







文章目录
Kafka培训文档
——by佟永硕
一、介绍
1.1简介:
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于Zookeeper协调的分布式日志系统(也可以当做MQ系统[消息系统]),常见可以用于web/Nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
具有横向扩展、容错、wicked fast(变态快)等优点,并已在成千上万家公司运行。
·主要应用场景是:日志收集系统和消息系统。
1.2特性:
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
·通过O(1)的磁盘数据结构提供消息的持久化,即时是数以TB的消息存储也能保持长时间的稳定性能。
【O(1)是最低的时间复杂度,表示无论数据量多大,都能够通过一次计算定位到目标数据】
·高吞吐量:即使是很一般的硬件环境,Kafka也能支持每秒数百万的消息。
·支持Kafka Server之间的消息分区,以及分布式消费。同时保证每个分区内的消息顺序传递。
·同时支持离线数据处理和即时数据处理。
·支持在线水平拓展(scale out)
1.3消息系统介绍(Kafka的主要应用情形)
一个消息系统负责将数据从一个应用传递到另一个应用,应用只需要关注数据本身,无需关注数据是如何在两个或多个应用之间传递的。分布式消息传递依赖于可靠的消息队列(MQ),在客户端应用和消息系统之间异步传递。有两种主要的传递模式:点对点消息传递模式、发布-订阅消息传递模式。Kafka就是发布-订阅模式。
1.3.1点对点消息传递模式
在点对点模式的消息系统中,一个消息持久化到一个消息队列中,这时有一个或多个消费者去消费 队列中的数据。但一个数据只能被消费一次,当一个数据被消费后,就会从消息队列中删除。这使得该模式下,即便有多个消费者同时消费数据,也能保证数据处理的顺序。
*一条数据发送到一个队列中,之后只能被一个消费者所消费。
1.3.2发布-订阅消息传递模式
在发布-订阅模式中,一条消息持久化到一个topic中。与点对点模式不同的是,一个消费者可以订阅一个或多个topic,消费者可以消费某topic中的所有消息,一条消息可以被多个消费者所消费,消息被消费后不会立马删除。在发布-订阅模式中,消息的生产者被称为发布者,消费者被称为订阅者。
*发布者发布一条消息到一个topic中,所有订阅了该topic的订阅者都会收到该消息。
二、Kafka的优点
2.1解耦
在项目启动之初就预测项目将会遇到的需求,是极其困难的。Kafka消息系统在处理过程中插入了一个隐含的、基于数据的接口层。两边的处理过程都要实现这个接口,这使你能够独立的拓展或修改两边的处理过程,只要两边都遵循同样的接口约束。
2.2冗余(副本)(数据持久化)
有时,数据处理的过程会失败,此时除非数据已被持久化处理,否则将造成丢失。使用消息队列将数据进行持久化直到他们已经被完全处理,通过这一方式规避了数据丢失的风险。消息队列遵循“插入-获取-删除”范式,但是在删除之前,要求你的处理程序明确指出该消息已经被完全处理完毕,从而确保了你的一直被安全保存直到你使用完毕。
2.3拓展性
消息队列实现了对处理过程的解耦,所以要对处理过程进行拓展是相当容易的。
2.4灵活性&峰值处理能力
消息队列能够使关键组件顶住突发的大量访问,而不会就此彻底崩溃。
2.5 可恢复性
系统中的一部分组件失效时,不会影响到整个系统。消息队列降低了进程之间的耦合度,即使一个进程挂掉,已经加到消息队列中的数据也可以在系统恢复后继续进行处理。
2.6顺序保证
在大多数情形下,数据处理的顺序是很重要的。大部分消息队列本身就是排序的,并且能保证数据被按照一定的顺序被处理。Kafka保证一个partition内的数据的有序性。
2.7缓冲
消息队列通过一个缓冲层使任务最高效率的执行——写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
2.8异步处理
很多时候,用户不想且不需要去即时处理消息。消息队列提供了异步处理机制,允许将消息放入队列中,但不去立即处理它,当想处理的时候再进行处理。
三、术语
3.1概述
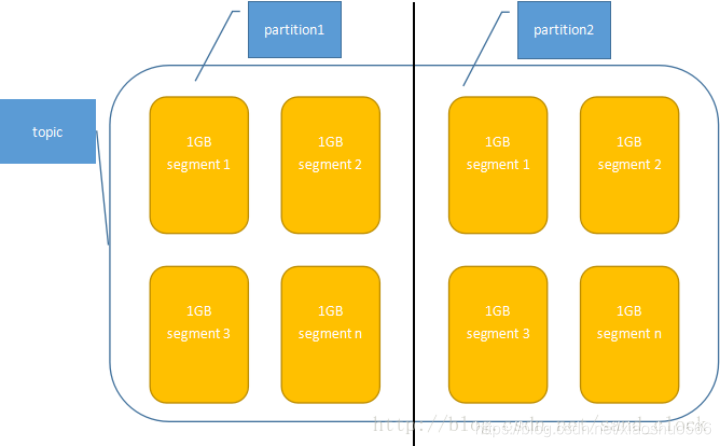
下图展示了Kafka相关术语之间的关系:

3.2术语解释
-
producer:生产者、发布者。产生信息的主体。
-
consumer:消费者、订阅者。消费信息的主体。通过订阅topic来获取消息。
- 多个consumer会属于多个不同的group。如果不手动指定group,那就会属于默认分组(也是一个组)。
- 订阅和消费是以组的名义来进行的。组去申请订阅和消费。
- 一个组内的consumer不能同时消费同一个partition分区下的消息,但是不同组的consumer可以同时消费同一个分区消息。即对一个组来说,他订阅的一个partition只能指派给一个consumer。
- 消费者组是动态维护的,如果一个组内的一个消费者发生了故障,那么他订阅的分区将分配给组内的另一个消费者
- broker:Kafka集群的一个服务器节点。多个broker组成Kafka服务器集群。已发布的消息以topic分类保存在Kafka集群中。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。其下为topic。
- 如果broker 有N个,topic有N个。那么每个broker存放一个topic。
- 如果broker有N+M个,topic有N个。那么有N个broker内各存放一个topic,有M个broker空着。
- 如果broker有N个,topic有N+M个。那么每个broker存放一个或多个topic。应当尽量避免这种情况,会导致集群数据不均衡。 -
topic:主题。Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)。其下为partition。
-
partition:分区。topic的物理分组,每一个partition都是一个有序的、不可改变的消息队列。其下为segment。
