







上篇文章 PE文件结构详解(二)可执行文件头 的结尾出现了一个大数组,这个数组中的每一项都是一个特定的结构,通过函数获取数组中的项可以用RtlImageDirectoryEntryToData函数,DataDirectory中的每一项都可以用这个函数获取,函数原型如下:
PVOID NTAPI RtlImageDirectoryEntryToData(PVOID Base, BOOLEAN MappedAsImage, USHORT Directory, PULONG Size);
Base:模块基地址。
MappedAsImage:是否映射为映象。
Directory:数据目录项的索引。
- #define IMAGE_DIRECTORY_ENTRY_EXPORT 0 // Export Directory
- #define IMAGE_DIRECTORY_ENTRY_IMPORT 1 // Import Directory
- #define IMAGE_DIRECTORY_ENTRY_RESOURCE 2 // Resource Directory
- #define IMAGE_DIRECTORY_ENTRY_EXCEPTION 3 // Exception Directory
- #define IMAGE_DIRECTORY_ENTRY_SECURITY 4 // Security Directory
- #define IMAGE_DIRECTORY_ENTRY_BASERELOC 5 // Base Relocation Table
- #define IMAGE_DIRECTORY_ENTRY_DEBUG 6 // Debug Directory
- // IMAGE_DIRECTORY_ENTRY_COPYRIGHT 7 // (X86 usage)
- #define IMAGE_DIRECTORY_ENTRY_ARCHITECTURE 7 // Architecture Specific Data
- #define IMAGE_DIRECTORY_ENTRY_GLOBALPTR 8 // RVA of GP
- #define IMAGE_DIRECTORY_ENTRY_TLS 9 // TLS Directory
- #define IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG 10 // Load Configuration Directory
- #define IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT 11 // Bound Import Directory in headers
- #define IMAGE_DIRECTORY_ENTRY_IAT 12 // Import Address Table
- #define IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT 13 // Delay Load Import Descriptors
- #define IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR 14 // COM Runtime descriptor
Size:对应数据目录项的大小,比如Directory为0,则表示导出表的大小。
返回值表示数据目录项的起始地址。
这次来看看第一项:导出表。导出表是用来描述模块中的导出函数的结构,如果一个模块导出了函数,那么这个函数会被记录在导出表中,这样通过GetProcAddress函数就能动态获取到函数的地址。函数导出的方式有两种,一种是按名字导出,一种是按序号导出。这两种导出方式在导出表中的描述方式也不相同。模块的导出函数可以通过Dependency walker工具来查看:

上图中红框位置显示的就是模块的导出函数,有时候显示的导出函数名字中有一些符号,像 ??0CP2PDownloadUIInterface@@QAE@ABV0@@Z,这种是导出了C++的函数名,编译器将名字进行了修饰。
下面看一下导出表的定义吧:
- typedef struct _IMAGE_EXPORT_DIRECTORY {
- DWORD Characteristics;
- DWORD TimeDateStamp;
- WORD MajorVersion;
- WORD MinorVersion;
- DWORD Name;
- DWORD Base;
- DWORD NumberOfFunctions;
- DWORD NumberOfNames;
- DWORD AddressOfFunctions; // RVA from base of image
- DWORD AddressOfNames; // RVA from base of image
- DWORD AddressOfNameOrdinals; // RVA from base of image
- } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
结构还算比较简单,具体每一项的含义如下:
Characteristics:现在没有用到,一般为0。
TimeDateStamp:导出表生成的时间戳,由连接器生成。
MajorVersion,MinorVersion:看名字是版本,实际貌似没有用,都是0。
Name:模块的名字。
Base:序号的基数,按序号导出函数的序号值从Base开始递增。
NumberOfFunctions:所有导出函数的数量。
NumberOfNames:按名字导出函数的数量。
AddressOfFunctions:一个RVA,指向一个DWORD数组,数组中的每一项是一个导出函数的RVA,顺序与导出序号相同。
