



 文章介绍了如何使用Python的Pandas库处理数据,包括筛选学历为本科且工资在25k-35k的员工,提取salary列中以40k结尾的数据,以及计算薪资区间中最低与最高薪资平均值大于30k的行。最后将这些数据合并并整理成新的DataFrame。
文章介绍了如何使用Python的Pandas库处理数据,包括筛选学历为本科且工资在25k-35k的员工,提取salary列中以40k结尾的数据,以及计算薪资区间中最低与最高薪资平均值大于30k的行。最后将这些数据合并并整理成新的DataFrame。
题目描述
STEP1: 按照下列要求完成各题目
# 由于随机数的存在会影响最终提交的文件,所以这里重新读取数据
# 读取pandas120数据文件
df = pd.read_excel('/home/mw/input/pandas1206855/pandas120.xlsx')
df.head()
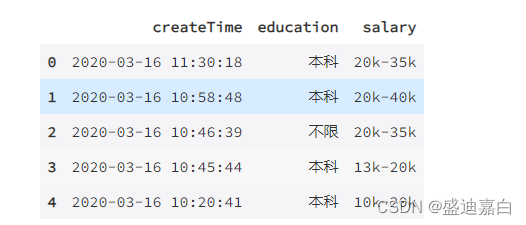
问题1:提取学历为本科,工资在25k-35k的数据
问题2:提取salary列中以'40k'结尾的数据
问题3:提取薪资区间中最低薪资与最高薪资的平均值大于30k的行,只需提取原始字段('createTime', 'education', 'salary')即可
思考一下再来作答吧!
解答过程-代码
#[17]问题1
df1 = df[(df['education'] == '本科') & (df['salary'] == '25k-35k')]
df1
#[19]问题2
df2 = df[df['salary'].str.endswith('40k')]
df2
#[20]问题3
# 将薪资区间转换为最低薪资和最高薪资的数值列
df['min_salary'] = df['salary'].str.extract('(\d+)k-\d+k').astype(float) #'(\d+)k-\d+k'解释:括号()内为要取的值;\d表示数字,\d+表示多个数字;'k-''k'匹配字符串中'k-''k'
df['max_salary'] = df['salary'].str.extract('\d+k-(\d+)k').astype(float) #str.extract() 是 pandas Series 对象上的一个方法,用于从每个字符串中提取匹配给定正则表达式的第一个子串
# 计算最低薪资与最高薪资的平均值大于30k的行
df3 = df[(df['min_salary'] + df['max_salary']) / 2 > 30]
# 选择'createTime', 'education', 'salary'这三个字段
df3 = df3[['createTime', 'education', 'salary']]
df3
4.将以上三题提取出来的行按照相同列进行合并,汇总到一个数据框中;
5. 将三列数据合并成一列,并设置列名为answer,最后保留id(数据行数、answer)
#[21]原文代码,不用改
answer_2 = pd.concat([df1, df2, df3], axis=0)
'''
pd.concat() 是 pandas 库中的一个函数,用于沿着一个轴将多个 DataFrame 或 Series 连接在一起。
在这里,pd.concat([df1, df2, df3], axis=0) 将 df1、df2 和 df3 这三个 DataFrame 沿着轴 0(行轴)连接在一起。
'''
answer_2
#[22] 也不用改动
data = pd.concat([answer_2.iloc[:,0],answer_2.iloc[:,1],answer_2.iloc[:,2]])
df = pd.DataFrame(data, columns=['answer'])
df['id'] = range(len(df))
df = df[['id', 'answer']]
df
6.依次执行step2后面的部分,记得把token码换成自己的!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