-
segment:段。多个大小相同的段组成一个partition。其下为record。
-
record:消息。Kafka中最基本的传递对象,有固定的格式:由key、value和时间戳构成。
-
offset:偏移量。一个连续的用于定位被追加到分区的record消息的序列号,这个偏移量是该分区中一条消息的唯一标示符。也记录了消费者的消费位置信息(消费到哪个消息)【例如,一个位置是5的消费者(说明已经消费了0到4的消息),下一个接收消息的偏移量为5的消息。】。最大值为64位的long大小,19位数字字符长度。。Kafka默认是定期帮你自动提交位移的(enable.auto.commit = true),你当然可以选择手动提交位移实现自己控制。每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了。另外kafka会定期把group消费情况保存起来,做成一个offset map。
3.3其他
- segment由index和data文件组成,两个文件成对出现,分别存储索引和数据。
- segment文件命名规则:对于所有的partition来说,segment名称从0开始,之后的每一个segment名称为上一个segment文件最后一条消息的offset值。
四、下载
登录Apache kafka 官方下载。
https://kafka.apache.org/downloads.html
五、入门须知
5.1kafka有四个核心API:
- 应用程序使用 Producer API 发布消息到1个或多个topic(主题)中。
- 应用程序使用 Consumer API 来订阅一个或多个topic,并处理产生的消息。
- 应用程序使用 Streams API 充当一个流处理器,从1个或多个topic消费输入流,并生产一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。
- Connector API 可构建或运行可重用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可以捕获表的每个变更。
5.2 consumer与offset
offset是由消费者来进行控制的,消费者通过改变实际偏移量来读取对应的消息。消费者之间不会相互影响。
- Client和Server之间的通讯,是通过一条简单、高性能并且和开发语言无关的TCP协议。并且该协议保持与老版本的兼容。Kafka提供了Java Client(客户端)。除了Java客户端外,还有非常多的其它编程语言的客户端。
5.3 分布式
Log分区被分配到集群的多个服务器上,每个服务器负责处理它分到的分区。每个分区还可以被复制到其它服务器,作为备份容错。采用分布式可以平衡负载,避免所有请求都让一个或某几个服务器处理。
5.4 分区(partition)的leader和follower
Kafka允许topic的分区(partition)拥有若干个副本,这个数量是可配置的,你可以配置指定每个topic的分区拥有多少个副本。这些副本中会有一个leader,零或多个follower。leader处理此分区的所有请求,而follower只是从leader那里复制数据。Kafka会自动在每个副本上备份数据,当一个leader宕掉后,会推举一个follower成为新的leader。降低了一个分区宕掉后会导致提交的消息丢失的风险(极端情况下所有分区都宕掉,就需要采取其他策略),即如果配置一个分区拥有N个副本,那么允许N-1个宕掉而不丢失已经提交的消息。
六、使用场景
6.1消息
Kafka更好的替代了传统的消息系统,消息系统被应用于多种场景(解耦消息生产者,缓存未被处理的消息等)。相比传统的消息系统,Kafka拥有在吞吐量、副本、内置分区和故障转移更多的优势,有利于处理大数据量的消息。
6.2网站活动追踪(kafka原本的使用场景)
用户活动追踪,网站的活动(网页游览、搜索或其他用户的操作信息)发布到不同的话题中心,这些消息不仅可以实时处理、实时监测,还可以加载到Hadoop或离线处理数据库。
-tip:【Hadoop用于分布式存储和处理大数据】
6.3指标
kafka也常用于监测数据,分布式程序应用产生的数据统计集中聚合。
6.4日志聚合
许多人使用Kafka作为日志聚合替代品。Kafka抽象出日志文件的细节,并将日志或事件更清晰的抽象出消息流。这允许更快速的处理,并更适合支持多个数据源和分布式消息消费。
6.5流处理
Kafka中消息处理一般是分为多个阶段的。其中原始输入数据是从Kafka主题消费的,然后汇总、丰富或通过其他方法处理转化为新的主题。
6.6事件采集
事件采集是一种应用程序的设计风格,其中状态的变化按照发生时间的顺序记录下来,kafka支持这种非常大的存储日志数据的场景。
6.7提交日志
kafka可以作为一种分布式的外部日志,帮助节点之间复制数据,还可为失败的节点恢复数据重新同步。Kafka的日志压缩功能很好的支持这一用法。
七、windows10下安装和使用
-须知:Kafka依赖于Zookeeper使用,官方下载的Kafka内置了Zookeeper。
7.1.进入kafka官网下载页面
- http://kafka.apache.org/downloads进行下载,选择二进制文件,再选择任意一个镜像文件下载。
- 下载成功后解压到本地文件夹E:\Kafka下面
7.2 关键配置
只需关注bin目录和config目录
-
在kafka根目录下新建data和kafka-logs文件夹,后面要用到,作为kafka快照和日志的存储文件夹
-
进入到config目录,修改service.properties里面log.dirs路径未log.dirs=E:\Kafka\kafka_2.12-2.0.0\kafka-logs(注意:文件夹分割符一定要是”\”)
-
修改zookeeper.properties里面dataDir路径为dataDir=E:\Kafka\kafka_2.12-2.0.0\data
7.3 单机实例测试使用
