







1. sed
- 概念
sed(stream editor)是一个流编辑器,用于对输入流(或文件)进行基本的文本转换。它特别适合于进行简单的文本替换、删除和插入操作。
- 基本语法
-- 基本语法
sed [options] 'command' file(s)
-- 语法解释
-- options:可选的sed选项,如-i用于直接修改文件。
-- command:要执行的sed命令,通常包含在单引号内。
-- file(s):要处理的文件列表。如果省略文件,sed将从标准输入读取。
-- 常用选项
-e: 允许对输入数据应用多个 sed 命令编辑。
-f: 指定一个包含 sed 命令的文件。
-i: 直接修改文件内容(而不是输出到标准输出)。
-n: 禁止自动打印模式空间的内容。
-r 或 -E: 使用扩展正则表达式(ERE)。
-- 地址匹配
数字:表示行号。
$: 最后一行。
/regexp/: 匹配正则表达式的行。
0,addr2: 从第一行到指定地址的行。
addr1,addr2: 从 addr1 到 addr2 的行。
-- 常用命令
a\: 在当前行之后添加文本。
c\: 替换当前行的文本。
d: 删除行。
i\: 在当前行之前插入文本。
p: 打印行。
s/regexp/replacement/flags: 替换匹配到的内容。其中 flags 可以是:
g: 全局替换。
number: 仅替换第 number 个匹配。
p: 打印替换后的行。
- 案例
- 替换文本
-- 替换文件中所有 "apple" 为 "orange"
sed s/apple/orange/g a.txt
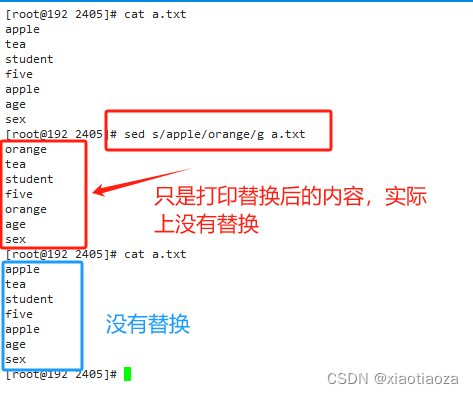
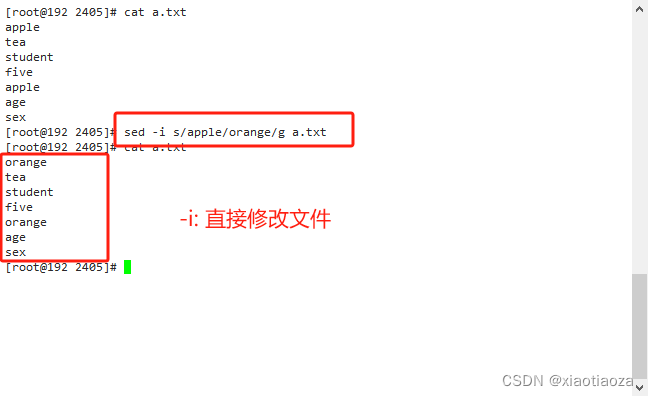
-- 替换文件中所有 "apple" 为 "orange",直接修改文件
sed -i s/apple/orange/g a.txt
-- 将 第2行到第四行的"five" 替换为 "中国"
sed '2,4s/five/中国/g' a.txt

- 删除行
-- 删除包含 "orange" 的行
sed /orange/d a.txt

-- 删除包含 "orange" 的行,直接修改文件
sed -i /orange/d a.txt

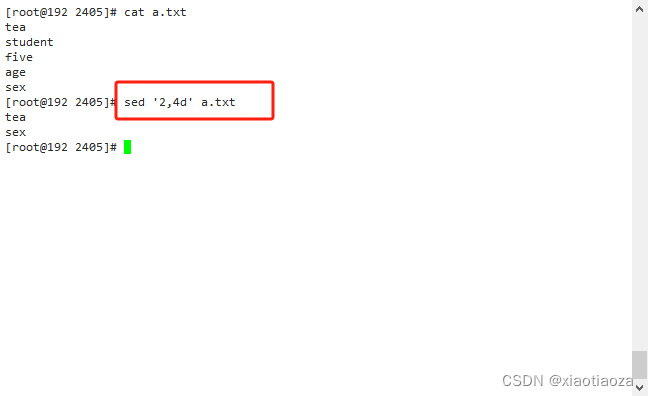
-- 删除第 3 行数据,不直接修改文件
sed '3d' a.txt

-- 删除第 2 行到第 4 行的数据,不直接修改文件
sed 2,4d a.txt
- 插入文本
-- 在每行之前插入 "Hello, "
sed 'i\Hello,' a.txt

