






下面的全部内容均来自阿里云实时计算文档,把个人认为比较重要的点记录下来方便自己使用!
什么是阿里云实时计算
阿里云实时计算是一套基于Apache Flink构建的大数据处理平台
计算集群是承载实时计算产品计算任务的分布式集群系统,基于YARN模式。
在实时计算中,作业的实时计算单元为CU。1 CU描述了1个实时计算作业最小运行能力,即在限定的CPU、内存、I/O情况下对于事件流处理的最小能力。1个实时计算作业可以指定在1个或者多个CU上运行。
当前对实时计算单元(CU)运行能力的定义:1 CU=1 CPU + 4G MEM。其处理能力约为:
- 对于简单业务,比如单流过滤、字符串变换等操作,1 CU每秒可以处理10000条数据。
- 对于复杂业务,比如
join、窗口、group by等操作,1 CU每秒可以处理1000到5000条数据
业务流程
针对每条DataHub流式数据,实时计算将根据流式数据的主键和RDS中数据进行关联查询(即 join查询)。
阿里云实时计算将计算的结果数据直接写入目的数据存储
DTS(数据传输)支持以数据库为核心的结构化存储产品之间的数据传输。DTS是一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。使用DTS的数据传输功能,可以方便您将RDS等BinLog解析并投递到DataHub,并利用实时计算和MaxCompute进行数据加工计算。
从技术领域来看,实时计算主要用于以下场景:
- 实时ETL&数据流
实时ETL&数据流的目的是实时的把数据从A点投递到B点。中间可能会加上一些数据清洗和集成的工作,比如实时构建搜索系统的索引,实时数仓中的ETL过程等。
-
实时数据分析
数据分析指的是根据业务目标从原始数据中抽取对应信息并整合的过程。比如查看每天卖的最好的十种商品,仓库平均周转时间,文章平均点击率,推送打开率等等。实时数据分析则是上述过程的实时化,一般最终体现为实时报表或实时大屏。
计量计费
实时计算的基本计量单位为Compute Unit(CU),即计算资源,1CU=1核CPU+4G内存。CU对应于实时计算底层系统的CPU计算能力。
一个实时计算Job的CU使用量取决于此job输入数据流的QPS、计算复杂程度,甚至与具体的输入数据分布情况有关,实时计算1CU的处理能力可以通过如下方式大致估算:
- 对于简单业务,比如单流过滤、字符串变换等操作,1CU每秒可以处理10000条数据。
- 对于复杂业务,比如join、窗口、group by等操作,1CU每秒可以处理1000到5000条数据。
- 上述计算能力估值仅限于实时计算内部处理能力,不包括对外数据读取和写入部分。例如,实时计算需要从LogService读取数据,但LogService对于请求调用Quota存在一定限制。此时,实时计算整体的计算能力将被限制在LogService允许的范围内。同样,如果写入RDS存在连接数或者TPS限制,实时计算吞吐能力将受限于RDS本身的流控限制。
- 若作业中使用窗口函数,CU的使用量会比简单作业高,建议至少购买4CU。
如何购买
说明 独享模式blink集群仅能访问同一vpc、同一region、同一安全组下的上下游存储资源,若需访问其他vpc下的资源,请通过高速通道等方式打通网络。
为了保护您的数据安全,独享集群中您上传的UDF包,都会被保存到您的OSS bucket中。请选择已有OSS bucket,如果没有OSS bucket,请创建对象存储OSS。
独享模式集群配置
您购买独享模式相当于购买了一个完全属于您自己的主从分布式集群。整个集群由Master和Slave两部分构成。
- Master负责管理整个集群的资源和Slave之间的交互,但不能用于计算。
- Slave是真正意义上用来计算的计算节点,但由于需要机器间通信以及操作系统本身的对资源的消耗,所以并不是一台Slave的所有资源都能用来计算。
步骤二:准备上下游数据存储
上下游数据存储的准备工作不在实时计算产品上操作,而是在对应的上下游数据存储产品上操作
说明 DataHub和实时计算字段类型对应关系如下,建议使用该对应关系时进行DDL声明。
| DataHub字段类型 | 实时计算字段类型 |
|---|---|
| bigint | bigint |
| string | varchar |
| double | double |
| timestamp | bigint |
| boolean | boolean |
| decimal | decimal |
步骤三:数据开发,作业上线
实时计算产品引入上下游数据有两种方式:明文方式和存储注册方式
数据存储概述
数据存储有两层含义,一方面代表的是实时计算产品上下游生态对应的数据存储系统/数据库表(以下简称存储资源,具体见产品生态),另一方面代表实时计算产品对上下游存储资源的管理功能(以下简称数据存储功能)。实时计算产品使用上下游存储资源有两种方式,第一种我们称之为明文方式,第二种我们称之为存储注册方式
说明 实时计算数据存储功能当前仅支持同账号属主下的存储资源,即当前使用实时计算的A用户(包括A用户的子账户)所注册的存储资源,必须是A购买的存储资源。不支持跨账号授权,对于跨账号授权使用存储资源,请使用明文方式。
开发
对作业进行保存操作也可以触发SQL语法检查功能。
说明 版本数低于或等于版本上限数后可再次提交作业。
锁定:锁定当前作业版本,解锁前无法提交新版本。
上线
点击上线 。作业上线后只是将作业提交至集群,并没有启动作业。启动作业请参见
启动
说明 启动位点表示从source表中读取数据的时间点,若选择当前时间则表示从当前时间开始读取数据;若选择过去的某个时间点,则表示从过去时间点开始读取数据,一般用于回追历史数据。
