711
上次我们定义了item.py\pipelines.py\settings.py,了解了布隆过滤。今天我们定义重头戏:定义蜘蛛
我们首先在脑海里回想一下我们的目标:
抓取所有的《中山大学吧》帖子标题+内容
我们先来到百度贴吧的中山大学主页。
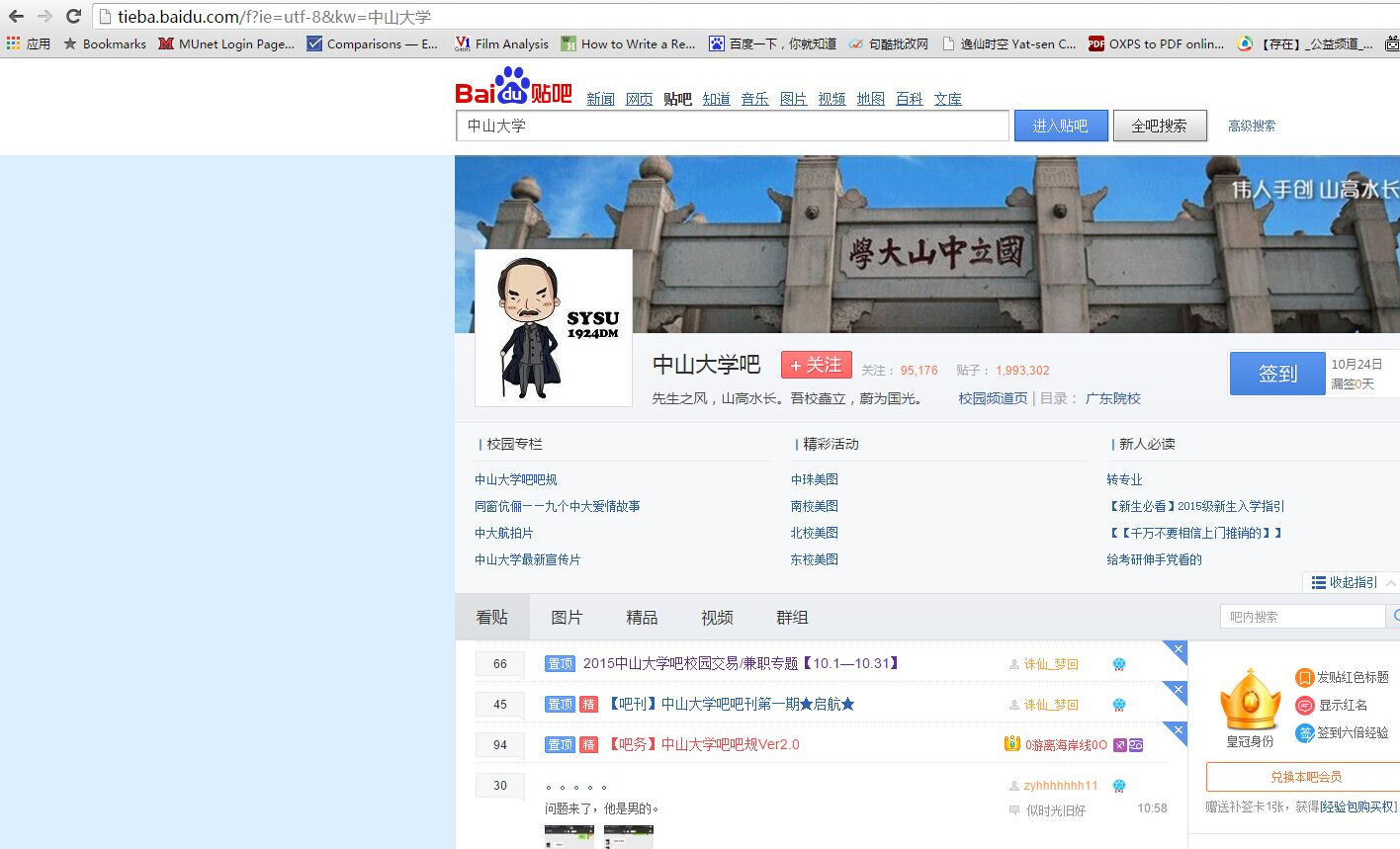
我们看到,主页的URL是:
http://tieba.baidu.com/f?ie=utf-8&kw=%E4%B8%AD%E5%B1%B1%E5%A4%A7%E5%AD%A6&pn=1
这个怎么解析呢?首先,ie=utf-8是解码格式,kw=%E4%B8%AD%E5%B1%B1%E5%A4%A7%E5%AD%A6是“中山大学”编码后的字符串
pn=1是指当前的主页(mainpage)从第几个帖子开始显示,经过实验,pn可以等于任何一个正整数,也就是说当pn=25 主页就从第25个帖子开始显示,pn=44就从第44个帖子开始显示。
好。我们先想一下我们的结构:
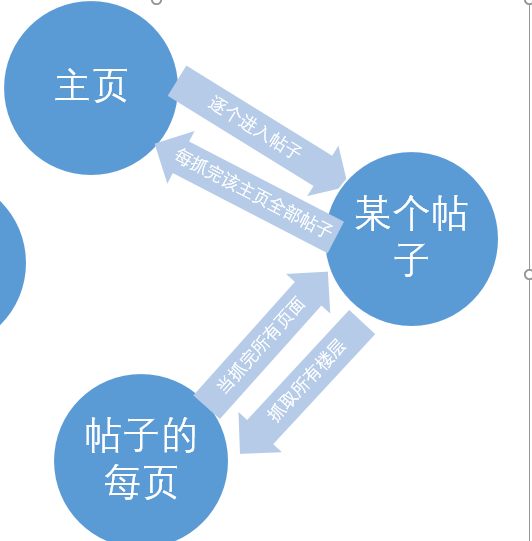
【注意】所有的url都要先放入布隆过滤器,如果重复就不再抓取!