*windows使用的是路径E:\Kafka\kafka_2.12-2.0.0\bin\windows下批处理命令
*提示:进入指定目录可使用:【cd /dE:\Kafka\kafka_2.12-2.0.0】
步骤:
1)启动kafka内置的zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
·最后一句出现binding to port …表示zookeeper启动成功,不关闭页面。
2)kafka服务启动 ,成功不关闭页面
.\bin\windows\kafka-server-start.bat .\config\server.properties
3)创建topic测试主题kafka,成功不关闭页面
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
注释:
–replication-factor :指定副本数
–partitions :指定分区
–topic :指定主题
4)创建生产者产生消息,不关闭页面
.\bin\windows\kafka-console-producer.bat --broker-list 127.0.0.1:9092 --topic test
提示:1如果使用localhost代替127.0.0.1可能会报DNS无法解析的错误。
2默认监听端口是9092
5)创建消费者接收消息,不关闭页面
.\bin\windows\kafka-console-consumer.bat --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning
7.4 构建Kafka集群
1)额外构建两个Kafka服务器,你需要复制两个server.properties文件,分别命名为server-1.properties和server-2.properties。
你需要修改的配置信息:
server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=E:\kafka_2.11-2.0.0\kafka-logs-1
server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=E:\kafka_2.11-2.0.0\kafka-logs-2
注释: 第一个服务器的默认配置为:
broker.id=0
listeners=PLAINTEXT://:9092
2)按照启动一个服务器的方式,启动新的两个服务器。
提示:注意启动时要指定每个服务器自己对应的properties文件。
3)三个服务器都已经启动后,创建一个新的topic,设置其副本数为3:
.\bin\windows\kafka-topic.bat --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic newTest
4)查看新创建的topic的情况:
.\bin\windows\kafka-topic.bat --describe --zookeeper localhost:2181 --topic newTest
PartitionCount:分区数。
ReplicationFactor:副本数。
Leader:该节点负责该分区的所有读写操作,每个节点的leader都是随机选择的。
Replicas:备份的节点列表,无论这个节点是否还活着,只是显示。
Isr:活着的并且正在同步leader的节点(包括leader节点本身)。
也可以顺便看一下,最开始创建的那个节点情况:
5)向新topic发布消息
.\bin\windows\kafka-console-producer.bat --broker-list 127.0.0.1:9092 --topic newTest
5)消费者消费消息
.bin\windows\kafka-console-consumer.bat --bootstrap-server 127.0.0.1:9092 --from-beginning --topic newTest
7.5 可以测试集群的容错性
1)kill掉leader的进程
2)查看topic状态:会发现有新leader被推举出来了,isr中原leader的serverid没了。
3)消费消息:发现数据没有丢失
七-2、Linux CentOS7 下载、安装、使用Kafka
7-2.1下载和安装
①下载:curl -O https://www-eu.apache.org/dist/kafka/2.3.1/kafka_2.11-2.3.1.tgz
②安装:tar -xzf kafka_2.11-.2.3.1.tgz
*接下来,Linux下操作Kafka的命令都使用bin下.sh后缀的脚本文件。
*基本操作与Windows下一致,仅是命令中路径有些许不同。Linux更好的是不用对配置文件下的日志保存路径等进行重新修改。
7-2.2 启动server
1、进入kafka主目录 : cd kafka_2.11-2.3.1
2、启动zookeeper: bin/zookeeper-server-start.sh config/zookeeper.properties
3\ 启动一个kafka服务: bin/kafka-server-start.sh config/server.properties
7-2.3 创建一个主题
· 创建主题 名为“test” 1分区 1副本: bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
· 创建好后,可以查看已经创建的所有topics : bin/kafka-topics.sh --list --zookeeper localhost:2181
7-2.4 生产者(发布者)发布一个消息
·bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
this is a message! 输入
8.5 消费者(订阅者)消费一个消息(加入默认组)
·bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginnig
