







某某孙逸仙魔法大学计科的python新手撰写,最近被前女友劈腿,我心里几乎是崩溃的,于是找了点时间做了做这个知乎的项目,写一些东西作为笔记。
表示楼主在网上看到这个:
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的独家报告
http://it.taocms.org/07/8326.htm
想着自己也完全有能力做一些类似的project,于是楼楼拿出自己封存半年的知乎帐号开始了爬虫之旅。
作者是一只纯新手,文中错误之处希望不吝指点。本文仅用于学习讨论,不可用于其他非法用途。
(在楼主爬知乎的那几天里,我的帐号被封了三个,然后验证码被知乎官方换了一次,变得更难识别,不知道是不是偶然)

由于lxml.etree常常崩溃的问题纠缠了两天没能解决,所以样本量很有限,只有不到十万个
好,先上我自己数据库里收集到的数据:
(mysql数据库下载留在下次更新咯)
学校分布:
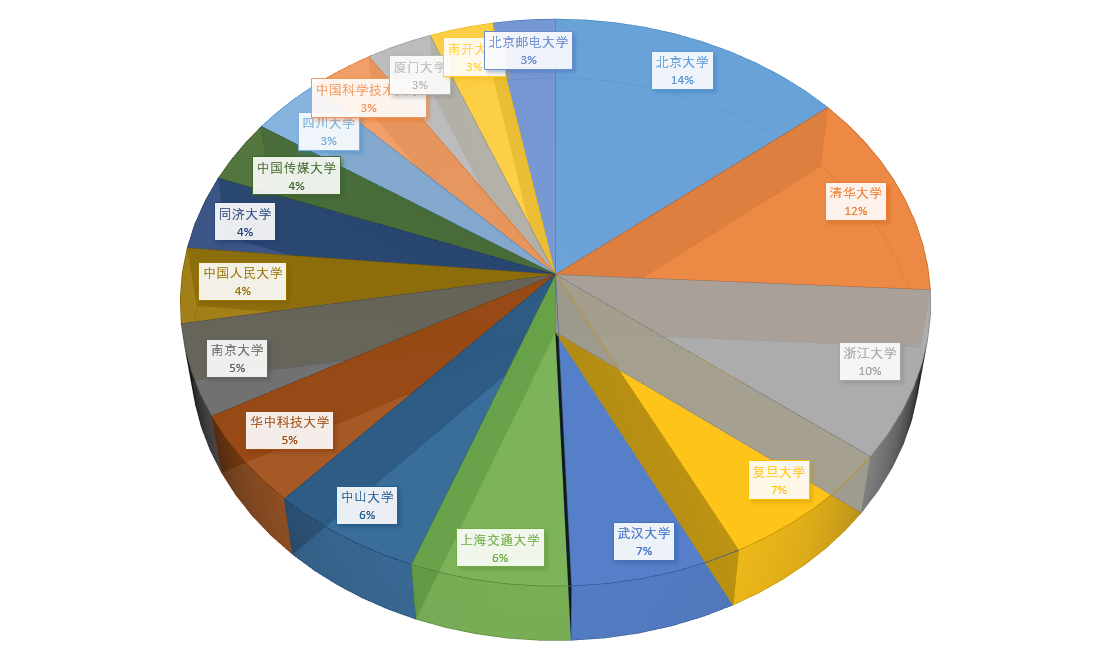
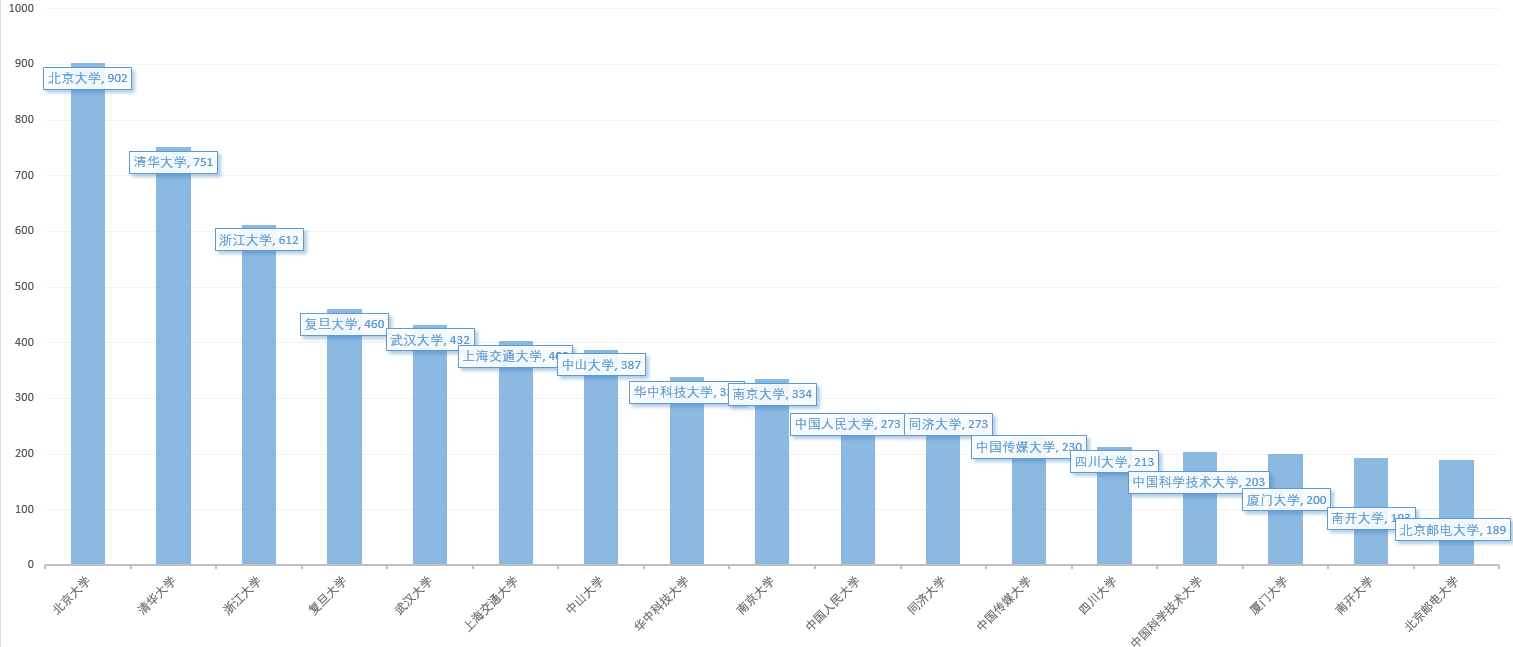