-- 在第三行之前插入 "ok "
sed '3i\ok' a.txt

-- 在每行之后插入 "上海"
sed 'a\上海,' a.txt

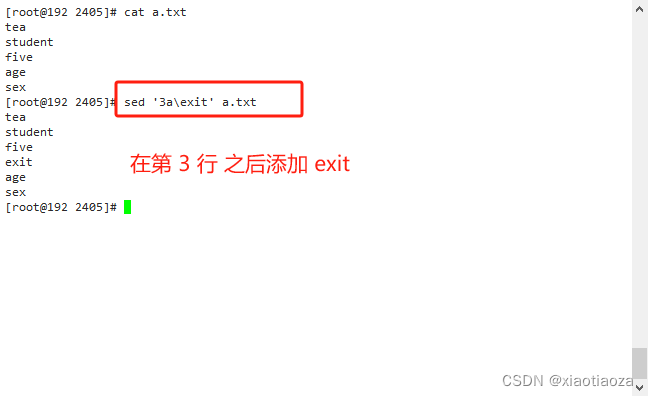
-- 在第三行之后添加 "exit "
sed '3a\exit' a.txt
- 使用多个命令
-- 将 tea 替换为 apple,并且在每行后添加 ‘money’
sed -e 's/tea/apple/g' -e 'a\money' a.txt


- 使用扩展正则表达式
-- 使用扩展正则表达式将 "tea" 或 "student" 替换为"money"
sed -E 's/(tea|student)/money/g' a.txt

- 查询行数据
-- 查询第二行数据
sed -n '2p' a.txt

-- 查询第二行到第四行的数据数据
sed -n '2,4p' a.txt

- 拓展案例
-- 查询空行数据
sed -n '/^$/p' a.txt

-- 查询第 3 行到第 1 个空行的数据
sed -n '3,/^$/p' a.txt

-- 删除第 3 行以外的所有数据
sed '3!d' a.txt

-- 删除空行的数据
sed '/^$/d' a.txt

-- 查询第3行到第1个空行之前的所有数据
sed -e '3,/^$/!d;/^$/d' a.txt

2. grep
- 概念
grep 是 Linux 和 Unix 系统中常用的文本搜索工具,它允许你在文件中搜索特定的字符串或正则表达式模式,并将匹配的行打印到标准输出。
- 基本语法
-- 基本语法
grep [OPTIONS] PATTERN [FILE...]
-- 语法解释:
-- OPTIONS:可选参数,用于指定搜索的行为。
-- PATTERN:要搜索的模式或字符串。
-- FILE...:要搜索的文件列表。如果没有指定文件,grep 会从标准输入(通常是键盘)读取。
-- 常用选项(OPTIONS):
-i:忽略大小写。
-v:反转搜索,只显示不包含模式的行。
-r 或 -R:递归搜索目录中的文件。
-l:只显示包含模式的文件名,不显示匹配的行。
-n:显示匹配行的行号。
-c:计算匹配行的数量,不显示匹配的内容。
-w:只匹配整个单词,而不是字符串的一部分。
-o:只输出匹配的部分,而不是整行。
-e:指定多个模式,每个模式由 -e 引入。
--color 或 --colour:将匹配的部分高亮显示(许多系统默认就启用了此功能)。
-E:使用扩展的正则表达式。
-F:将模式视为固定字符串的列表,而不是正则表达式。
-P:使用 Perl 兼容的正则表达式。
- 案例
- 在文件中搜索字符串 “five”
grep 'five' a.txt

