







(一)简介
1.数据模型是描述数据、数据联系、数据语义以及一致性约束的概念工具的集合
2.数据库重要的是:检索、查询、完整性、数据保护
3.关系用来指代表
元组---行(一条记录)
属性----列(名)
4.所有的属性的域应该都是原子的,不可拆分的单元
5.应该尽量避免使用空值
6.数据库模式(database schema):数据库的逻辑设计,如关系模式(relation schema)
数据库实例:给定时刻数据的一个快照
7.关系,的概念对应于程序设计的变量的概念(指代表)
关系模式------类型定义(表名及字段名的定义)
8.超码:可以唯一标识元组的属性名或属性名的集合,比如ID、{ID,name}
候选码:candidate key,最小超码,ID,{name,dept_name}
主码(主键):primary key,被选中的候选码。值从不或极少变化的属性
外码(外键):foreign key,一个关系模式(r1)在它的属性中包含另一个关系模式(r2)的主键,则这个属性在r1上称作参照
r2的外键,关系r1称为外键依赖的参照关系,r2叫外键的被参照关系
9.参照完整性约束:要求在参照关系中任意元组在特定属性上的取值必然等于被参照关系中某个元组在特定属性上的取值。简单
的说,就是在r1(从表)中输入一条记录时,系统要检查外键在r2(主表)主键的取值是否已经存在,存在
则允许输入操作,否则拒绝输入。
10.查询语言:过程化语言,用户指导系统对数据库执行一系列操作以计算出所需结果。(都提供了一组运算)
非过程化语言,用户只需描述所需信息,而不用给出获取该信息的具体过程
11.关系代数:
笛卡尔积:select * from a, b (关系a中的元组与关系b的一个元组所对应,联合起来成为其结果。a表3条记录,b
表4条记录,笛卡尔积结果为3*4=12),where后的谓词筛选出所需的笛卡尔积结果,比如:
select * from a, b where a.id=b.id(多关系查询)
ps:https://zhuanlan.zhihu.com/p/37315832 (仅做部分参考,观点部分正确)
(二)SQL语句
1.numeric(p,d),定点数,这个数有p位数,其中d位数字在小数点右边
2.char(10),如果存入avi则会自动补全7个空格凑足10位,varchar(10)输入avi则不会补全。因此同样存入avi可能导致值并不相
等,所以建议使用varchar类型。其中varchar(10)定义了属性最大长度为10的字符串。(varchar会使用额外的1-2字节来存储值
长度,列长度<=255使用1字节保存,其他情况使用2字节保存。例如varchar(10)会占用11字节存储空间,varchar(500)会占用502
字节存储空间)
3.create table r (A1 D1 , A2 D2 , ...An Dn , <完整性约束1> , ... , <完整性约束k>) ;
示例:create table a (id int(10), name varchar(20) not null, cid int(10), ccid int(10), did int(10),
primary key(id, name), foreign key(cid, ccid) references c(id,cid),
constraint ss foreign key(did) references d(id));
解释:primary key由id和name组成,只要两者有一个在关系中为唯一值即可。(联合主键)
constraint指定外键名字,若省略则系统自动生成
4.建立外键的注意事项:
①建立外键可以只以id为外键(第一主键),也可以以第一主键加第二主键作为外键。不可把第二主键放前面或单独对第二主键
建立外键,以此类推第三主键等等,需要按顺序建立。(最左匹配)
②要创建的外键的数据表A(从表)和关联表B(主表)必须是InnoDB存储引擎
③要创建的A表字段数据类型必须和B表对应的字段的数据类型保持一致,包括长度
5.delete from r [where P](删除所有元组,但保留关系)
drop table r(删除所有元组及其模式)
6.insert into a values(1,'sss');
insert into a(id, name) values('5','ss'); //指定属性顺序,未指定属性值用null填充。values等价于value
insert into a select 25,bname,name,bid,bid from d where id=1; //select结果集插入表中,select的属性数要与a表属性数一致
7.alter table a add A D;
alter table a drop A;
8.update r set s=result [where P];
①update a set status=10 where id=8;
②update a set name = case
when pred1 then result1
when pred2 then result2
...
else result0
end //避免查找顺序影响数据更新
update a set status=case when id=1 then 9 when id=2 then 8 else 10 end;
③标量子查询应用到update
update a set status=(select sum(s) from b where a.id=b.aid and s is not null); //未提及设置为null
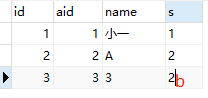


=> update a set status=(
select case when sum(s) is not null then sum(s)
else 0
end
from b where a.id=b.aid and s
);//结果如下图