本地调试
与生产环境完全隔离
调试环境下,所有的Flink SQL将在独立的调试容器运行,且所有的输出将被直接改写到调试结果屏幕。不会对线上的生产流、实时计算作业和线上生产的数据存储系统造成任何影响。 数据调试结果实际上不会真正写入到外部数据存储,而是被实时计算拦截输出到屏幕。因此,在实时计算调试完成的代码是在调试容器中完成。
说明 线上运行过程中可能由于对目标数据存储写入格式的不同导致运行失败。这类错误在调试阶段无法完全规避,在线上运行时才能发现。例如,您将结果数据输出到RDS系统。其中某些字段输出字符串数据长度大于RDS建表最大值,在Debug环境下我们无法测试出该类问题。但实际生产运行过程中会有引发异常。后续,实时计算将提供针对本地调试运行,支持写出到真实数据存储的功能。
调试数据分隔符
默认情况下,调试文件使用逗号作为分隔符。例如,您构造了如下的测试数据。
在不指定调试分隔符情况下,默认使用了逗号进行分隔。假设您需要使用JSON文件作为字段内容,字段内容已经包含了逗号。此时您需要指定其他字符作为分隔符。
此时您需要设置如下参数(以分隔符|为例)。
debug.input.delimiter = |
线上调试
没太明白
作业状态
作业健康分小于60分就代表当前节点有数据堆积,处理数据的性能不够。需要使用自动配置调优或者手动配置调优来解决。(您可以根据自己的业务需求来进行调优。)
为了更高效地分布式执行,Realtime Compute底层会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。 operator代表的是每个计算逻辑的算子,而task代表是多个operator的集合。
JobManager
JobManager是实时计算集群的启动过程不可或缺的一部分。实时计算集群的启动流程如下。
- 实时计算集群启动一个JobManger和一个或多个的TaskManager。
- Client提交任务给JobManager。
- JobManager调度任务给各个TaskManager。
- TaskManager将心跳和统计信息汇报给JobManager。
JobManager的用途
JobManager主要负责调度Job并协调Task做Checkpoint,职责上很像Storm的Nimbus。从Client处接收到Job和JAR包等资源后,会生成优化后的执行计划,并以Task为单元调度到各个TaskManager去执行。
TaskExecutor
TaskManager在启动的时候就设置好了槽位数(Slot),每个Slot能启动一个Task线程。从JobManager处接收需要部署的Task,部署启动后,与上游建立Netty连接,接收数据并处理。
高性能Flink SQL优化技巧
Group Aggregate优化技巧
- 开启MicroBatch/MiniBatch (提升吞吐)
MicroBatch和MiniBatch都是微批处理,只是微批的触发机制上略有不同。原理上都是缓存一定的数据后再触发处理,以减少对state的访问从而提升吞吐和减少数据的输出量。
MiniBatch主要依靠在每个task上注册的timer线程来触发微批,需要消耗一定的线程调度性能。MicroBatch是MiniBatch的升级版,主要基于事件消息来触发微批,事件消息会按您指定的时间间隔在源头插入。MicroBatch在攒批效率、反压表现、吞吐和延迟性能上都要优于胜于MiniBatch。
- 适用场景微批处理是增加延迟来换取高吞吐的策略,如果您有超低延迟的要求的话,不建议开启微批处理。一般对于聚合的场景,微批处理可以显著的提升系统性能,建议开启。
说明 MicroBatch模式也能解决之前一直困扰您的两级Agg数据抖动问题。
- 适用场景微批处理是增加延迟来换取高吞吐的策略,如果您有超低延迟的要求的话,不建议开启微批处理。一般对于聚合的场景,微批处理可以显著的提升系统性能,建议开启。
开启方式
MicroBatch/MiniBatch默认关闭,开启方式:
# 攒批的间隔时间,使用microbatch策略时需要加上该配置,且建议和blink.miniBatch.allowLatencyMs保持一致
blink.microBatch.allowLatencyMs=5000
# 使用microbatch时需要保留以下两个minibatch 配置
blink.miniBatch.allowLatencyMs=5000
# 防止OOM设置每个批次最多缓存数据的条数
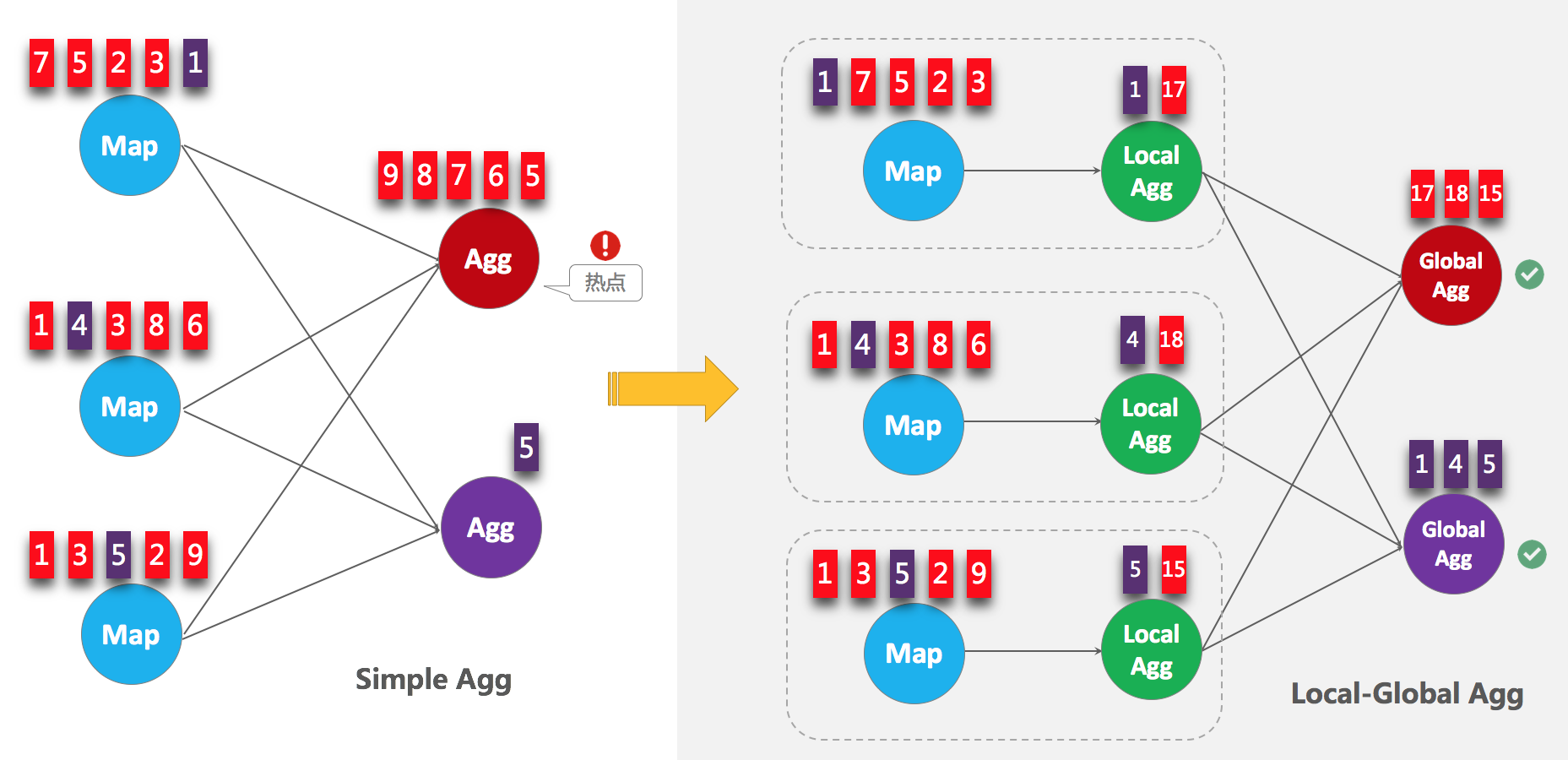
blink.miniBatch.size=20000开启LocalGlobal(解决常见数据热点问题)
LocalGlobal优化即将原先的Aggregate分成Local+Global 两阶段聚合,也就是在MapReduce模型中熟知的Combine+Reduce 处理模式。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator),第二阶段再将收到的Accumulator merge起来,得到最终的结果(globalAgg)。
LocalGlobal本质上能够靠localAgg的聚合筛除部分倾斜数据,从而降低globalAgg的热点,从而提升性能。LocalGlobal如何解决数据倾斜问题可以结合下图理解。
-
适用场景
LocalGlobal适用于提升如sum、count、max、min和avg等普通agg上的性能,以及解决这些场景下的数据热点问题。说明 开启LocalGlobal需要UDAF实现merge方法。
-
开启方式