this is a message! 输出
7-2.6 创建一个新的消费者组并订阅一个指定的topic
·创建一个新的消费者组并订阅test :bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --consumer-property group1
·查看现在所有的组:bin/kafka-console-consumer.sh --list --bootstrap-server localhost:9092
*注意:新创建的组只能接收到其创建之后的消息,历史消息消费不到!
7-2.7 构建Kafka集群,并测试集群容错性。
·步骤与windows中基本一致。略。
八、生产者API相关使用
生产者是单例的,线程安全的。多个线程共享一个实例。
八、生产者API的相关使用
生产者是单例的,线程安全的。多个线程共享一个实例。
8.1 添加添加依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>
8.2 使用Producer发送一条消息到指定的topic
Properties props = new Properties();
props.put("bootstrap.servers","localhost:9092");//指定kafka服务器
//设置判别请求是否完整(就是请求是否成功),这里设置为all将会阻塞所有消息,这种设置性能最低,但是最可靠。
props.put("acks","all");
//如果请求失败,生产者的重新请求次数,这里为0次。如果启用重复请求,则会有消息重复的可能性(即某条消息被重复发送)。
props.put("retries",0);
//1个生产者消息缓冲区大小。更大的值将会产生更大的批。当设置大于0时,消息不会被立刻发送,而是暂存到缓冲区,然后发送一批消息。可以提高发送效率。
props.put("batch.size",16384);
//该配置将指示生产者在发送消息之前,再逗留1ms,可使更多消息加入到这一批发送中。注意:在高负载下,即便是设置0ms,也会能组成批。
props.put("linger.ms",1);
//控制生产者可用的缓存总量,如果消息发送的速度比传输到服务器的速度快,将会耗尽这个空间。空间耗尽时,新的发送调用将被阻塞,阻塞时间超过设定的阈值值之后,会抛出TimeOutException。
props.put("buffer.memory",33554432);
//将用户提供的key和value对象ProducerRecord转换成字节,你可以使用附带的ByteArraySerializaer或StringSerializer处理简单的byte或string类型。
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
Producer<String,String> producer = new KafkaProducer<String, String>(props);
//send()是异步方法,并且一旦消息被保存在等待发送的消息缓存中,此方法就立即返回。这样并行发送多条消息而不阻塞去等待每一条消息的响应。//ProducerRecord对象的三个参数:topic\key\value
producer.send(new ProducerRecord<String, String>("test","test_record","this is a record from Kafka_Producer"));
//使用完毕后要关闭生产者,否则会造成内存泄漏(即不再使用的变量或对象长久占据一部分内存)
producer.close();
8.3 消息发送请求结果回调
·两个方式:1、阻塞的方式,在send()后调用.get() 2、无阻塞方式:利用在send()中利用请求回调参数CallBack() 的匿名内部类,进行请求完成之后的回调。
·具体见代码如下:
Properties props = new Properties();
props.put("bootstrap.servers","localhost:9092");
props.put("acks","all");
props.put("retries",0);
props.put("batch.size",16384);
props.put("linger.ms",1);
props.put("buffer.memory",33554432);
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
Producer<String,String> producer = new KafkaProducer<String, String>(props);
//请求回调结果是一个RecordMetadata,它指定了消息发送的分区,分配的offset和消息的时间戳。
//1、阻塞调用方式:.get() 这种方式将阻塞其他发送,直到发送完成(指已经发送并保存到了服务器)或抛出异常。相当于是同步的。
//RecordMetadata metadata = producer.send(new ProducerRecord<String, String>("test","test_record","this is a record from Kafka_Producer")).get();
//2、无阻塞方式,利用回调参数进行请求完成时的回调。
ProducerRecord<String,String> record = new ProducerRecord<String, String>("test","test2_record","this is test2_record");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null)//如果抛出了异常,则打印异常
e.printStackTrace();
System.out.println("刚刚发送的消息的offset为:"+recordMetadata.offset());
