







分布式定时任务+重试
为什么需要使用分布式定时任务
在使用分布式定时任务的时候,我们必须要清楚为什么要使用分布式定时任务?用一些单机的定时任务如Spring的定时任务、Timer不行吗?下面我们介绍一下两种定时任务的常见实现以及场景
单机定时任务
常见实现
我们在平常实现单机定时任务有如下几种技术方案:
- Timer ,Java内置提供;
- ScheduledExecutorService ,定时任务线程池,通过提交任务实现定时任务;
- Spring的@Scheduled注解,直接通过注解和Corn表达式即可简单定义定时任务,不过这其实是可以结合数据库改造成分布式定时任务,后续文章会进行专门介绍;
常见场景
- 资源有限:团队规模小,资源受限,需要简化基础设施
- 用户量小:服务用户量较小,单机处理能力足够
- 设计为单实例运行:某些应用本身就设计为单实例运行
- 有状态服务:某些有状态服务难以水平扩展
- 容错要求不高的任务:即使任务重复执行也不会造成数据问题,任务执行偶尔失败不会造成严重后果,即使自动执行失败,也可以通过手动干预恢复
单机定时任务主要适用于架构为单机、对定时任务可靠、容错性要求不高的业务
分布式定时任务
常见实现
1. Quartz集群模式
核心特点:
- 基于数据库实现任务分布式协调
- 强大的cron表达式支持
- 任务持久化和高可用
- 成熟稳定,Java生态标准调度库
实现原理:
- 使用数据库锁机制防止任务重复执行
- 多个节点通过共享数据库表来协调任务
- 节点间通过"争抢"机制决定任务执行权
适用场景:
- 已有Quartz单机应用需要扩展到分布式
- 需要分布式事务支持的场景
- 对任务执行有严格要求的企业级应用
缺点:
- 依赖数据库,性能受限
- 集群规模较大时性能下降明显
2. XXL-Job
核心特点:
- 轻量级分布式任务调度框架
- 简洁易用的管理界面
- 丰富的任务类型(如GLUE模式支持在线编辑代码)
- 国产开源项目,社区活跃度高
实现原理:
- 基于调度中心和执行器分离的架构
- 调度中心统一管理任务,执行器执行任务
- 调度中心通过HTTP与执行器通信
适用场景:
- 中小型应用的分布式任务调度
- 需要可视化管理界面的场景
- 灵活性要求高的业务场景
缺点:
- 功能相比更大型框架稍简单
- 大规模部署经验较少
3. Elastic-Job / ShardingSphere-ElasticJob
官方文档
核心特点:
- 基于Zookeeper的分布式协调
- 支持任务分片,可并行处理大数据量任务
- 丰富的作业类型(简单作业、数据流作业、脚本作业)
- 弹性扩容缩容支持
实现原理:
- 使用Zookeeper实现分布式协调和选主