在 实时计算2.0版本开始,LocalGlobal是默认开启的,参数是:blink.localAgg.enabled=true,但是需要在microbatch/minibatch开启的前提下才能生效。 -
如何判断是否生效
观察最终生成的拓扑图的节点名字中是否包含GlobalGroupAggregate或LocalGroupAggregate
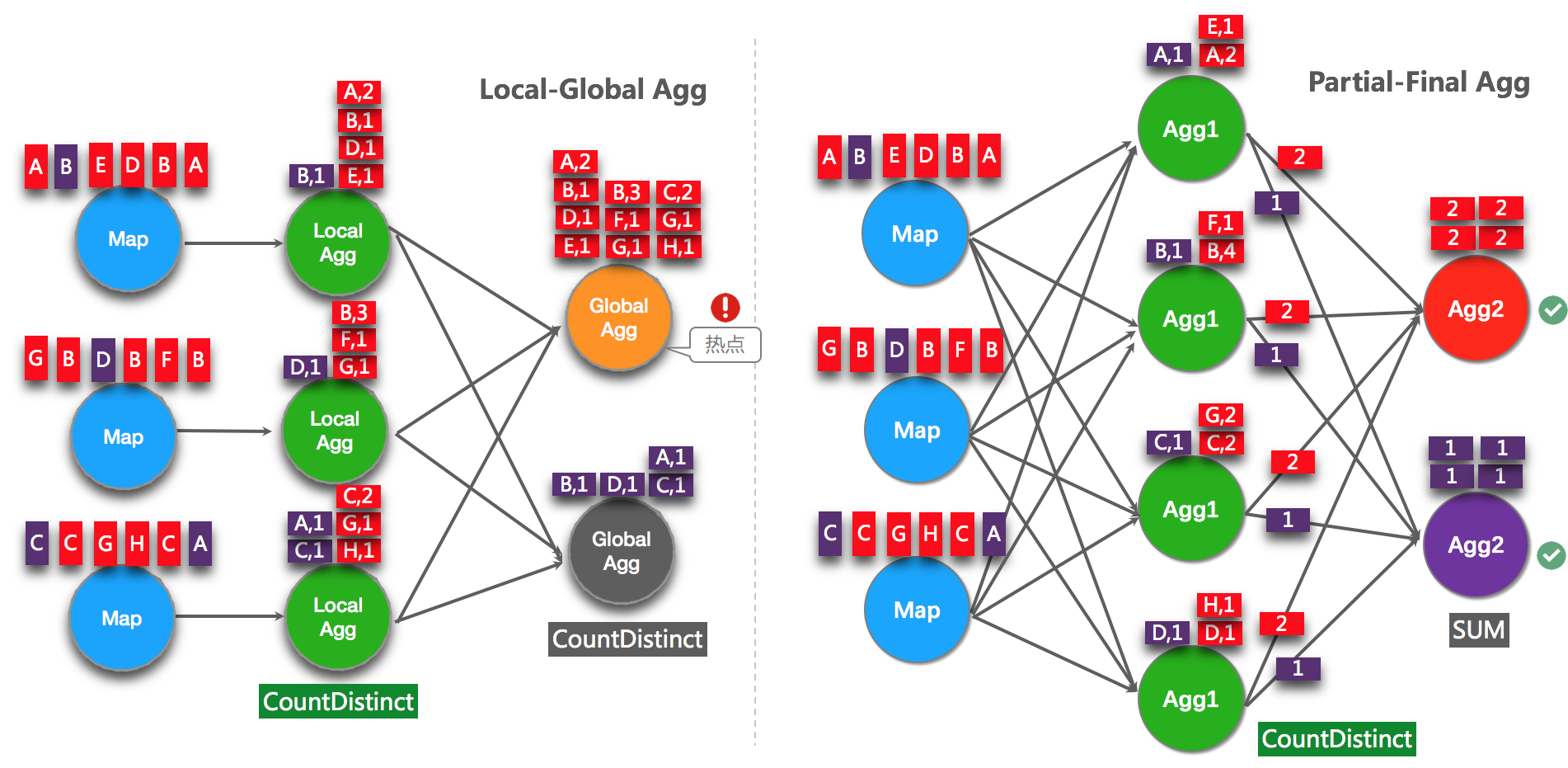
开启PartialFinal(解决count_distinct热点)
上述的LocalGlobal优化能针对常见普通agg有较好的效果(如sum、count、max、min和avg)。但是对于count distinct收效不明显,原因是count distinct在local聚合时,对于distinct key的去重率不高,导致在global节点仍然存在热点。
在旧版本用户为了解决count distinct的热点问题时,一般会手动改写成两层聚合(增加按distinct key 取模的打散层),自2.2.0版本开始,实时计算提供了count distinct自动打散,我们称之为PartialFinal优化,您无需自己改写成两层聚合。PartialFinal和LocalGlobal的原理对比请参见下图。
- 说明
- PartialFinal优化方法不能在包含UDAF的Flink SQL中使用。
- 数据量不大的情况下不建议使用PartialFinal优化方法。PartialFinal优化会自动打散成两层聚合,引入额外的网络shuffle,在数据量不大的情况下,可能反而会浪费资源。
-
-
开启方式
默认不开启,使用参数显式开启blink.partialAgg.enabled=true -
如何判断是否生效
观察最终生成的拓扑图的节点名中是否包含Expand节点,或者原来一层的aggregate变成了两层的aggregate。
-
- 改写成 agg with filter 语法(提升大量count distinct场景性能)
说明 仅支持实时计算 2.2.2 及以上版本。
统计作业需要计算各种维度的UV,比如全网UV、来自手淘的UV、来自PC的UV等等。建议使用更标准的agg with filter语法来代替case when实现多维度统计的功能。实时计算目前的SQL优化器能分析出filter 参数,从而同一个字段上计算不同条件下的count distinct能共享state,减少对state的读写操作。性能测试中,使用agg with filter语法来代替case when能够能够使性能提高1倍。
-
适用场景
我建议用户将agg with case when的语法都替换成agg with filter的语法,尤其是对同一个字段上计算不同条件下的count distinct结果时有极大的性能提升。 - 原始写法
COUNT(distinct visitor_id)as UV1,COUNT(distinctcasewhen is_wireless='y'then visitor_id elsenullend)as UV2 - 优化写法
COUNT(distinct visitor_id)as UV1,COUNT(distinct visitor_id) filter (where is_wireless='y')as UV2
TopN优化技巧(后面再看)
高效去重方案
使用FirstRow语法替换 first_value 函数
FirstRow的作用是去重,且只保留该主键下第一条出现的数据,之后出现的数据会被丢弃掉。因为其state中只存储了key数据,所以替换first_value函数后一般能有一倍的性能提升。
- 原始写法(使用first_value去重):
select biz_order_id, first_value(seller_id), first_value(buyer_id), first_value(total_fee)from tt_source groupby biz_order_id; - 优化写法(使用FirstRow语法): 需要给源表增加PRIMARY KEY属性,并加上
fetchFirstRow='true'的配置。CREATETABLE tt_source ( biz_order_id varchar, seller_id varchar, buyer_id varchar, total_fee doublePRIMARYKEY(biz_order_id # 1. 声明主键,可以是联合主键,即根据什么主键去重 )WITH( type='tt',fetchFirstRow='true' # 2. 声明成只保留首行,默认为false,即保留末行...)
高效的内置函数
-
使用内置函数替换自定义函数
请尽量使用内置函数。在老版本时,由于内置函数不齐全,很多用户都用的三方包的自定义函数。在实时计算2.x 中,我们对内置函数做了很多的优化(主要是节省了序列化/反序列化、以及直接对 bytes 进行操作),但是自定义函数无法享受到这些优化。 -
KEY VALUE 函数使用单字符的分隔符
KEY VALUE 的签名是:KEYVALUE(content, keyValueSplit, keySplit, keyName),当keyValueSplit和KeySplit是单字符时,如:、,会使用优化的算法,会在二进制数据上直接寻找所需的keyName 的值,而不会将整个content做切分。性能约有30%提升。 - 多KEYVALUE场景使用MULTI_KEYVALUE
说明 仅支持实时计算-