9.select distinct name, aid from a; 去除重复元组,distinct必须写在选出属性最前面,并且name和aid同时和其他元组重复的元组
才会被去重
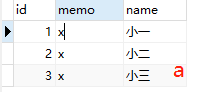
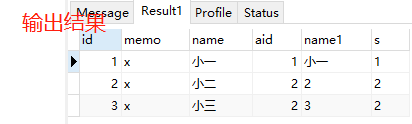
10.自然连接
①select * from a,b where a.id = b.id <=> select * from a natural join b (其中a,b两关系中除了id属性,其他属性不重名)
②select * from a natural join b 输出结果为图三。需要相同属性名的值都相等的关系结果才被筛选出来。相同属性名>a表其余属
性名>b表其余属性名展示
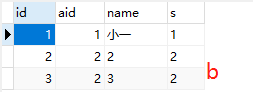
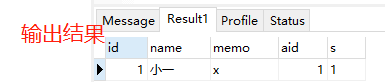
③select * from a natural join b, c where c.aid=a.id
④select * from a natural join b natural join c
⑤指定相等列的自然连接:join r2 using(A1, A2),如将②中的语句改为select * from a join b using(id),其输出结果如下所示
11.更名运算:as(别名作为关系的一个拷贝,下例中a和b是student的两个拷贝)
select distinct a.name from student as a, student as b where a.score>b.score and b.class=1;//查出分数高于一班任意同学分
//数的所有学生名字
其中,a和b被叫做相关名称、表别名、相关变量、元组变量
12.字符串运算
①字符串中插入单引号:insert into a values (6,'it''sme','''')
![]()
②MySQL默认判定两个字符串是否相等时对大小写不敏感,可自行设置
③upper(s)将字符串转换为大写,lower(s)将字符串转换为小写,trim(s)去掉字符串后面的空格,length(s)计算字符串字节长度(
MySQL中在utf8编码下1个汉字3个字节,1个英文占1个字节;utf8_mb4编码下1个汉字4个字节,1个英文占1个字节),
char_length(s)计算字符串的字符长度(1个汉字长度为1,1个英文长度为1)
④串联||,MySQL不支持
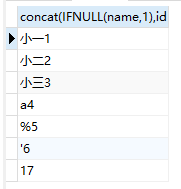
select concat(id,memo,name) from a; //如果id,memo,name任意一个字段值为null则返回null
select concat(IFNULL(name,1),id) from a; //以ifnull的第二个参数填充第一个参数为null时的值,可以是字符串也可是表的某属性
⑤提取子串:left(name,1)从左提取一位
right(name,2)从右提取2位
substr(str,pos,length)从pos处提取length个字符,pos从1开始。length可省略,代表提取pos后全部字符
substr(name,-2,1)从倒数第二个字符开始,提取1个字符。若length省略,则提取倒数第二个字符后面所有字符
substr(name,char_length(name)-3)取除了name字段后三位的其他所有字符
substring_index(name,'.',2)取正数第二个点之前的所有字符,不包括第二个点
substring_index(name,memo,-1)以memo字段值作为分隔符,取倒数第一个memo之后的所有字符
⑥模式匹配like(大小写敏感)%:匹配任意子串,_:匹配任意一个字符
select * from a where name like '_%'; //匹配至少含有一个字符的字符串
select * from a where name like '__'; //匹配两个字符
select * from a where name like '%小%'; //匹配任何包含‘小’的子串
select * from a where name not like '%小%'; //匹配任何不包含‘小’的子串
⑦使用escape关键字定义转义字符:(使用escape后 '\' 的转义功能即失效)
select * from a where name like '$%' escape '$' <=> select * from a where name like '\%'
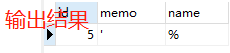
13.select * from a order by name asc, memo desc; //以name升序排列,如果name值相等以memo降序排列,asc可省略不写
14.where id between 3 and 5 <=> where id<=5 and id>=3
where id not between 3 and 5 <=> where id<3 and id>5
15.select * from student a, class b where a.class_id=b.id and b.id=5 <=> ...where (a.class_id,b.id) = (b.id,5)
a1<=b1 and a2<=b2 <=> (a1,a2)<=(b1,b2)
16.集合运算(从a和b关系select出的结果列数需一致)
①并运算(在a中或者在b中)
(select memo from a where name='a') union (select name from b where name='b'); //会去重,a1=a2=b1,结果{a1}
(select memo from a where name='a') union all (select memo from a where name='b'); //不会去重,a1=a2=b1,结果{a1,a2,b1}
②交运算(既在a中也在b中,mysql中没有此关键字)
(select memo from a where name='a') intersect (select name from b where name='b'); //会去重
(select memo from a where name='a') intersect all (select memo from a where name='b'); //a1=a2=b1=b2,结果{b1,b2}
③查运算(mysql中无此关键字)
except、except all
17.空值
select * from a where memo is null;(或 is unknown)
select * from a where memo is not null;(或 is not unknown)
18.聚集函数(以值的一个集合为输入,返回单个值)
①基本聚集
avg、min、max、sum、count(其中sum和avg的输入必须是数字集,非数字集被忽略,其他允许输入字符串)
select sum(distinct memo) from a;
②分组聚集(任何没有出现在group by子句中的属性,如果出现在select子句中的话,它只能出现在聚集函数内部)
select type, count(distinct id) from a group by type;
select type,status,count(id) from a group by type,status; //type和status联合相等才被分为一组
③having子句,用来作为group by的谓词,用来修饰聚集的分组
select type,status,count(id) from a group by type,status having count(id)>2;
select type,status,count(id) as c from a group by type,status having c>2; //对比上一行,having可以用select中聚集函数的重命名
select type,status,count(id) from a group by type,status having type=1; <=>
select type,status,count(id) from a where type=1 group by type,status
④包含聚集、group by、having子句的查询含义可通过下列操作序列定义:
A.先根据from子句来计算出一个关系
B.where子句中的谓词将应用到from子句的结果关系上
C.满足where谓词的元组通过group by子句形成分组,如果没有group by,满足where谓词的整个元组集被当作一个分组
D.having子句将应用到每个分组上,不满足having子句谓词的分组将被抛弃
E.select利用此结果列出需要的结果
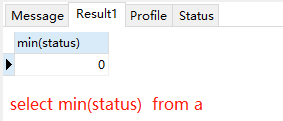
⑤对null值的聚集
如下图id=2的元组status属性值为null,count(status)=0,其他聚集函数返回null