}
});
producer.close();
九、消费者API相关使用
*消费者是通过控制偏移量来消费消息的。
- 消费者TCP长连接到broker来拉取消息。故障导致的消费者关闭失败,将会泄露这些连接,消费者不是线程安全的.
- 【TCP长连接:建立连接后,可以连续的发送数据包,即便没有数据包需要发送的时候,也会发送检测包来保证连接持续建立,直到明确指定关闭连接】
9.1自动提交偏移量
public void test_1(){
Properties props = new Properties();
props.put("bootstrap.servers","127.0.0.1:9092");
props.put("group.id","group3");//指定消费者组。当指定一个新组时(创建该组),则认为所有消息都是新消息(因为消费记录是以组区分的,组与组之间互不影响)。
props.put("enable.auto.commit","true");//开启自动提交偏移量
props.put("auto.commit.interval.ms","10000");//自动提交频率
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
//earliest:当消费者被创建后,指定主题下若存在没有被该组消费过的历史消息,则消费他们。
//latest: 默认。当消费者被创建后,只消费在其创建后新发布的消息。
props.put("auto.offset.reset","earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test"));//这里可以订阅多个主题
while (true){
ConsumerRecords<String, String> records = consumer.poll(1000);//设置消费超时时间
for (ConsumerRecord<String, String> record : records) {
System.out.println("------------------------------------------------------------");
System.out.println("------------------------------------------------------------");
System.out.printf("| offset = %d , key = %s , value = %s%n",record.offset(),record.key(),record.value());
System.out.println("------------------------------------------------------------");
System.out.println("------------------------------------------------------------");
}
}
}
9.2手动提交偏移量(可以在获取消息之后,正式消费之前进行一些逻辑处理)
/**
* 手动提交偏移量
* @Author: tongys
* @Date: 2019/10/29 11:23
*/
public void test2(){
Properties props = new Properties();
props.put("bootstrap.server","127.0.0.1:9092");
props.put("group.id","group1");
props.put("enable.auto.commit","false");//关闭自动提交
props.put("session.timeout.ms","3000");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserialize");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test"));
final int minBatchSize = 200;//每消费200个数据进行一次入库,然后再修改偏移量(此时才算真正消费)。
List<ConsumerRecord<String,String>> buffer = new ArrayList<>();
while (true){
ConsumerRecords<String,String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize){ //攒够200个消息后
//进行入库操作
//……
//入库结束
consumer.commitAsync();//消费提交,修改偏移量,真正完成一批消息的消费。
buffer.clear();
}
}
}
十、StreamsAPI相关使用(将生产者发布的消息获取转化成流后进行逻辑处理)
10.1利用StreamsAPI 将生产者发布到一个topic中的消息,复制到另一个topic中
public void Streams_Copy(){
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-copy");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
StreamsConfig config = new StreamsConfig(props);
KStreamBuilder builder = new KStreamBuilder();
builder.stream("my-input-topic").mapValues(value -> value.toString()).to("my-output-topic");//将输入到"my-input-topic"中的消息,通过流输出到"my-output-topic"