如果在query中有对同一个content 做大量KEYVALUE 的操作,比如content中包含10个key-value对,希望把10个value 的值都取出来作为字段。用户经常会写10个KEY VALUE函数,那么就会对content 做10次解析。在这种场景建议使用 MULTI_KEYVALUE,这是一个表值函数。使用该函数可以只对content 做一次 split 解析。性能约有 50%~100%的性能提升。2.2.2及以上版本 - LIKE 操作注意事项
- 如果想做startWith的操作,用
LIKE 'xxx%'。 - 如果想做endWith的操作,用
LIKE '%xxx'。 - 如果想做contains的操作,用
LIKE '%xxx%'。 - 如果是做equals操作,用
LIKE 'xxx',其实和str = 'xxx'等价。 - 如果想匹配
_字符,请注意要做转义LIKE '%seller/id%' ESCAPE '/'。因为_在 SQL 中是个单字符的通配符,能匹配上任何字符,如果声明成LIKE '%seller_id%',那么 不单单会匹配seller_id还会匹配seller#id,sellerxid,seller1id等等,可能会导致结果不是预期的,而且在运行时会使用正则来匹配,效率就会特别慢。
- 如果想做startWith的操作,用
-
慎用正则函数(REGEXP)
正则表达式是非常耗时的操作,对比加减乘除通常有百倍的性能开销,而且正则表达式在某些极端情况下可能会进入无限循环,导致作业卡住。建议使用LIKE。正则函数包括:REGEXP, REGEXP_EXTRACT, REGEXP_REPLACE。
网络传输的优化
综上所述,作业建议使用如下的推荐配置:
# excatly-once语义
blink.checkpoint.mode=EXACTLY_ONCE
# checkpoint间隔时间,单位毫秒
blink.checkpoint.interval.ms=180000
blink.checkpoint.timeout.ms=600000
# 2.x使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=129600000
# 2.x开启5秒的microbatch(使用窗口函数不能设置该参数)
blink.microBatch.allowLatencyMs=5000
# 表示整个job允许的延迟
blink.miniBatch.allowLatencyMs=5000
# 单个batch的size
blink.miniBatch.size=20000
# local 优化,2.x默认已经开启,1.6.4需手动开启
blink.localAgg.enabled=true
# 2.x开启partial优化,解决count distinct热点
blink.partialAgg.enabled=true
# union all 优化
blink.forbid.unionall.as.breakpoint.in.subsection.optimization=true
# object reuse 优化,默认已开启
#blink.object.reuse=true
# GC 优化(SLS做源表不能设置该参数)
blink.job.option=-yD heartbeat.timeout=180000 -yD env.java.opts='-verbose:gc -XX:NewRatio=3 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:ParallelGCThreads=4'
# 时区设置
blink.job.timeZone=Asia/Shanghai注意GC优化那里,日志服务做源表不能设置该参数
AutoConf自动配置调优
- 智能配置:指定使用CU AutoConf算法会基于系统默认配置,生成CU数,进行优化资源配置。如果是第一次运行,算法会根据经验值生成一份初始配置。建议作业运行了5-10分钟以上,确认Source RPS等Metrics稳定2-3分钟后,再使用智能配置,重复3到5次才能调优出最佳的配置。
- 使用上次资源配置:即使用最近一次保存的资源配置。如果上一次是智能配置的,就使用上一次智能配置的结果。如果上一次是手工配置的,就使用上次手工配置的结果。
关键字
| 常用类型 | 关键字 |
|---|---|
| 数据类型 | VARCHAR、INT、BIGINT、DOUBLE 、DATE 、BOOLEAN 、TINYINT、 SMALLINT 、FLOAT 、DECIMAL、VARBINARY |
| DDL | CREATE TABLE、CREATE FUNCTION 、CREATE VIEW |
| DML | INSERT INTO |
| SELECT 子句 | SELECT FROM、WHERE、GROUP BY 、JOIN |
保留关键字
以下字符串组合已经被保留为关键字,以备将来使用。如果您想使用以下字符串作为字段名称,请在关键字两端添加`,例如`value`。
时区
时区简介
在实时计算平台的作业参数中,您可配置Job的时区(如:blink.job.timeZone=America/New_York),默认配置为东八区。时区配置格式Asia/Shanghai、America/New_York或UTC等,详细列表见文章最后。
您可以单独对于Source/Sink表配置时区。例如,您要读/写MySQL,但MySQL的Time/Date/Timestamp列的数据是用 America/New_York(美国时区),而Job计算需要的时区是 Asia/Shanghai(中国时区),则可以如下单独配置source/Sink的时区。
CREATE TABLE mysql_source_my_table (
-- ...