- 通过分片算法将任务分配给不同节点
- 支持失效转移和错过执行补偿
适用场景:
- 需要处理海量数据的批处理场景
- 要求高可靠性和动态扩展的场景
- 对任务精细化控制要求高的场景
缺点:
- 依赖Zookeeper
- 配置相对复杂
4. ShedLock
核心特点:
- 轻量级分布式锁实现
- 与Spring集成良好
- 支持多种存储(JDBC、Redis、MongoDB等)
- 非侵入式设计
实现原理:
- 通过分布式锁确保任务在集群中只执行一次
- 不是完整的调度框架,仅解决重复执行问题
- 通常与Spring的@Scheduled结合使用
适用场景:
- Spring应用需要简单防止任务重复执行
- 不需要复杂调度功能的场景
- 作为已有单机任务的分布式升级方案
缺点:
- 功能相对简单,不是完整的调度框架
- 没有可视化管理界面
5. SchedulerX (阿里云)
产品链接
核心特点:
- 阿里云提供的企业级分布式调度服务
- 高可靠、高可用、高性能
- 支持秒级调度和多种高级功能
- 提供完善的监控报警机制
实现原理:
- 基于云原生架构设计
- 与阿里云生态深度集成
- 底层由阿里内部使用多年的SchedulerX2.0驱动
适用场景:
- 阿里云用户
- 对可靠性要求极高的企业级应用
- 需要云服务支持的场景
缺点:
- 付费服务
- 与阿里云耦合
6. Spring Cloud Task
官方文档
核心特点:
- Spring Cloud生态组件
- 专注于短期微服务任务
- 与Spring Batch集成良好
- 提供任务执行的记录和追踪
实现原理:
- 基于Spring Cloud架构
- 利用数据库记录任务执行状态
- 与Spring Cloud Stream集成实现事件驱动
适用场景:
- Spring Cloud微服务架构
- 短期任务执行和记录
- 与Spring Batch结合的批处理场景
缺点:
- 不是传统的定时调度框架
- 主要关注点在任务执行而非调度
7. PowerJob (原XxlJob-Plus)
仓库地址
核心特点:
- 基于Actor模型的新一代分布式调度与计算框架
- 支持CRON、API、固定频率等多种调度方式
- 支持工作流、广播、Map/MapReduce等多种执行模式
- 完善的运维监控能力
实现原理:
- 基于去中心化的Actor设计理念
- 支持无限水平扩展
- 采用多级时间轮算法提高调度性能
适用场景:
- 需要高性能的大规模任务调度场景
- 复杂的工作流编排场景
- 需要处理海量任务的大型分布式系统
缺点:
- 相对较新,生产验证案例相对较少
- 学习曲线较陡
7. Snail-Job(简单实用)
