







 本文介绍了K-Means聚类算法的原理与Python实现,通过一个实例展示了如何进行聚类。文章讨论了K-Means的初始化方法,包括随机初始化和指定初始质心,并通过具体代码解释了不同初始化方式对聚类结果的影响,强调了初始化选择的重要性。
本文介绍了K-Means聚类算法的原理与Python实现,通过一个实例展示了如何进行聚类。文章讨论了K-Means的初始化方法,包括随机初始化和指定初始质心,并通过具体代码解释了不同初始化方式对聚类结果的影响,强调了初始化选择的重要性。
def k_means(X, n_clusters, init='k-means++', precompute_distances='auto',
n_init=10, max_iter=300, verbose=False,
tol=1e-4, random_state=None, copy_x=True, n_jobs=1,
algorithm="auto", return_n_iter=False): init : {'k-means++', 'random', or ndarray, or a callable}, optional
Method for initialization, default to 'k-means++':
'k-means++' : selects initial cluster centers for k-mean
clustering in a smart way to speed up convergence. See section
Notes in k_init for more details.
'random': generate k centroids from a Gaussian with mean and
variance estimated from the data.
If an ndarray is passed, it should be of shape (n_clusters, n_features)
and gives the initial centers.
If a callable is passed, it should take arguments X, k and
and a random state and return an initialization.
if n_clusters == 1:
# elkan doesn't make sense for a single cluster, full will produce
# the right result.
algorithm = "full"
if algorithm == "auto":
algorithm = "full" if sp.issparse(X) else 'elkan'
if algorithm == "full":
kmeans_single = _kmeans_single_lloyd
elif algorithm == "elkan":
kmeans_single = _kmeans_single_elkan
else:
raise ValueError("Algorithm must be 'auto', 'full' or 'elkan', got"
" %s" % str(algorithm))
def _kmeans_single_elkan(X, n_clusters, max_iter=300, init='k-means++',
verbose=False, x_squared_norms=None,
random_state=None, tol=1e-4,
precompute_distances=True):
centers = _init_centroids(X, n_clusters, init, random_state=random_state,
x_squared_norms=x_squared_norms)
centers = np.ascontiguousarray(centers)
def _init_centroids(X, k, init, random_state=None, x_squared_norms=None,
init_size=None):
"""Compute the initial centroids
init : {'k-means++', 'random' or ndarray or callable} optional Method for initialization
if isinstance(init, string_types) and init == 'k-means++':
centers = _k_init(X, k, random_state=random_state,
x_squared_norms=x_squared_norms)
elif isinstance(init, string_types) and init == 'random':
seeds = random_state.permutation(n_samples)[:k]
centers = X[seeds]
elif hasattr(init, '__array__'): #如果init是数组,则用此数组初始化质心
# ensure that the centers have the same dtype as X
# this is a requirement of fused types of cython
centers = np.array(init, dtype=X.dtype)
elif callable(init): #如果init是可调用的函数,可直接调用该函数去生成初始化质心。
centers = init(X, k, random_state=random_state)
centers = np.asarray(centers, dtype=X.dtype)
else:
raise ValueError("the init parameter for the k-means should "
"be 'k-means++' or 'random' or an ndarray, "
"'%s' (type '%s') was passed." % (init, type(init)))
下面的转载自《用Python开始机器学习(10:聚类算法之K均值)》博客的一个例子
1、K均值聚类
K-Means算法思想简单,效果却很好,是最有名的聚类算法。聚类算法的步骤如下:
1:初始化K个样本作为初始聚类中心;
2:计算每个样本点到K个中心的距离,选择最近的中心作为其分类,直到所有样本点分类完毕;
3:分别计算K个类中所有样本的质心,作为新的中心点,完成一轮迭代。
通常的迭代结束条件为新的质心与之前的质心偏移值小于一个给定阈值。
下面给一个简单的例子来加深理解。如下图有4个样本点,坐标分别为A(-1,-1),B(1,-1),C(-1,1),D(1,1)。现在要将他们聚成2类,指定A、B作为初始聚类中心(聚类中心A0, B0),指定阈值0.1。K-Means迭代过程如下:
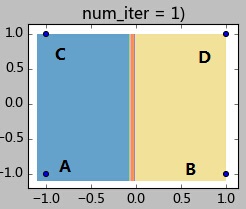
step 1.1:计算各样本距离聚类中心的距离:
样本A:d(A,A0) = 0; d(A,B0) = 2;因此样本A属于A0所在类;
样本B:d(B,A0) = 2; d(B,B0) = 0;因此样本B属于B0所在类;
样本C:d(C,A0) = 2; d(C,B0) = 2.8;;因此样本C属于A0所在类;
样本C:d(D,A0) = 2.8; d(D,B0) = 2;;因此样本C属于B0所在类;
step 1.2:全部样本分类完毕,现在计算A0类(包含样本AC)和B0类(包含样本BD)的新的聚类中心:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