学校具体数量:
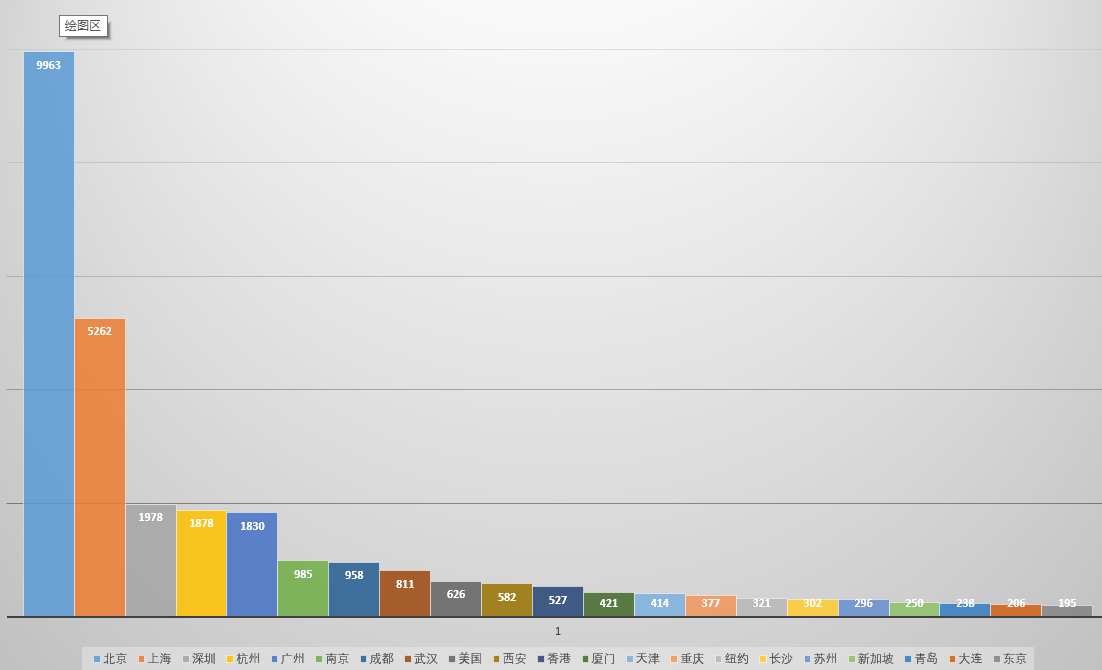
空间分布和具体数量:
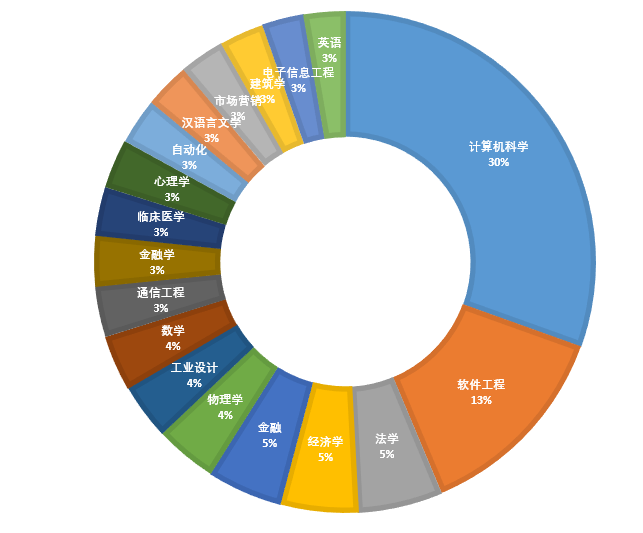
专业分布:
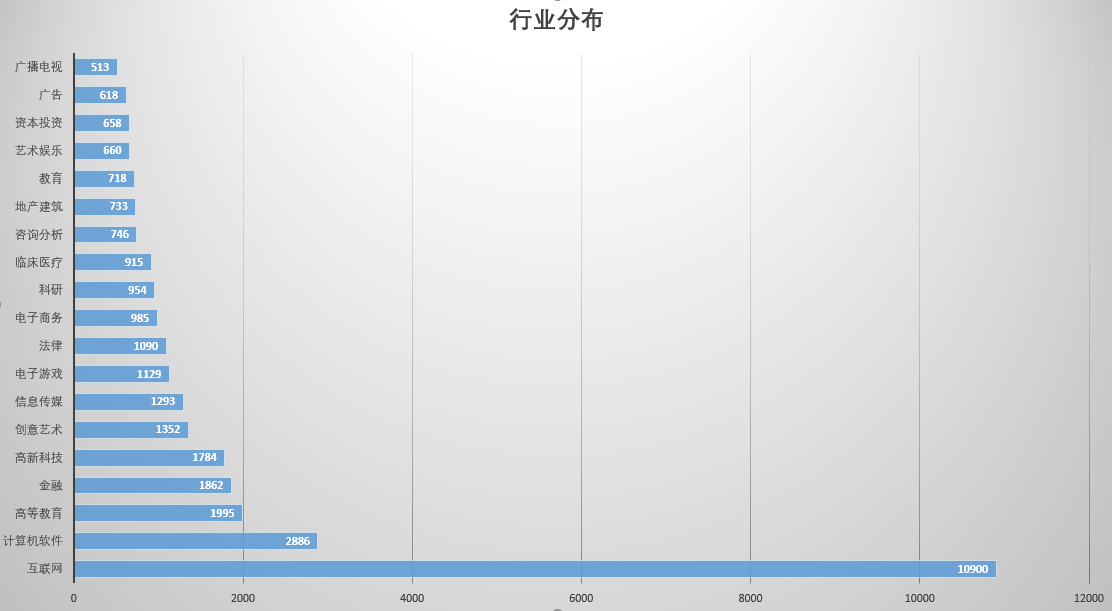
行业分布:
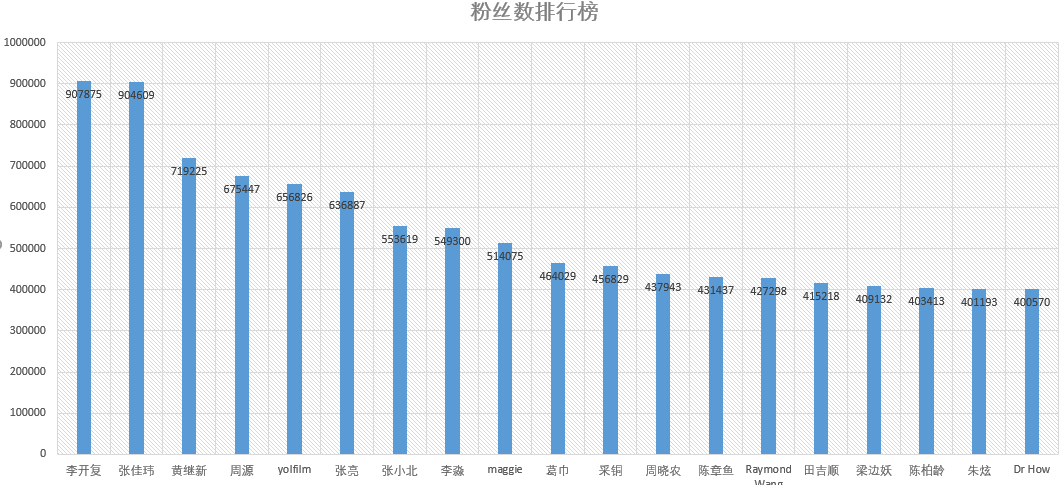
粉丝数排行:
值得统计的还很多,就不在此一一列举~
还可以去抓文章,看看文章里出现的关键字积极与消极比哪个更多之类~
是不是很有趣呢?
我是如何做的呢?
小麦给你一一解释啦!
正文开始
实验目的:
抓取知乎用户,并保存在数据库中进行进一步分析
实验平台
python 2.7
mysql 5.7
MS Excel
iep
库
requests(楼楼用scrapy模拟登陆遇到麻烦,所以改用requests来做)
lxml
PIL
MySQLdb
re
Multiprocessing
自定义bloomfliter
做前思考:
1.确定搜索方式
我们怎么把用户爬下来呢?