AddressOfNames:一个RVA,依然指向一个DWORD数组,数组中的每一项仍然是一个RVA,指向一个表示函数名字。
AddressOfNameOrdinals:一个RVA,还是指向一个WORD数组,数组中的每一项与AddressOfNames中的每一项对应,表示该名字的函数在AddressOfFunctions中的序号。
第一次接触这个结构的童鞋被后面的5项搞晕了吧,理解这个结构比结构本身看上去要复杂一些,文字描述不管怎么说都显得晦涩,所谓一图胜千言,无图无真相,直接上图:

在上图中,AddressOfNames指向一个数组,数组里保存着一组RVA,每个RVA指向一个字符串,这个字符串即导出的函数名,与这个函数名对应的是AddressOfNameOrdinals中的对应项。获取导出函数地址时,先在AddressOfNames中找到对应的名字,比如Func2,他在AddressOfNames中是第二项,然后从AddressOfNameOrdinals中取出第二项的值,这里是2,表示函数入口保存在AddressOfFunctions这个数组中下标为2的项里,即第三项,取出其中的值,加上模块基地址便是导出函数的地址。如果函数是以序号导出的,那么查找的时候直接用序号减去Base,得到的值就是函数在AddressOfFunctions中的下标。
用代码实现如下:
- DWORD* CEAT::SearchEAT( const char* szName)
- {
- if (IS_VALID_PTR(m_pTable))
- {
- bool bByOrdinal = HIWORD(szName) == 0;
- DWORD* pProcs = (DWORD*)((char*)RVA2VA(m_pTable->AddressOfFunctions));
- if (bByOrdinal)
- {
- DWORD dwOrdinal = (DWORD)szName;
- if (dwOrdinal < m_pTable->NumberOfFunctions && dwOrdinal >= m_pTable->Base)
- {
- return &pProcs[dwOrdinal-m_pTable->Base];
- }
- }
- else
- {
- WORD* pOrdinals = (WORD*)((char*)RVA2VA(m_pTable->AddressOfNameOrdinals));
- DWORD* pNames = (DWORD*)((char*)RVA2VA(m_pTable->AddressOfNames));
- for (unsigned int i=0; i<m_pTable->NumberOfNames; ++i)
- {
- char* pNameVA = (char*)RVA2VA(pNames[i]);
- if (strcmp(szName, pNameVA) != 0)
- {
- continue;
- }
- return &pProcs[pOrdinals[i]];
- }
- }
- }
- return NULL;
- }
-
-
-
<四>PE导入表
-
-
PE文件结构详解(二)可执行文件头的最后展示了一个数组,PE文件结构详解(三)PE导出表中解释了其中第一项的格式,本篇文章来揭示这个数组中的第二项:IMAGE_DIRECTORY_ENTRY_IMPORT,即导入表。
也许大家注意到过,在IMAGE_DATA_DIRECTORY中,有几项的名字都和导入表有关系,其中包括:IMAGE_DIRECTORY_ENTRY_IMPORT,IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT,IMAGE_DIRECTORY_ENTRY_IAT和IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT这几个导入都是用来干什么的,他们之间又是什么关系呢?听我慢慢道来。
- IMAGE_DIRECTORY_ENTRY_IMPORT就是我们通常所知道的导入表,在PE文件加载时,会根据这个表里的内容加载依赖的DLL,并填充所需函数的地址。
- IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT叫做绑定导入表,在第一种导入表导入地址的修正是在PE加载时完成,如果一个PE文件导入的DLL或者函数多那么加载起来就会略显的慢一些,所以出现了绑定导入,在加载以前就修正了导入表,这样就会快一些。
- IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT叫做延迟导入表,一个PE文件也许提供了很多功能,也导入了很多其他DLL,但是并非每次加载都会用到它提供的所有功能,也不一定会用到它需要导入的所有DLL,因此延迟导入就出现了,只有在一个PE文件真正用到需要的DLL,这个DLL才会被加载,甚至于只有真正使用某个导入函数,这个函数地址才会被修正。
- IMAGE_DIRECTORY_ENTRY_IAT是导入地址表,前面的三个表其实是导入函数的描述,真正的函数地址是被填充在导入地址表中的。
这个代码调用了一个RegOpenKeyW的导入函数,我们看到其opcode是FF 15 00 00 19 30气质FF 15表示这是一个间接调用,即call dword ptr [30190000] ;这表示要调用的地址存放在30190000这个地址中,而30190000这个地址在导入地址表的范围内,当模块加载时,PE 加载器会根据导入表中描述的信息修正30190000这个内存中的内容。
那么导入表里到底记录了那些信息,如何根据这些信息修正IAT呢?我们一起来看一下导入表的定义:
使用RtlImageDirectoryEntryToData并将索引号传1,会得到一个如上结构的指针,实际上指向一个上述结构的数组,每个导入的DLL都会成为数组中的一项,也就是说,一个这样的结构对应一个导入的DLL。- typedef struct _IMAGE_IMPORT_DESCRIPTOR {