) WITH (
timeZone='America/New_York'
-- ...
)在实时计算引擎 1.6及以上版本中,时区相关函数语义上都是自定义的时区。下面以自定义时区是 Asia/Shanghai为例进行说明。
- 字符串转时间类型(to_timestamp、timestamp和unix_timestamp)
-- Scalar function TO_TIMESTAMP("2018-03-14 19:01:02.123") -- SQL Literal TIMESTAMP '2018-03-14 19:01:02.123' -- 输出: -- 实时计算引擎1.6.0及以上版本: `1521025262123`。 -- 实时计算引擎1.5.x 版本: `1520996462123`。 -- 类似的还有 UNIX_TIMESTAMP,区别是单位为秒。 - 时间类型转字符串(from_timestamp和data_format)
说明 当参数为timestamp时,输出结果取决于自定义设定的时区。
Date/Time 类型
对于Date/Time类型,SQL内部用整数来表示和计算。Date指的是epoch days,Time指的是用户时区的当天的零点开始的毫秒数。如果UDF里对Date、Time进行计算,需要注意的是,从内部类型转换到java.sql.Date、java.sql.Time类型时,java对象里已经加上时区偏移。
时间属性
- Event Time:您提供的事件时间(通常是数据的最原始的创建时间),Event time必须是您提供在Schema里的数据。
- Processing Time:系统对事件进行处理的本地系统时间。

Ingestion Time和Processing Time是系统为流式记录增加的时间属性,您并不能控制。Event Time则是流记录本身携带的时间属性。由于数据本身存在乱序以及网络抖动等其它原因,Event Time为t1(对应partition1)时刻的纪录,有可能会晚于t2(对应prtition2)时刻的被Flink处理,即t2 > t1。
EventTime也称为rowtime。EventTime时间属性必须在源表DDL中声明,可以将源表中的某一字段声明成 EventTime。目前只支持将TIMESTAMP类型(将来会支持 LONG 类型)声明成rowtime字段。如果不是TIMESTAMP类型,需要借助计算列,基于现有列构造出一个TIMESTAMP类型的列。
但由于数据本身会有乱序,加之网络抖动或其它原因,数据到达的顺序和被处理的顺序可能是不一致的(乱序)。因此定义一个rowtime字段,需要显示地定义一个Watermark计算方法。
计算列
计算列可以使用其它列的数据,计算出其所属列的数值。如果您的数据源表中没有TIMESTAMP类型的列,可以使用计算列方法从其它类型的字段进行转换。
计算列概念
计算列是虚拟列,并非实际存储在表中。计算列可以通过表达式、内置函数、或是自定义函数等方式,使用其它列的数据,计算出其所属列的数值。计算列在Flink SQL中可以像普通字段一样被使用。
计算列的用途
目前watermark的Event Time(也称为rowtime)列只支持TIMESTAMP类型(未来会支持LONG类型)。watermark只能定义在源表DDL中,如果您的源表中没有TIMESTAMP类型的列,可以使用计算列从其他类型的字段进行转换。
计算列语法
column_name AS computed_column_expression
计算列示例
watermark的rowtime必须是TIMESTAMP数据类型。当前实时计算支持毫秒级别的、在Unix时间戳里是13位TIMESTAMP数据类型。如果DataHub的TIME字段是微秒级别的(16位Unix时间戳),可以用计算列方法转换为13位的时间戳,如下所示。
CREATE TABLE test_stream(
a INT,
b BIGINT,
`TIME` BIGINT,
ts AS TO_TIMESTAMP(TIME/1000), --利用计算列,将16位时间戳转换为13位时间戳。
WATERMARK FOR ts AS WITHOFFSET(ts, 1000)
) WITH (
type = 'datahub',
...