其实很简单,我们选择从一个用户出发,抓取他的所有关注者(followee),然后再从关注者的第一个出发,抓取他的所有关注者…也就是常说的广度优先(BFS)算法。我们之所以选择关注者(followee)而不是粉丝(follower),是因为被关注的用户,往往活跃度和可信度远远高于那些关注度很低的用户
这里我们采用广度优先(BFS)算法,实现起来非常简单,一句话概括:
有一个网站列表,把这个网站列表的第一个访问一次,然后抓取到里面的网页,全部push到队尾,然后把这个网页pop掉。然后再访问POP后列表的的第一个,再抓,再PUSH到队尾,再POP….以此类推。
2.过滤重复用户
由于人际关系是一个有回路的图,很容易出现“回路”导致重复抓取,所以重要的一点在于排除重复。
这里依然用牺牲极少的bloomfliter做,见我的上一篇博文有介绍:[[PYTHON]-用Scrapy爬虫遍历百度贴吧,本地保存文字版【PART 1】]
(http://blog.csdn.net/xiaomai_sysu/article/details/49372711%20%5BPYTHON%5D-%E7%94%A8Scrapy%E7%88%AC%E8%99%AB%E9%81%8D%E5%8E%86%E7%99%BE%E5%BA%A6%E8%B4%B4%E5%90%A7%EF%BC%8C%E6%9C%AC%E5%9C%B0%E4%BF%9D%E5%AD%98%E6%96%87%E5%AD%97%E7%89%88%E3%80%90PART%201%E3%80%91)
【布隆过滤】
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。如果检测结果为是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。因此Bloom filter具有100%的召回率。这样每个检测请求返回有“在集合内(可能错误)”和“不在集合内(绝对不在集合内)”两种情况,可见 Bloom filter 是牺牲了正确率和时间以节省空间。
一言概之,其本质就是利用散列函数,避免重复访问。巨大优势:快速,缺点:散列碰撞
我们用到的代码,依然是上面链接里的bloomfliter.py,直接引用就好。(python轮子真好用)
3.模拟登陆(难点)
知乎对未登录用户的显示内容和对已登录用户的显示内容有很大差别,所以我们必须模拟登陆知乎。然而知乎的登录是有验证码的,我们也抓取验证码,并进行输入,才能正常爬取。
更坑的是,用requests.get/post加上cookies 并不能轻松地登录上zhihu,我们要用requests.Session做追踪登录。
我们这样定义:
s = requests.Session()定义完以后,我们只需用s.get(url,headers)访问一次,然后就可以跟踪cookie了,以后的访问都用s.get()代替requests.get()即可
我们知道,模拟登录很重要的一点是”头”,设置了合适的头才能不被认出是蜘蛛。怎么看“头”呢?
我用的是chrome的审查元素功能:右键,审查元素,选择Network
然后打开网页http://www.zhihu.com/#signin。
我们用审查元素查看第一个抓到的包,拉到request headers:

我们把headers做成 python的字典,如下
headers={
‘Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8’,
‘Accept-Encoding’:’gzip, deflate, sdch’,
‘Accept-Language’:’zh-CN,zh;q=0.8’,
‘Cache-Control’:’max-age=0’,
‘Connection’:’keep-alive’,
‘Host’:’www.zhihu.com’,
‘Upgrade-Insecure-Requests’:’1’,
‘User-Agent’:’Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36’}
OK,然后我们看看如何登录,我们输入帐号、密码、验证码(可能出现可能没有),然后同样用chrome的审查元素:
我把自己的帐号密码涂掉了,别想偷看!
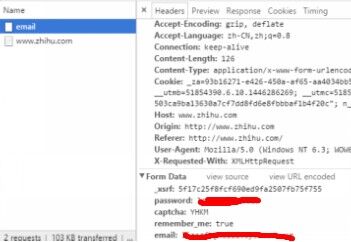
我们可以看到
第一行不知道是什么鬼,第二行是密码,第三行是验证码,第四行是true,第五行是帐号
OK,我们要解决第一行是什么鬼,一般来说这种东西会出现在网页里,我们右键“查看网页源代码”,关键词搜索xsrf 果不其然:
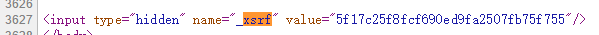
同样的,登录界面里也有同样的xsrf。
我们查看源代码,用正则这样获取
xsrf=re.search(r'"_xsrf" value="(.*)"/>',r1.text).group(1)。
解决XSRF,我们解决验证码问题。我们退出登录回到主页,试着去更换验证码,看看图片是哪个连接获取的,审查元素:
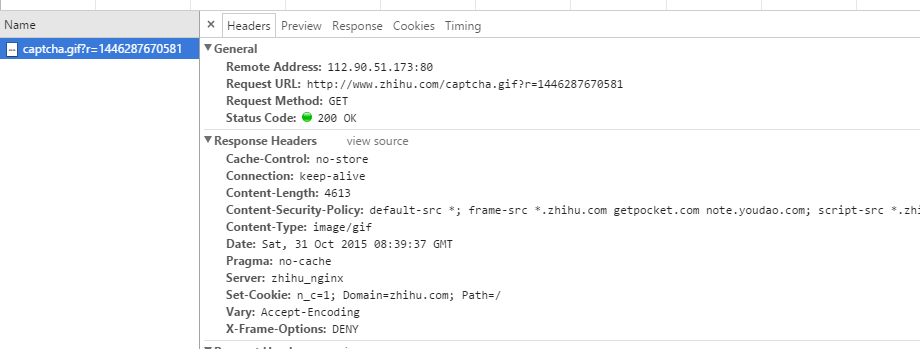
我们看到了请求网址:http://www.zhihu.com/captcha.gif?r=1446287670581
http://www.zhihu.com/captcha.gif 好理解
后面这个?r=1446287670581是什么呢?