KafkaStreams kafkaStreams = new KafkaStreams(builder,config);
kafkaStreams.start();
}
十一、Connect API相关使用
11.1介绍:
ConnectAPI中分为两大部分,source和sink。他们作用相反,source负责将数据从异构系统(数据库、日志、mongoDB等)中导入kafka。sink负责将数据从kafka导入异构系统中。
这也说明了该API的作用。
11.2 开源的各种connector
| Connectors | References |
|---|---|
| jdbc | Source, Sink |
| Elastic Search | Sink1, Sink2, Sink3 |
| Cassandra | Source1,Source 2, Sink1, Sink2 |
| MongoDB | Source |
| HBase | Sink |
| Syslog | Source |
| MQTT (Source) | Source |
| Twitter (Source) | Source, Sink |
| S3 | Sink1, Sink2 |
*由于各种connector是在太多,这里只简单举两个例子。
11.3示例:kafka自带的connect file
*test.txt -> (source导入) kafka -> (sink导出)test.sink.txt
1、在kafka的主目录下创建两个txt文件:test.txt和test.sink.txt。
2、修改connect-file-source.properties和connect-file-sink.properties配置文件内容
source:
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=connect-test
sink:
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=test.sink.txt
topics=connect-test
3、启动zookeeper、kafka-server
4、启动connect-source和sink:
bin\windows\connect-standalone.bat config\connect-standalone.properties config\connect- file-source.properties config\connect-file-sink.properties
5、写入内容到test.txt
echo ‘hello’ >> test.txt
echo ‘world’ >> test.txt
6、创建消费者查看“connect-test”这个topic的内容
bin\windows\kafka-console-consumer.bat --bootstrap-server 127.0.0.1:9092 --from-beginning --topic connect-test
7、查看test.sink.txt内容
11.4示例2:connect JDBC
*效果:kafka连接jdbc数据库表后,数据库插入一条数据,kafka服务器的对应topic中就会新增一条消息。
1、在数据库中准备好users\books\colors三张表,users\books两张表的主键名为id,colors表主键名为color_id
2、下载好mysql-connector-java和kafka-connect-jdbc 两个jar包,放到kafka的libs目录下。
3、创建quickstart-mysql.properties配置文件。内容如下:
#name 唯一,不可重复
name=test-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://127.0.0.1:3306/test?user=root&password=123456&useSSL=true
#黑名单:指定不被连接的表。
#table.whitelist 白名单:指定被连接的表。
#黑白名单不能同时存在。
table.blacklist=colors
mode=incrementing
incrementing.column.name=id
topic.prefix=test-mysql-jdbc-
创建quickstart-mysql-2.properties配置文件。内容如下:
#name唯一标识,多个配置文件时不可重复
name=test-mysql-jdbc-autoincrement-2
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://127.0.0.1:3306/test?user=root&password=123456&useSSL=true
#白名单
table.whitelist=colors
mode=incrementing
incrementing.column.name=color_id
topic.prefix=test-mysql-jdbc-
*注意事项:
1、多个配置文件的name不可重复,这是他们的唯一标识
2、mode设置为incrementing时,通过incrementing.column.name指定的主键名xx,来连接到主键名为xx的所有表。
若该数据库存在主键名不为xx的表,则必须在该配置文件中指定白或黑名单来剔除掉这些表,否则会导致连接表失败。
3、topic.prefix 指定自动生成的topic的前缀,前缀后跟的是表名。比如这个示例中会有三个topic:
test-mysql-jdbc-users\test-mysql-jdbc-books\test-mysql-jdbc-colors
*小结:
主要讲述kafka的基本概念和四个API的基本使用方法。更高级的使用要结合实际项目进行。

















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