);
如上示例中所示,源表数据中的字段TIME包含时间信息,为BIGINT类型。用计算列的功能将字段TIME转换成了TIMESTAMP类型的ts字段,并将ts字段作为watermark的rowtime字段。
时间属性再重新看看
Watermark
实时计算可以基于时间属性对数据进行窗口聚合。基于的Event Time时间属性的窗口函数作业中,数据源表的声明中需要使用watermark方法。
watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性,watermark的定义是数据源表DDL定义的一部分。
watermark再重新看看
数据类型概述
| 数据类型 | 说明 | 值域 |
|---|---|---|
| VARCHAR | 可变长度字符串 | 最大容量为4Mb |
| BOOLEAN | 逻辑值 | 取值为TRUE、FALSE或UNKNOWN。 |
| TINYINT | 微整型,1字节整数。 | -128到127 |
| SMALLINT | 短整型,2字节整数。 | -32768到32767 |
| INT | 整型,4字节整数。 | -2147483648到2147483647 |
| BIGINT | 长整型,8字节整数。 | -9223372036854775808到9223372036854775807 |
| FLOAT | 4字节浮点型 | 6位数字精度 |
| DECIMAL | 小数类型 | 示例:123.45是DECIMAL(5,2)的值。 |
| DOUBLE | 浮点型,8字节浮点型 | 15位十进制精度 |
| DATE | 日期类型 | 示例:DATE'1969-07-20'。 |
| TIME | 时间类型 | 示例:TIME '20:17:40'。 |
| TIMESTAMP | 时间戳,日期和时间 | 示例:TIMESTAMP '1969-07-20 20:17:40'。 |
| VARBINARY | 二进制数据 | byte[] 数组 |
窗口函数概述
窗口函数Flink SQL支持基于无限大窗口的聚合(无需显式定义在SQL Query中添加任何的窗口)以及对一个特定的窗口的聚合。例如,需要统计在过去的1分钟内有多少用户点击了某个的网页,可以通过定义一个窗口来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
Flink SQL支持的窗口聚合主要是两种:Window Aggregate和Over Aggregate。
Window Aggregate支持两种时间属性做窗口:Event Time和Processing Time。每种时间属性类型下,又分别支持三种窗口类型:滚动窗口(TUMBLE)、滑动窗口(HOP)和会话窗口(SESSION)。
cast (var1 as bigint) as AA;
cast (big1 as varchar) as BB;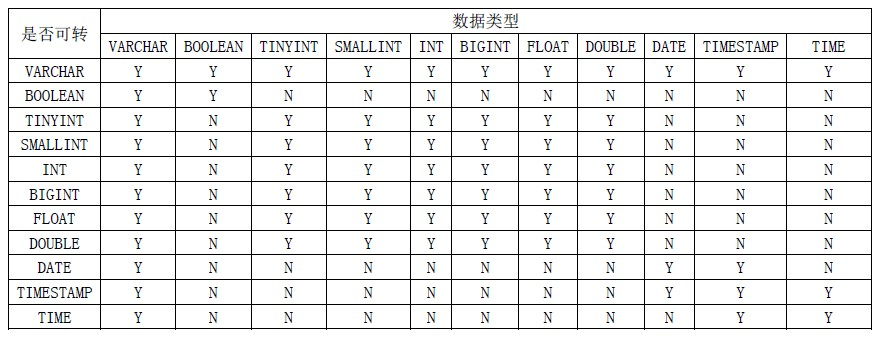
创建数据视图
如果计算的逻辑比较复杂,您可以通过实时计算定义视图的方式创建数据视图,简化开发过程。
数据视图仅用于辅助计算逻辑的描述,不会产生数据的物理存储。
DDL概述
阿里云实时计算本身不带有数据存储功能,所有涉及表创建DDL的操作,实际上均是对于外部数据表、存储的引用声明
- 实时计算声明表的作用域是当前作业(1个SQL文件提交后生成1个实时计算作业),即上述有关
mq_stream的声明仅在当前SQL有效。相同实时计算项目下的不同SQL文件同样可以声明名称为mq_stream的表。 - 按照SQL标准定义,DDL语法中关键字、表名、列名等不区分大小写。
- 表名、列名必须以字母或者数字开头,并且名称中只能包含字母、数字或下划线。
- DDL声明不完全根据名称进行映射(取决于上游插件的性质)。建议您引用声明的字段名称、字段个数和外部表保持一致,避免因定义混乱而导致的数据错乱情况。
说明 对于声明表和外部表,如果插件支持根据key取值,则不要求两者字段数量一致,但字段名称需要一致。如果上游插件不支持根据key取值,则需要字段数量和字段顺序一致。
字段映射
声明表的字段映射根据外部数据源是否有Shema,分为两大类别。
- 顺序映射
适用于以MQ为代表的不带有Schema系统。这类系统通常是非结构化存储系统,不支持根据key取值。建议您在DDL SQL声明中对字段名称进行自定义,并且和外部表的字段类型、字段数量保持一致。
-
名称映射
适用于带有Schema的系统。这类系统在表存储级别定义了字段名称以及字段类型,支持根据key取值。建议您在Flink SQL的声明中保持和外部数据存储Schema定义一致,包括字段名称、字段数量以及字段的顺序。
说明 如果外部数据存储的字段名称是大小写敏感类型(如表格存储),则需要在区分大小写的字段名称处使用反引号
``进行转换。在DDL语法中,声明表的字段名和外部表的字段名需要一致。
处理大小写敏感
SQL标准定义中,大小写是不敏感的。
create table STREAM_RESULT (
`NAME` varchar,
`VALUE` varchar
);数据源表概述
实时计算的数据源表是指流式数据存储。流式数据存储驱动实时计算的运行,因此每个实时计算作业必须提供至少1个流式数据存储。
获取数据源表属性字段
- 获取数据源表属性字段语法
实时计算在源表的DDL语句中提供
HEADER关键字,用于获取源表中的属性字段。
包含窗口函数的数据源表
实时计算可以基于Event Time和Processing Time这2种时间属性对数据进行窗口聚合。包含窗口函数的作业中,数据源表的声明中需要使用到watermark和计算列方法。实时计算基于时间属性的聚合详情
创建日志服务(LogService)源表
https://help.aliyun.com/knowledge_detail/62521.html#concept-62521-zh
创建云数据库(RDS和DRDS)结果表
https://help.aliyun.com/knowledge_detail/62525.html?spm=a2c4g.11186631.2.7.3e3c55c4x6WFoO
实时计算支持使用RDS/DRDS作为结果输出(目前仅支持MySQL数据存储类型)。
说明
- 实时计算写入RDS/DRDS数据库结果表原理:针对实时计算每行结果数据,拼接成一行SQL语句,输入至目标端数据库,进行执行。如果使用批量写,需要在URL后面加上参数
?rewriteBatchedStatements=true,以提高系统性能。 - RDS MySQL数据库支持自增主键。如果需要让实时计算写入数据支持自增主键,在DDL中不声明该自增字段即可。例如,ID是自增字段,实时计算DDL不写出该自增字段,则数据库在一行数据写入过程中会自动填补相关的自增字段。
- 如果DRDS有分区表,拆分键必须在实时计算DDL里
primary key()中声明,否则拆分的表无法写入。关于DRDS分库分表的概念可参见DRDS分库分表。 - 建议使用数据存储注册方式,参见注册云数据库(RDS)。
| RDS字段类型 | 实时计算字段类型 |
|---|---|
| INTEGER | INT |
| FLOAT | FLOAT |
| DECIMAL | DECIAML |
| LONG | BIGINT |
| DOUBLE | DOUBLE |
| TEXT | VARCHAR |
| BYTE | |
| DATE | |
| DATETIME | |
| TIMESTAMP | |
| TIME | |
| YEAR | |
| CHAR |
FAQ
-
Q:实时计算的结果数据写入RDS表,是按主键更新的,还是生成1条新的记录?