- 忽略大小写搜索 “five”
grep -i 'five' a.txt

- 反转搜索,显示不包含 “five” 的行
grep -v 'five' a.txt

- 显示匹配 “five” 的行及其行号
grep -n 'five' a.txt

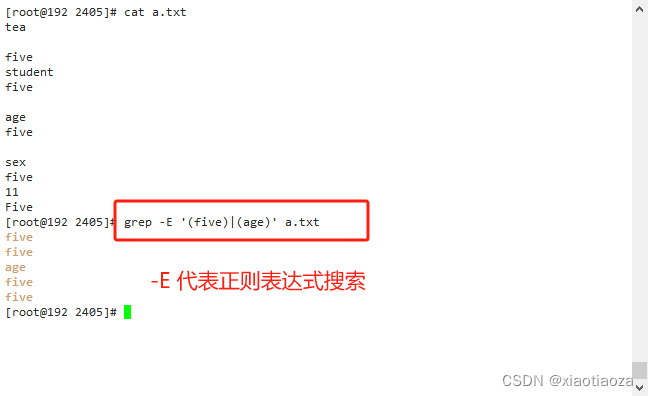
- 使用扩展的正则表达式搜索 “five” 或 “age”
grep -E '(five)|(age)' a.txt
总结:
这只是 grep 的一些基本用法和选项。你可以通过 man grep 命令查看 grep 的手册页,获取更详细的信息和更多选项。
-- 1.查询文件以数字9开头的数据
grep '^9' 1.txt
-- 2.查询包含了数字9的数据
grep '9' 1.txt
-- 3.查询文件中以数字开头的行数据
grep '^[0-9]' 1.txt

3. awk
- 概念
- AWK是一种处理文本文件的语言,是一个强大的文本分析工具。在Linux/Unix中,AWK与grep和sed并称为“三剑客”,其中grep用于过滤文本,sed用于修改文本,而AWK则专注于处理文本。
- AWK主要用于格式化文本和数据的处理。它可以处理来自标准输入、一个或多个文件或其他命令的输出数据。AWK支持用户自定义函数和动态正则表达式等先进功能,是Linux/Unix下的一个强大编程工具。
- 基本语法
-- 基本语法
awk 'pattern { action }' file
-- 语法说明
-- pattern:是一个可选的正则表达式,用于匹配输入的文本行。如果省略,则默认匹配所有行。
-- action:是对匹配到的行执行的操作。
-- file:是要处理的文件名。如果省略,则处理标准输入。
- 基本用法
- 打印文件内容
如果没有指定模式或动作,awk默认会打印每一行。等同于 cat filename。
-- 基本语法
awk '{print}' filename
-- 案例
awk '{print}' 1.txt

- 按行打印
-- 基本语法
awk 'NR==n' filename; -- 打印第 n 行数据
awk 'NR==n {print}' filename; -- 打印第 n 行数据
awk 'NR==n,NR==m' filename; -- 打印第 n 行到第 m 行数据
awk 'NR==n,NR==m {print}' filename; -- 打印第 n 行到第 m 行数据
-- 案例
awk 'NR==2' 1.txt
awk 'NR==2 {print}' 1.txt;
awk 'NR==2,NR==4' 1.txt;
awk 'NR==2,NR==4 {print}' 1.txt;
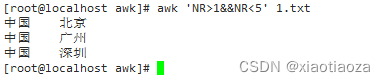
awk 'NR>1&&NR<5' 1.txt;

- 按列打印
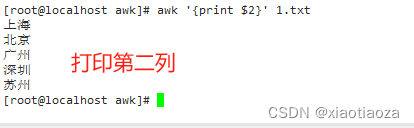
awk默认以空格或制表符作为字段分隔符。$1、$2、$3等表示第一列、第二列、第三列等。
-- 基本语法
awk '{print $1, $2}' filename # 打印第一列和第二列
-- 案例
awk '{print $2}' 1.txt
- 设置字段分隔符
使用-F选项设置字段分隔符。
-- 基本语法
awk -F':' '{print $1}' /etc/passwd # 以冒号为分隔符,打印/etc/passwd中的用户名
-- 案例
awk -F'-' '{print $2}' 2.txt