其实这是13位时间戳(百度)
我们用time.time()得到的是10位float,我们还要转化为13位:str(int(time.time()*1000))
很易懂吧,OK,我们接下来模拟登录这个
http://www.zhihu.com/captcha.gif
验证码网站,把网页抓下来。
我们用get进行登录,记得之前说的s=requests.Session()吗,我们这样去做:
#p是参数,用于登录
p={'r':str(int(time.time()*1000))}
r2=s.get(url2,params=p,headers=headers_for_veri)
然后把内容保存到本地,方便自己看
#打开文件,二进制写入
op = open(r'D:\guagua\1.gif','wb')
#写入r2的content,也就是验证码图片
op.write(r2.content)
op.close()为了偷懒,我们用PIL库打开文件,路径跟上次的相同!
pic=Image.open(r'D:\guagua\1.gif')
pic.show()
然后文件刷的一下自己打开了hhh
然后我们可以登录了,用之前的header + xrsf+ 验证码+帐号密码
username=raw_input(u'请输入帐号,按回车键结束\n')
password=raw_input(u'请输入密码,按回车键结束\n')
vericode=raw_input(u'请输验证码\n')
data_for_login={
'_xsrf':xsrf,
'password':password,
'captcha':vericode,
'remember_me':'true',
'email':username
}
r3=s.post(url3,data=data_for_login,headers=headers_for_login)然后我们就实现了模拟登录。
下面是模拟登陆全函数:
def login():
url1='http://www.zhihu.com/#signin'
url2="http://www.zhihu.com/captcha.gif"
url3="http://www.zhihu.com/login/email"
#三个没什么卵用的头,用审查元素
header_for_1={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'www.zhihu.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36'
}
headers_for_veri={
'Accept':'image/webp,image/*,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch' ,
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'www.zhihu.com',
'Referer':'http://www.zhihu.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36'
}
headers_for_login = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
#用于获取验证码post访问的参数p
p={'r':str(int(time.time()*1000))}
s.headers.update(header_for_1)
#
r1=s.get(url1)
r2=s.get(url2,params=p,headers=headers_for_veri)
op = open(r'D:\guagua\1.gif','wb')
op.write(r2.content)
op.close()
username=raw_input(u'请输入帐号,按回车键结束\n')
password=raw_input(u'请输入密码,按回车键结束\n')
pic=Image.open(r'D:\guagua\1.gif')
pic.show()
vericode=raw_input(u'请输验证码\n')
xsrf=re.search(r'"_xsrf" value="(.*)"/>',r1.text).group(1)
data_for_login={
'_xsrf':xsrf,
'password':password,
'captcha':vericode,
'remember_me':'true',
'email':username
}
r3=s.post(url3,data=data_for_login,headers=headers_for_login)好了,我们先分析到这里,下一次楼楼再接着讲怎么用lxml库去抓取网页链接,以及怎样用MySQLdb去保存内容~
有交流可以留言或者– 1341414814@qq.com
愿世界拥抱和平
下次见辣















 3543
3543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}