










一、概述
1. 背景
2010年的老系统缝缝补补用到了2021年,随着表记录越来越多查询效率很低,研究发现经常有一条SQL语句join 连接5张以上表查询的情况。为了分析出哪些表是优先被优化的,现在需要分析SQL语句都关联的哪些表,每个表被执行了多少次。
2. 先上结果,在说步骤
工作成果放在Excel表上,三个sheet页中

-
SQL内容

-
Table内容

-
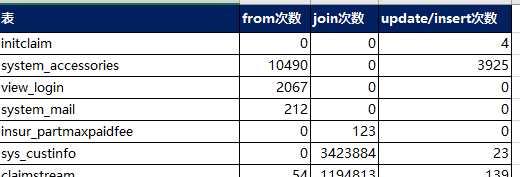
TableTimes 内容
二、操作步骤
-
从数据库缓存中导出了近期执行频率最高的语句,此处用的是Oracle数据库
#直接从sqlarea中获取Oracle缓存统计信息 select --sql_text, sql_id, sql_fulltext, executions, parsing_schema_name, module, first_load_time, last_load_time, last_active_time from v$sqlarea导出到excel中,路径命名 “e:\车辆业务系统近期常用SQL语句.xlsx” (此处是为了和程序保持一致,如果代码能力较强则选择看即可),sheet页为“SQL”, 如下图

-
在"SQL"Sheet页中添加几列,如下标黄列

-
增加“TableTimes” Sheet页,内容为空即可

-
程序实现截取表名,统计表被执行次数。 使用的是Python2,用到了xlwings来操作Excel
# -*- coding:utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import xlwings as xw import re # 保存表对应select,join,update/insert的次数 # 存储格式 {'tablename':{'from':from次数,'join':join次数,'qita':被修改次数}} TablesName={} #记录select ,join,update,insert表次数 def updateDict(type,tabName,exec_Times): if not TablesName.has_key(tabName): # 初始化内侧字典 dic_Times={'from':0,'join':0,'qita':0} #根据修改类型类更新对应值 if type=='from': dic_Times['from']=exec_Times elif type=='join': dic_Times['join']=exec_Times else: dic_Times['qita'] = exec_Times #填充到上层字典中 TablesName.update({tabName: dic_Times}) else: # 获取表名对应字典 dic_Times = TablesName.get(tabName) # 根据修改类型类更新对应值 if type=='from': dic_Times['from']+=exec_Times elif type == 'join': dic_Times['join'] += exec_Times else: dic_Times['qita'] += exec_Times # 更新次数 TablesName[tabName] = dic_Times #获取SQL语句中select 表,join表,update/insert表,及对应操作次数 def extract_table_name_from_sql(sql_str,exec_Times): # 去除注释 /* */ comments q = re.sub(r"/\*[^*]*\*+(?:[^*/][^*]*\*+)*/", "", sql_str) # remove whole line -- and # comments lines = [line for line in q.splitlines() if not re.match("^\s*(--|#)", line)] # remove trailing -- and # comments q = " ".join([re.split("--|#", line)[0] for line in lines]) # 使用正则来分隔 blanks, parens and semicolons tokens = re.split(r"[\s)(;]+", q) #from 表 result = set() get_next = False for token in tokens: if get_next: if token.lower() not in ["", "select"]: tabName=token.replace('"', '').replace('elite_qiche.','') result.add(tabName) updateDict('from',tabName, exec_Times) get_next = False get_next = token.lower() in ["from"] result=list(result) str_result_from=','.join(result) tabnum_zhu = len(result) # join 表 result = set() get_next = False for token in tokens: if get_next: if token.lower() not in ["", "select"]: tabName = token.replace('"', '').replace('elite_qiche.','') result.add(tabName) updateDict('join',tabName, exec_Times) get_next = False get_next = token.lower() in ["join"] result = list(result) str_result_join = ','.join(result) tabnum_join = len(result) # update/insert 表 result = set() get_next = False for token in tokens: if get_next: if token.lower() not in ["", "select"]: tabName = token.replace('"', '').replace('elite_qiche.','') result.add(tabName) updateDict('qita',tabName, exec_Times) get_next = False get_next = token.lower() in ["update", "into"] result = list(result) str_result_qita = ','.join(result) tabnum_qita=len(result) #返回 被from的表,被join的表,被修改的表,总共被查询和修改的次数 return str_result_from,str_result_join,str_result_qita,tabnum_zhu+tabnum_join+tabnum_qita if __name__ == '__main__': filename='e:\车辆业务系统近期常用SQL语句(2021.10.11).xlsx' filename=filename.decode("utf8").encode("gbk") wb = xw.Book(filename) #SQL语句sheet页 print u'开始输出SQL页...' sht = wb.sheets["SQL"] nrow = sht.api.UsedRange.Rows.count for i in range(2, nrow + 1): sql_ori=sht['c'+str(i)].value sql_execTimes=sht['h'+str(i)].value #获取SQL中表名 tables_from,tables_join,tables_qita,tabNum=extract_table_name_from_sql(str(sql_ori).lower(),sql_execTimes) #输出表名,表个数 sht['d' + str(i)].value=tables_from sht['e' + str(i)].value=tables_join sht['f' + str(i)].value=tables_qita sht['g' + str(i)].value=tabNum print '执行进度 {}% '.format(i/nrow*100) #输出相关表被执行次数 print u'开始输出TableTimes页...' sht = wb.sheets['TableTimes'] sht['a1'].value = u'表' sht['b1'].value = u'from次数' sht['c1'].value = u'join次数' sht['d1'].value = u'update/insert次数' i=2 for key,value in TablesName.items(): sht['a' + str(i)].value = key sht['b' + str(i)].value = value['from'] sht['c' + str(i)].value = value['join'] sht['d' + str(i)].value = value['qita'] i+=1 wb.save() wb.app.quit() print u'老大,活干完了,给赏吧! -
到此基本功能已经完成,程序输出应该就是 “SQL”和“TableTimes ”两个sheet页内容了
- SQL内容

- TableTimes 内容
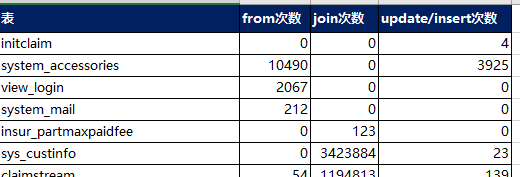
- SQL内容
-
有些人就要问了,“Table”sheet页内容怎么来的呢?
问的好,这快就是一个SQL统计加excel表中Vlookup 匹配结果而已--oracle里查询表行数的语句 SELECT T.TABLE_NAME, --用户下的表 T.NUM_ROWS --表记录数 FROM USER_TABLES T;*注意:这个统计表中统计结果会有延迟,如果需要统计最新的,需要在用户下执行
analyze table tablename compute statistics;批量的可用存储过程实现
存储过程如下:create or replace procedure statistics_all_dep is v_sql varchar2(1000) default ''; begin for rs in ( select t.TABLE_NAME from user_tables t' )loop v_sql :='analyze table '||rs.table_name||' compute statistics'; Execute immediate v_sql; commit; end loop; exception when others then dbms_output.put_line('errm statistics_all_dep:' || sqlerrm); end;















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