- union {
- DWORD Characteristics; // 0 for terminating null import descriptor
- DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
- } DUMMYUNIONNAME;
- DWORD TimeDateStamp; // 0 if not bound,
- // -1 if bound, and real date\time stamp
- // in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
- // O.W. date/time stamp of DLL bound to (Old BIND)
- DWORD ForwarderChain; // -1 if no forwarders
- DWORD Name;
- DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
- } IMAGE_IMPORT_DESCRIPTOR;
- typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
Characteristics和OriginalFirstThunk:一个联合体,如果是数组的最后一项Characteristics为0,否则OriginalFirstThunk保存一个RVA,指向一个IMAGE_THUNK_DATA的数组,这个数组中的每一项表示一个导入函数。
TimeDateStamp:映象绑定前,这个值是0,绑定后是导入模块的时间戳。
ForwarderChain:转发链,如果没有转发器,这个值是-1。
Name:一个RVA,指向导入模块的名字,所以一个IMAGE_IMPORT_DESCRIPTOR描述一个导入的DLL。
FirstThunk:也是一个RVA,也指向一个IMAGE_THUNK_DATA数组。
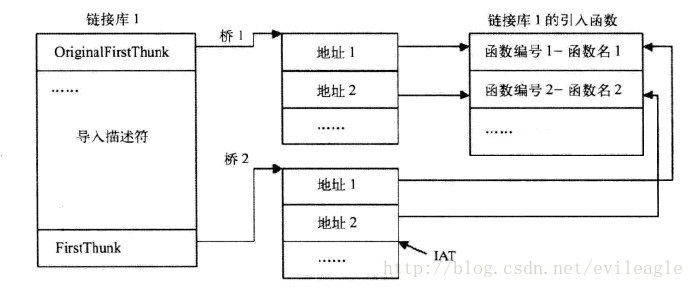
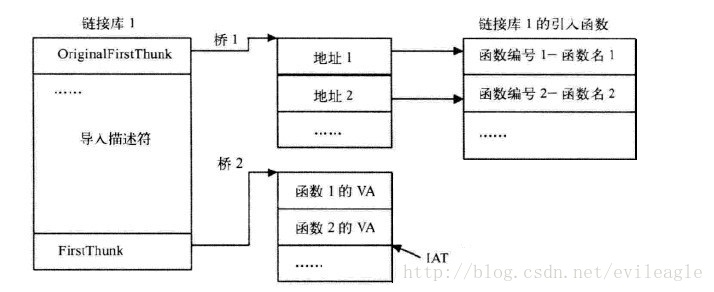
既然OriginalFirstThunk与FirstThunk都指向一个IMAGE_THUNK_DATA数组,而且这两个域的名字都长得很像,他俩有什么区别呢?为了解答这个问题,先来认识一下IMAGE_THUNK_DATA结构:ForwarderString是转发用的,暂时不用考虑,Function表示函数地址,如果是按序号导入Ordinal就有用了,若是按名字导入AddressOfData便指向名字信息。可以看出这个结构体就是一个大的union,大家都知道union虽包含多个域但是在不同时刻代表不同的意义那到底应该是名字还是序号,该如何区分呢?可以通过Ordinal判断,如果Ordinal的最高位是1,就是按序号导入的,这时候,低16位就是导入序号,如果最高位是0,则AddressOfData是一个RVA,指向一个IMAGE_IMPORT_BY_NAME结构,用来保存名字信息,由于Ordinal和AddressOfData实际上是同一个内存空间,所以AddressOfData其实只有低31位可以表示RVA,但是一个PE文件不可能超过2G,所以最高位永远为0,这样设计很合理的利用了空间。实际编写代码的时候微软提供两个宏定义处理序号导入:IMAGE_SNAP_BY_ORDINAL判断是否按序号导入,IMAGE_ORDINAL用来获取导入序号。- typedef struct _IMAGE_THUNK_DATA32 {
- union {
- DWORD ForwarderString; // PBYTE
- DWORD Function; // PDWORD
- DWORD Ordinal;
- DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME
- } u1;
- } IMAGE_THUNK_DATA32;
- typedef IMAGE_THUNK_DATA32 * PIMAGE_THUNK_DATA32;
这时我们可以回头看看OriginalFirstThunk与FirstThunk,OriginalFirstThunk指向的IMAGE_THUNK_DATA数组包含导入信息,在这个数组中只有Ordinal和AddressOfData是有用的,因此可以通过OriginalFirstThunk查找到函数的地址。FirstThunk则略有不同,在PE文件加载以前或者说在导入表未处理以前,他所指向的数组与OriginalFirstThunk中的数组虽不是同一个,但是内容却是相同的,都包含了导入信息,而在加载之后,FirstThunk中的Function开始生效,他指向实际的函数地址,因为FirstThunk实际上指向IAT中的一个位置,IAT就充当了IMAGE_THUNK_DATA数组,加载完成后,这些IAT项就变成了实际的函数地址,即Function的意义。还是上个图对比一下:
上图是加载前。
上图是加载后。
最后总结一下:
- 导入表其实是一个IMAGE_IMPORT_DESCRIPTOR的数组,每个导入的DLL对应一个IMAGE_IMPORT_DESCRIPTOR。
- IMAGE_IMPORT_DESCRIPTOR包含两个IMAGE_THUNK_DATA数组,数组中的每一项对应一个导入函数。
- 加载前OriginalFirstThunk与FirstThunk的数组都指向名字信息,加载后FirstThunk数组指向实际的函数地址。
















 6339
6339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