OK,我们想好了结构,就用chrome先来看主页的源代码,找找如何执行:主页==》某个帖子。
我们搜索帖名:
然后看到

我们分析,发现这是一个class="j_th_tit "
的标签a,其包含的@href性质,就是我们要抓的网页。
所以用XPath表示是:
sel.xpath('//a[@class="j_th_tit "]/@href').extract()由于这里抓到的只是tieba.baidu.com/后面的一部分,所以要加回前面的域名。
sel=Selector(response)
sites=sel.xpath('//a[@class="j_th_tit "]/@href').extract()
for site in sites:
urls = "http://tieba.baidu.com"+site现在我们进入了帖子!
问题在于:如何抓帖子的content ? 这个我们来看看具体帖子的源代码!

大家看到,黑色的是楼主发的文字。
红色的是独一无二的标签,匹配的是整个页面所有人发的内容。
我们只要其中“黑色的文本文字”,于是我们就这样抓取吧!
contentList=site.xpath('//div[@class="d_post_content j_d_post_content "]/text()').extract()
然后对于每个内容,我们输出到item里:
for floor in contentList:
utfcontent=floor.encode('utf-8')
item["content"] += utfcontent
item["content"] += "\n"
好了。然后我们想想,如果一个帖子有很多页,怎么抓每一页的东西呢?
光是想想不出来的,我们来看看具体的帖子:
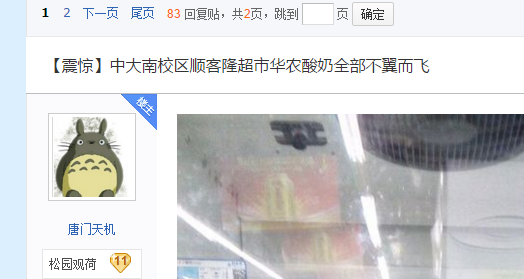
有办法了,我们就利用这个”下一页“按钮去抓下一页!
截取的源代码:

我们可以看到,网址是a标签的href属性,而这个属性的父标签是<li>,标签性质class里含有pager关键字。
经过多个页面的观察发现,pager这个标签可以是_theme_4也可能是_theme_5 之类,不确定,所以我们用contains进行模糊匹配
urlList=site.xpath('//li[contains(@class,"l_pager")]/a/@href').extract()我们之前说过,要用bloom fliter查重!所以我们这样处理:
for t in urlList:
if (self.bf.is_element_exist("http://tieba.baidu.com"+t)==False): #判断是否已经保存过?
yield Request("http://tieba.baidu.com"+t,callback=self.parse_inPage)
else:
continue第三个问题:如何获取标题?
我们说过,文档名就是贴子标题,这个要如何获取呢?
老办法了,抓源代码,看标签,用Xpath:

我们这里用
titleList=site.xpath('//h3[contains(@class,"core_title_txt")]/@title').extract()然后对于每个title,存到item里
for t in titleList:
title=t.encode('utf-8')
item["title"] += title
yield item 太容易了!
最后一个问题:如何更新主页?
为什么要更新主页呢?我们知道,一个主页如果pn=0不更新的话,最多也就抓50个帖子
我可是要把百度贴吧爬下来的男人!怎么能容忍这个缺陷呢!
于是,我们做个计数器:每进去10次帖子,就把主页更新一遍。为了方便呢,我们把mainpage作为类的成员,计数器也做成类的成员。
然后我们只要,每次self.count%10==0,我们就把mainpage更新,pn=str(self.count)。
实现如下:
self.count+=1
if self.count%10==0:
self.mainpage="http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%B1%B1%E5%A4%A7%E5%AD%A6&ie=utf-8&pn="+str(self.count)
yield Request(self.mainpage,callback=self.parse_mainPage)大功告成!
到了这一步,我们基本把蜘蛛文件的大部分搞定了,只需要回到pipelines看看之前没有认真完成的管道:
我们知道,我们在这个文件里做的,content和title定义成是utf-8编码的字符串,所以我们要做的
1.解码
2.write
很简单了是不是!