- 处理匹配的行
使用模式来匹配行。
-- 基本语法
awk '/Tom/ {print}' filename # 打印包含"Tom"的行
awk '!/Tom/ {print}' filename # 打印包含"Tom"的行
-- 案例
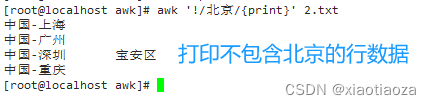
awk '/北京/{print}' 2.txt;
awk '!/北京/{print}' 2.txt;

- 内建变量
NR:记录行号。
NF:每一行的列数。
$0:每一行的内容。
-- 基本语法
awk '{print NR, $0}' filename # 打印行号和整行内容
awk '{print NF}' filename # 打印每行的字段数
-- 案例
awk '{print NR,$0}' 2.txt;
awk '{print NF}' 2.txt;

- 条件语句
使用if、else等条件语句。
-- 基本语法
awk '{if ($2 > 20) print $1, $2}' filename # 打印年龄大于20的姓名和年龄
-- 案例
awk '{if($2>20) print $1,$2}' 3.txt

- 循环语句
使用for、while等循环语句。
-- 基本语法
awk '{for(i=1; i<=NF; i++) print $i}' filename # 逐列打印
-- 案例
awk '{for(i=1;i<=NF;i++) print $i}' 3.txt
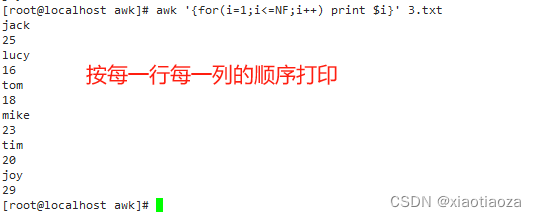
- BEGIN和END
BEGIN块在读取任何输入文件之前执行,而END块在所有输入行都被处理之后执行。
-- 基本语法
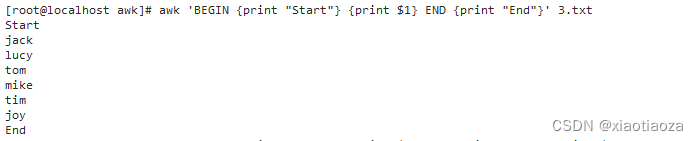
awk 'BEGIN {print "Start"} {print $1} END {print "End"}' filename
-- 案例
awk 'BEGIN {print "Start"} {print $1} END {print "End"}' 3.txt
- 数组
awk支持数组,可以用来存储和处理数据。
-- 基本语法
awk '{name[NR] = $1} END {for(i=1; i<=NR; i++) print name[i]}' filename
-- 案例
awk '{name[NR]=$2} END {for(i=1;i<=NR;i++) print name[i]}' 3.txt