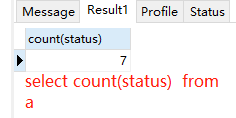

19.嵌套子查询
①集合成员资格
select * from a where id not in ('1','2'); //id不在集合{1,2}中
select id from a where (id,type,status) in (select id,type,status from a where type=1); //id,type,status与二维结果一一对应
②集合的比较(<>all 等价于not in,但 =all 不等价于in;)
select name,status,type from a where status>some(select status from a where type=1);//至少比某一个要大(=any,最好不用) <=>
select distinct a.name,a.status,a.type from a,b where a.status>b.status and b.type=1; //务必加上distinct,因为a和a构成了n*n1
//的组合元组,每条a的元组重复了n1次
select id,name,status,type from a where status<=all(select status from a where type=1); //小于等于所有的
select dept_name from a group by dept_name having avg(salary)>=all(select avg(salary) from a group by dept_name);
//找出平均工资最高的系
③空关系测试(exists结构在作为参数的子查询非空时返回true,分内层外层,外层的一条元组比对内层是否满足)
select * from a where exists (select * from b where b.id=1 and a.id=b.aid); //子查询的结果中是否存在元组
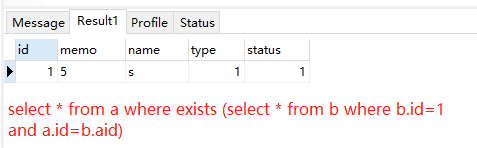

select * from a where not exists (select * from b where b.id=10 and a.id=b.aid); //子查询的结果中是否不存在元组
select * from a where not exists (select * from b where b.id=1 and a.id=b.aid);???
not exists(B except A); //A包含B(超集)
④相关子查询(来自外层的一个相关名称,可以用在where子句的子查询中)
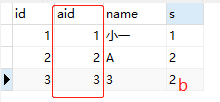
select * from a where status in(select id from b where a.id=aid); //因为查询顺序from->where
ps:如果一个相关名称既在子查询中定义,又在外层的查询中定义,则子查询中的定义有效。如果内层未定义,则使用外层的定义。
⑤重复元组存在性测试(unique用于测试在一个子查询的结果中是否存在重复元组,如果作为参数的子查询结果中没有重复的元组,返回true,被选中)MySQL不支持此函数。
⑥from子句中的子查询(任何select-from-where表达式返回的结果都是关系,因而可以用到from子句中,from子句中的结果属性可以直接用在外层,也可以用as对结果关系的属性进行整体重命名)
select avg(salary) from a group by dept_name having avg(salary) > 20000; //找出系平均工资超过2万元的教师平均工资 <=>
select avg_salary from (select avg(salary) as avg_salary,dept_name from a group by dept_name) where avg_salary > 20000;
select avg_salary from (select avg(salary),dept_name from a group by dept_name) as b (avg_salary,dept_name)
where avg_salary > 20000; //MySQL支持重命名from子句的结果关系,不支持整体重命名结果关系中的属性
select max(tot_salary) from (select dept_name,sum(salary) from a group_by dept_name); //找出所有系中工资总额最大的系
select * from a ,lateral(select s from b where s=a.id) as uu where type=1;//MySQL8.0新特性,允许子查询用到from其他表的属性
⑦with子句(MySQL不支持)
with uu(u) as (select * from a ) select * from b,uu where uu.u = b.s;
with uu(u) as (select id from a ), yy(w) as (select type from c) select * from b,uu,yy where uu.u = b.s and w=1;
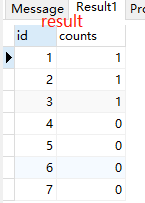
⑧标量子查询(用在select的子查询,其中count(*)是不带group by的聚集函数,返回单个值。也可用在where和having子句中)
select id, (select count(*) from b where a.id=b.aid) as counts from a; //select中子查询的变量可以是出现在外层from关系中的变量
20.null值无法进行+-*/运算















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