A:如果在DDL中定义了主键,会采用
insert into on duplicate key update的方式更新记录,也就意味着对于不存在的主键字段会直接插入,存在的主键字段则更新相应的值。 如果DDL中没有声明primary key,则会用insert into方式插入记录,追加数据。 -
Q:使用RDS表中的唯一索引做group by需要注意什么?
A:- 需要在作业中的primary key中声明这个唯一索引。
- RDS中只有一个自增主键,实时计算作业中不能声明为primary key。
INSERT INTO语句
说明
- 单个实时计算作业支持在一个SQL作业里面包含多个DML操作,同样也允许包含多个数据源、多个数据目标端、多个维表。例如,在一个作业文件里面包含两段完全业务上独立的SQL,分别写出到不同的数据目标端。
- 实时计算不支持单独的SELECT查询,必须有CREATE VIEW或这是在INSERT INTO内才能操作。
- INSERT INTO支持UPDATA更新。例如,向RDS的表插入一个KEY值。如果这个KEY值存在就会更新,如果不存在就会插入一条新的KEY值。
| 源表 | 只能引用(FROM),不可执行INSERT。 |
| 维表 | 只能引用(JOIN),不可执行INSERT。 |
| 结果表 | 仅支持INSERT操作。 |
| 视图 | 只能引用(FROM)。 |
维表JOIN语句
维表是一张不断变化的表,因此在JOIN维表的时候,需指明这条记录关联维表快照的时刻。目前维表JOIN仅支持对当前时刻维表快照的关联。(未来会支持关联左表rowtime所对应的维表快照。)
说明
- 维表支持
INNER JOIN和LEFT JOIN,不支持RIGHT JOIN或FULL JOIN。 - 必须加上
FOR SYSTEM_TIME AS OF PROCTIME(),表示JOIN维表当前时刻所看到的每条数据。 - JOIN行为只发生在处理时间(processing time),即使维表中的数据新增、更新或删除,已关联的数据也不会被改变或撤回。
- ON条件必须包含维表PRIMARY KEY的等值条件(且要求与真实表定义一致),但除此之外,ON条件中也可以有其他等值条件。
- 维表和维表不能做JOIN。
UNION ALL语句
UNION ALL语句将两个流式数据合并。要求两个流式数据的字段完全一致,包括字段类型和字段顺序。
说明 实时计算同样支持 UNION函数。 UNION ALL允许重复值, UNION不允许重复值。在实时计算底层, UNION是 UNION ALL + Distinct ,运行效率较低,一般不推荐使用 UNION。
级联窗口
由于rowtime列在经过窗口后,其event time属性会丢失。您可以使用辅助函数TUMBLE_ROWTIME、HOP_ROWTIME或SESSION_ROWTIME来获取窗口中的rowtime列的最大值max(rowtime)作为时间窗口的rowtime,其类型是具有rowtime attribute的TIMESTAMP,取值为 window\_end - 1 。 例如[00:00, 00:15) 的窗口,返回值为00:14:59.999 。
级联窗口示例如下。示例逻辑为:基于1分钟的滚动窗口聚合结果,进行1小时的滚动窗口聚合。
代码
CREATE TABLE datahub_stream (
a VARCHAR,
b BIGINT,
c TIMESTAMP,
d AS PROCTIME()
) WITH (
TYPE='datahub',
...
);
CREATE TABLE rds_output (
a VARCHAR,
b TIMESTAMP,
cnt BIGINT,
PRIMARY KEY(a)
)WITH(
TYPE = 'rds',
...
);
CREATE VIEW rds_view AS
SELECT a,
CAST(
HOP_START(d, INTERVAL '5' SECOND, INTERVAL '30' SECOND) AS TIMESTAMP
) AS cc,
SUM(b) AS cnt
FROM
datahub_stream
GROUP BY
HOP(d, INTERVAL '5' SECOND, INTERVAL '30' SECOND),a;
INSERT INTO
rds_output
SELECT
a,
cc,
cnt
FROM
rds_view
WHERE
cnt=4
CREATE TABLE sls_log (
__topic__ VARCHAR HEADER,
result VARCHAR
)WITH(
type ='sls'
);
CREATE TABLE sls_out (
name varchar,
MsgID varchar,
Version varchar
)WITH(
type ='RDS'
);
INSERT INTO sls_out
SELECT
__topic__,
JSON_VALUE(result,'$.MsgID'),
JSON_VALUE(result,'$.Version')
FROM
sls_log
create table sls_stream(
a int,
b int,
c VARCHAR
) with (
type ='sls',
endPoint ='yourEndpoint',
accessId ='yourAccessId',
accessKey ='yourAccessKey',
startTime = 'yourStartTime',
project ='yourProjectName',
logStore ='yourLogStoreName',
consumerGroup ='yourConsumerGroupName'
);
CREATE TABLE rds_output(
id INT,
len INT,
content VARCHAR,
PRIMARY KEY (id,len)
) WITH (
type='rds',
url='yourDatabaseURL',
tableName='yourDatabaseTable',
userName='yourDatabaseUserName',
password='yourDatabasePassword'
);
CREATE TABLE datahub_input1 (
id BIGINT,
name VARCHAR,
age BIGINT
) WITH (
type='datahub'
);
create table phoneNumber(
name VARCHAR,
phoneNumber bigint,
primary key(name),
PERIOD FOR SYSTEM_TIME
)with(
type='rds'
);
CREATE table result_infor(
id bigint,
phoneNumber bigint,
name VARCHAR
)with(
type='rds'
);
INSERT INTO result_infor
SELECT
t.id,
w.phoneNumber,
t.name
FROM datahub_input1 as t
JOIN phoneNumber FOR SYSTEM_TIME AS OF PROCTIME() as w
ON t.name = w.name;
CREATE TABLE source_table (
IP VARCHAR,
`TIME` VARCHAR
)WITH(
type='datahub',
endPoint='xxxxxxx',
project='xxxxxxx',
topic='xxxxxxx',
accessId='xxxxxxx',
accessKey='xxxxxxx'
);
CREATE TABLE result_table (
rownum BIGINT,
start_time VARCHAR,
IP VARCHAR,
cc BIGINT,
PRIMARY KEY (start_time, IP)
) WITH (
type = 'rds',
url='xxxxxxx',
tableName='blink_rds_test',
userName='xxxxxxx',
password='xxxxxxx'
);
INSERT INTO result_table
SELECT rownum,start_time,IP,cc
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY start_time ORDER BY cc DESC) AS rownum
FROM (
SELECT SUBSTRING(`TIME`,1,2) AS start_time,--可以根据真实时间取相应的数值,这里取得是测试数据
COUNT(IP) AS cc,
IP
FROM source_table
GROUP BY SUBSTRING(`TIME`,1,2), IP
)a
)
WHERE rownum <= 3 --可以根据真实top值取相应的数值,这里取得是测试数据
级联窗口示例如下。示例逻辑为:基于1分钟的滚动窗口聚合结果,进行1小时的滚动窗口聚合。
CREATE TABLE user_clicks(
username varchar,
click_url varchar,
ts timeStamp,
WATERMARK wk FOR ts as withOffset(ts, 2000) --为rowtime定义watermark
) with (
type='datahub',
...