-- 案例1
-- 1. 准备数据文件内容 (data.txt)
Tom 20 80
Jerry 22 90
Spike 21 75
-- 2. 打印年龄大于20的人的名字和年龄
awk '{if($2>20) print $1,$2}' data.txt
-- 3. 计算所有人的年龄总和
awk '{sum += $2} END {print "Total age:", sum}' data.txt
-- 4. 查找名字为Tom的人的信息
awk '/Tom/{print}' data.txt;
awk '$1 == "Tom" {print}' data.txt;
-- 案例2
-- 1. 准备数据文件内容 (emp.txt)
7369,SMITH,CLERK,7902,1980/12/17 星期三,900,,20
7499,ALLEN,SALESMAN,7698,1981/2/20 星期五,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22 星期日,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2 星期四,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28 星期一,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1 星期五,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9 星期二,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19 星期日,3000,,20
7839,KING,PRESIDENT,,1981/11/17 星期二,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8 星期二,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23 星期六,1100,,20
7900,JAMES,CLERK,7698,1981/12/3 星期四,950,,30
7902,FORD,ANALYST,7566,1981/12/3 星期四,3000,,20
7934,MILLER,CLERK,7782,1982/1/23 星期六,1300,,10
-- 2. 查询员工薪资低于3000的信息
awk -F ',' '$6<3000' emp.txt;
awk -F ',' '{if($6<3000) print $0}' emp.txt;
-- 3. 查询20号部门岗位是MANAGER的员工信息
awk -F ',' '$8==20&&$3=="MANAGER"' emp.txt;
awk -F ',' '{if($8==20&&$3=="MANAGER") print $0}' emp.txt;
--4. 查询员工薪资大于1800且是10号部门的员工信息
awk -F ',' '$6>1800&&$8==10' emp.txt;
awk -F ',' '{if($6>1800&&$8==10) print $0}' emp.txt;
-- 5. 查询30号部门或者岗位不是CLERK的员工信息
awk -F ',' '$8==30||$3!="CLERK"' emp.txt;
awk -F ',' '{if($8==30||$3!="CLERK") print $0}' emp.txt;
-- 6. 判断员工薪资的等级
awk -F ',' '{if($6<1600) print $2,$6,"C";else if($6>2850) print $2,$6,"A";else print $2,$6,"B"}' emp.txt
-- 7. 查询每一个年份入职的员工人数分别有多少,对结果进行排序
awk -F "," '{print $5}' emp.txt|awk -F "/" '{print $1}'|sort|uniq -c|sort -n -r
-- 8. 打印员工的奖金,如果有就打印有奖金,无则打印无奖金
awk -F ',' '{if($7>0) print $2,$7,"有奖金";else print $2,$7,"无奖金"}' emp.txt
-- 9. 打印被分隔符切割后的每行的列数
awk -F ',' '{print NF}' emp.txt
-- 10. 打印文件的最后1列数据
awk -F ',' '{print $NF}' emp.txt
-- 11. 打印文件第三行倒数第三列的数据
sed -n '3p' emp.txt|awk -F ',' '{print $(NF-2)}'
>>
- 定义:>> 是一个输出重定向操作符,它会把命令的标准输出(stdout)追加到指定的文件中,而不是覆盖指定文件的内容。
- 用途:当你想要保存命令的输出到文件,并且不希望覆盖文件中已有的内容时,就可以使用 >>。
- 总结:如果文件不存在,它会创建文件;如果文件已经存在,它会在文件的末尾追加新内容,而不会删除原有内容。
-- 基本语法
command >> filename
-- 语法说明
-- command 是你想要执行的命令。
-- filename 是你想要将输出追加到的文件名。
-- 案例
-- 1. 将echo命令的输出追加到文件
echo "Hello, World!" >> output.txt
-- 2. 将ls命令的输出追加到文件
ls -l >> directory_list.txt
>
- 定义:> 是一个输出重定向操作符,它用于将命令的标准输出(stdout)写入到指定的文件或设备中。