NO!
注意!!!! 每个帖子从第二页开始,标题格式都是这样的“回复:XXXXX”
如果简单地这样保存会使你的每个帖子有两个文件,文件名分别是【 帖名.txt】、【回复:帖名.txt】
我可是要把百度贴吧爬下来的男人!怎么能容忍这个缺陷呢!
好,我们要怎么做?
我们让key=”回复:”
我们用str的rfind(key)函数,返回字符串匹配key的最后一个下标,然后用split(key),取出第二部分,就大功告成了!代码如下
pipelines.py:
class SysuPipeline(object):
def __init(self):
pass
def process_item(self, item, spider):
key='回复:'
index=item["title"].rfind(key) #rfind() return the last index!
if(index==-1): #not found!
title=item["title"].decode('utf-8') #item['title'] has been encoded to utf8
else:
t=item["title"].split(key)[1]
title=t.decode('utf-8')
path='D:\\guagua\\SYSU\\DATA\\'+ title +'.txt'
output = open(path,'a')
output.write(item["content"])
output.close()
return item我们蜘蛛要设置两个解析函数:一个parse_mainPage负责处理主页,一个parse_inPage负责处理帖子。
parse_mainPage的作用:取出帖子的地址!
parse_inPage的作用:抓取title\content,然后抓取下一页,直到抓完。
蜘蛛完善好,把上面说到的几个Xpath放进去
对了,别忘了把bloom fliter.py保存到本地,【PART1】有源代码
最后贴上蜘蛛代码:
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from SYSU.items import SysuItem
from SYSU.bloomfliter import BloomFilter
class SYSUSpider(Spider):
name = 'SYSUSpider'
allowed_domains=["tieba.baidu.com"]
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
self.bf=BloomFilter(0.0001,100000)
self.mainpage="http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%B1%B1%E5%A4%A7%E5%AD%A6&ie=utf-8"
self.count=0
def start_requests(self):
yield Request(self.mainpage,callback=self.parse_mainPage)
def parse_inPage(self,response):
sel=Selector(response)
site=sel
url=''
item=SysuItem()
item["title"]=''
item["content"]=''
c=site.xpath('//link[@rel="canonical"]/@href').extract()
currentUrl=c[0]
self.bf.insert_element(currentUrl)
contentList=site.xpath('//div[@class="d_post_content j_d_post_content "]/text()').extract()
for floor in contentList:
utfcontent=floor.encode('utf-8')
item["content"] += utfcontent
item["content"] += "\n"
titleList=site.xpath('//h3[contains(@class,"core_title_txt")]/@title').extract()
for t in titleList:
title=t.encode('utf-8')
item["title"] += title
yield item
urlList=site.xpath('//li[contains(@class,"l_pager")]/a/@href').extract()
for t in urlList:
if (self.bf.is_element_exist("http://tieba.baidu.com"+t)==False): # reduce a /
yield Request("http://tieba.baidu.com"+t,callback=self.parse_inPage)
else:
continue
self.count+=1
if self.count%10==0:
self.mainpage="http://tieba.baidu.com/f?kw=%E4%B8%AD%E5%B1%B1%E5%A4%A7%E5%AD%A6&ie=utf-8&pn="+str(self.count)
yield Request(self.mainpage,callback=self.parse_mainPage)
def parse_mainPage(self,response):
sel=Selector(response)
sites=sel.xpath('//a[@class="j_th_tit "]/@href').extract()
for site in sites:
urls = "http://tieba.baidu.com"+site
if(self.bf.is_element_exist(urls)==False):
yield Request(urls,callback=self.parse_inPage)
else:
continue
# cmd: guagua\SYSU>scrapy crawl SYSUSpider
然后呢?
然后我们就等!
由于网速有限,我们几乎不可能高效率地爬下整个百度贴吧,只能爬某一两个吧。
有人会问了,露珠我是新手,感觉我很难一次写出这么长的代码啊
晕,我也是新手,所以我的建议如下:
一步步完成程序、由低到高实现功能!
什么意思?
本例:我是这样做的:
步骤一:把http://tieba.baidu.com/p/4117846868 这样的页面,单页面的内容爬下来
步骤二:升级代码,使得代码能自动把上述url的第二页、第三页…都抓下来
步骤三:升级item.py,标题过滤“回复:”关键字。
步骤四:升级代码,加入bloom fliter.py
步骤五:升级代码,使得“访问主页”变成第一步,改用start_request()
步骤六:升级代码,加入parse_inPage和parse_mainpage,加入计数器用于更新主页
建议!
一步一步学习,遇到不懂就百度
基本了解就开始实践,不要永远卡在理论阶段!
本程序可提升部分:
1. 多线程执行任务
2. 分布式抓取
3. 优化文本布局(这个最简单hhhh)
以后有提升会更新的,现在我要试着去爬你懂磁力链接了hhhhhhhh
(误 新世界的大门
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