);
CREATE TABLE tumble_output(
window_start TIMESTAMP,
window_end TIMESTAMP,
username VARCHAR,
clicks BIGINT
) with (
type='print'
);
CREATE VIEW one_minute_window_output as
SELECT
// 使用TUMBLE_ROWTIME作为二级window的聚合时间
TUMBLE_ROWTIME(ts, INTERVAL '1' MINUTE) as rowtime,
username,
COUNT(click_url) as cnt
FROM window_input
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE), username;
INSERT INTO tumble_output
SELECT
TUMBLE_START(rowtime, INTERVAL '1' HOUR),
TUMBLE_END(rowtime, INTERVAL '1' HOUR),
username,
SUM(cnt)
FROM one_minute_window_output
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), username电商场景实战之多类目成交总额管理
CREATE TABLE source_order (
id VARCHAR,-- 商品ID
buyer_id VARCHAR, --买家ID
site VARCHAR,--商品类别
pay_time VARCHAR,--订单支付时间
buy_amount DOUBLE, --订单金额
wap VARCHAR--购买方式
) WITH (
type='datahub',
endPoint='http://dh-cn-hangzhou.aliyun-inc.com',
project='yourProjectName',--DataHub中Poject的名称
topic='yourTopicName',--DataHub Poject中Topic的名称
roleArn='yourRoleArn',--指定角色的roleArn
batchReadSize='500'
);
CREATE TABLE ads_site_block_trd_pay_ri (
id VARCHAR,
site VARCHAR,
data_time VARCHAR,
all_alipay BIGINT,
all_ord_cnt BIGINT,
primary key(id,site,data_time)
) WITH (
type= 'rds',
url = 'yourRDSDatabaseURL',--RDS数据库URL
tableName = 'yourDatabaseTableName',--RDS数据库中的表名
userName = 'yourDatabaseUserName',--登录数据库的的用户名
password = 'yourDatabasePassword'-登录数据库的密码
);
CREATE VIEW tmp_ads_site_block_trd_pay_ri AS
SELECT
id id,
mod(HASH_CODE(`a`.buyer_id),4096) hash_id,
site site,
date_format(`a`.pay_time , 'yyyy-MM-dd HH:mm:ss' , 'yyyyMMddHH') data_time,
SUM(cast(buy_amount as bigint)) all_alipay,
count(distinct `a`.buyer_id) all_ord_cnt
FROM
source_order `a`
GROUP BY id , site , mod(HASH_CODE(`a`.buyer_id),4096) , date_format(`a`.pay_time , 'yyyy-MM-dd HH:mm:ss' , 'yyyyMMddHH') ;
INSERT INTO ads_site_block_trd_pay_ri
SELECT
id,
site,
`a`.data_time,
CAST(sum(all_alipay) AS BIGINT) as all_alipay,
CAST(sum(all_ord_cnt) AS BIGINT) as all_ord_cnt
FROM
tmp_ads_site_block_trd_pay_ri `a`
GROUP BY id , site , `a`.data_time ;
常见问题
Q:怎么解决数据倾斜?
A:假如您的ID数据非常大,根据您的ID进行分组计算可能会造成机器热点从而导致数据倾斜,计算性能会很差。
mod(HASH_CODE(`a`.buyer_id),4096) hash_id
使用HASH_CODE这个离散函数来分离数据热点,接下来使用MOD函数对哈希值进行分组操作。这样做的好处是规范每个节点数据的数量避免大量数据的堆积导致数据倾斜(4096指的是分组的数量,可以根据数据的大小进行分组操作)。HASH_CODE函数详情请参见HASH_CODE。
Q:您得到的UV量是否准确?
A:直接使用count(distinct,buyer_id)会出现计算不准的问题。用GROUP BY mod(HASH_CODE(a.buyer_id),4096),把相同buyer_id过滤去重后,再做SUM就可以避免这样的错误产生。
CREATE VIEW tmp_ads_site_block_trd_pay_ri AS
SELECT
id id,
mod(HASH_CODE(`a`.buyer_id),4096) hash_id,
site site,
date_format(`a`.pay_time , 'yyyy-MM-dd HH:mm:ss' , 'yyyyMMddHH') data_time,
SUM(cast(buy_amount as bigint)) all_qty_cnt,
count(distinct `a`.buyer_id) all_ord_cnt
FROM
source_order `a`
GROUP BY id , site , mod(HASH_CODE(`a`.buyer_id),4096) , date_format(`a`.pay_time , 'yyyy-MM-dd HH:mm:ss' , 'yyyyMMddHH') ;

















 5130
5130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