- 用途:当你想要保存命令的输出到文件,或者将输出发送到其他命令或设备时,就可以使用 >。
- 总结:如果文件不存在,则创建文件;如果文件已存在,则覆盖原有内容。
-- 基本语法
command > filename
-- 语法说明
-- command 是你想要执行的命令。
-- filename 是你想要将输出追加到的文件名。
-- 工作原理
-- 1. 如果指定的 filename 不存在,> 操作符将会创建这个文件,并将命令的输出写入到文件中。
-- 2. 如果 filename 已经存在,> 操作符将会覆盖这个文件的内容,将原有的内容删除,并将命令的输出写入到文件中。
-- 案例
-- 1. 将echo命令的输出保存到文件
echo "Hello, World!" > output.txt
-- 2. 将ls命令的输出保存到文件
ls -l > directory_list.txt
4. Linux其他常用指令
4.1 cut
- Linux中的cut命令是一个用于从文本文件中提取特定字段或字符的实用程序。
- cut命令主要用于处理简单的文本数据。对于更复杂的文本处理任务,可能需要使用如awk或sed等更强大的工具。
- 如果输入行中的字段数量少于cut命令指定的字段号,cut会输出空行。
-- 基本语法
cut [选项] [分隔符] [字段列表] [文件]
-- 选项:
-d 或 --delimiter:指定用于分隔字段的分隔符。默认分隔符为空格或制表符。
-f 或 --fields:指定要提取的字段列表。字段可以通过数字或字符范围指定。
-c 或 --characters:指定要提取的特定字符范围。
-b 或 --bytes:指定要提取的特定字节范围。
-s 或 --only-delimited:抑制空行或空白字段的输出。
--complement:补充模式,提取未被-b, -c, 或-f选项指定的部分。
--output-delimiter:修改输出时使用的分隔符。
-- 字段列表:
可以采取以下形式:
单个字段:例如-f 3。
字段范围:例如-f 2-4。
字符范围:例如-c 10-15。
字节范围:例如-b 100-200。
案例:从以冒号分隔的文件中提取第二个字段
1. 准备数据文件
中国:上海:浦东新区
中国:北京:海淀区
中国:广州:天河区
中国:深圳:南山区
2. 基本语法
cut -d : -f 2 file.txt;
cut -d : -f 2 4.txt;
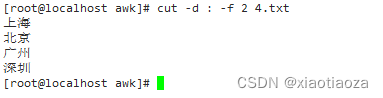
-- 案例:从以制表符分隔的文件中提取第一个和第三个字段
3. 准备数据文件
中国 上海 浦东新区
中国 北京 海淀区
中国 广州 天河区
中国 深圳 南山区
4. 基本语法
cut -f 1,3 file.txt;
cut -f 1,3 4.txt;
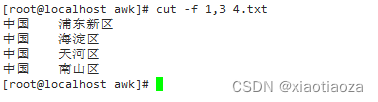
-- 案例:从文本文件中提取前10个字符(空格或制表符代表一个字符)
5. 准备数据文件
中国 上海 浦东新区 金融中心
中国 北京 海淀区 政治中心
中国 广州 天河区 外贸中心
中国 深圳 南山区 科技中心
6. 基本语法
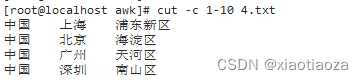
cut -c 1-10 file.txt;
cut -c 1-10 4.txt;
4.2 find
find命令是一个强大的工具,用于在目录树中查找文件。
-- 基本语法
find [路径] [选项] [表达式]
-- 语法说明
路径:指定开始搜索的目录路径。如果不指定,则默认为当前目录及其子目录。
选项:用于修改搜索行为的参数。
表达式:用于匹配文件或目录的条件。
-- 路径参数
.:当前目录。
/:根目录,搜索整个文件系统。
-- 基本表达式
-name:按文件名查找。
-type:按文件类型查找(如f表示普通文件,d表示目录)。
-perm:按权限查找。
-user:按文件拥有者查找。
-group:按文件所属组查找。
-size:按文件大小查找。
-mtime、-atime、-ctime:按文件修改、访问、状态改变时间查找。
-- 其他选项
-maxdepth:设置搜索的最大目录深度。
-mindepth:设置搜索的最小目录深度。
-exec:对匹配的文件执行指定的命令。
-print:打印匹配的文件名(默认行为)。
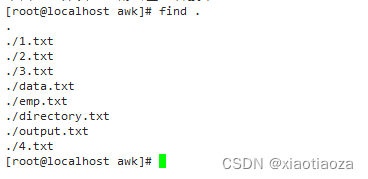
-- 案例1:查找当前目录及其子目录下的所有文件
find .
-- 案例2:在根目录下查找名为"output.txt"的文件
find / -name "output.txt"

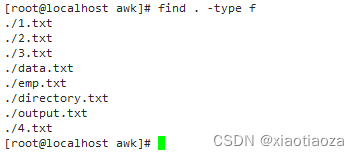
-- 案例3:在当前目录及其子目录下查找所有普通文件
find . -type f
-- 案例4:在/path/to/search目录下查找属于特定用户"username"的文件
find /path/to/search -user username
-- 案例5:在/path/to/search目录下查找权限为644的文件
find /path/to/search -perm 644
-- 案例6:在/path/to/search目录下查找大于1M的文件
find /path/to/search -size +1M
-- 案例7:对匹配的文件执行操作,如删除所有扩展名为".txt"的文件
find /path/to/search -name "*.txt" -exec rm {} \;















 8470
8470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