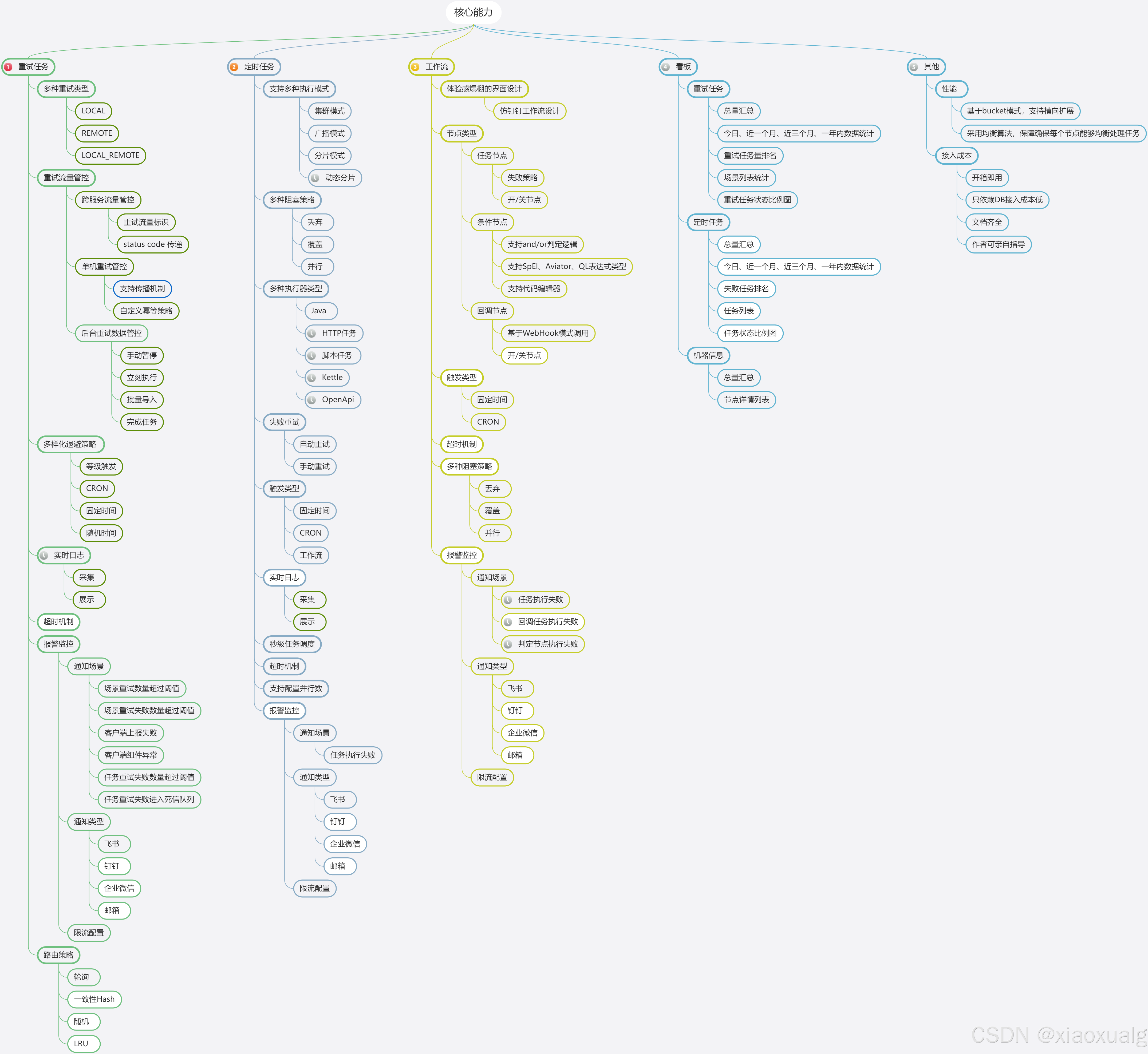
开源分布式任务调度框架对比
| 特性 | Quartz | Elastic-Job | XXL-JOB | PowerJob | Snail Job |
|---|---|---|---|---|---|
| 跨语言能力 | 不支持 | 不支持 | 不支持 | 不支持 | 支持Java(1.8/17)、原生Python客户端、原生Go客户端 |
| 定时调度 | Cron | Cron | Cron | CRON、固定频率、固定延迟、OpenAPI | 1. 定时任务 2. 秒级任务(无需依赖外部中间件) 3. 固定频率 4. OpenAPI |
| 重试任务 | 不支持 | 不支持 | 不支持 | 不支持 | 1. 支持本地&远程重试模式 2. 支持各种常用组件的重试(dubbo/feign等) 3. 支持多种退避策略 4. 丰富的重试风暴管控手段 |
| 任务编排 | 不支持 | 不支持 | 不支持 | 支持 | 仿钉钉工作流设计,颜值高、体验好 |
| 分布式计算 | 不支持 | 静态分片 | 广播 | 支持 | 1. 广播执行 2. 集群执行 3. 静态分片 4. 动态分片 |
| 多语言 | Java | 1. Java 2. 脚本任务 | 1. Java 2. 脚本任务 | 支持 | 1. Java 2. CMD(本地脚本、远程脚本、参数传入) 3. PowerShell(本地脚本、远程脚本、参数传入) 4. Shell(本地脚本、远程脚本、参数传入) 5. HTTP任务 |
| 用户管理 | 不支持 | 支持 | 支持 | 不支持 | 完备的用户管理和权限管理 |
| 安全 Token | 不支持 | 不支持 | 支持 | 不支持 | 支持 |
| 可视化 | 无 | 弱 | 1. 历史记录 2. 运行日志(不支持存储) 3. 监控大盘 | 支持 | 1. 历史记录 2. 实时日志(支持持久化、可视化) 3. 监控大盘(实时调度数据展示) 4. 失败调度排名 5. 在线集群查看等 |
| 可运维 | 无 | 启用、禁用任务 | 1. 启用、禁用任务 2. 手动运行任务 3. 停止任务 | 支持 | 1. 启用、禁用任务 2. 手动运行任务 3. 停止任务 4. 手动重试 |
| 报警监控 | 无 | 邮件 | 邮件 | 邮件 | 支持配置多种告警场景,通知方式支持: 1. 邮件 2. 钉钉 3. 企微 4. 飞书 5. Webhook |
| 性能 | 每次调度通过DB抢锁,对DB压力大 | ZooKeeper是性能瓶颈 | 采用Master节点调度,Master节点压力大 | 无锁化设计 | 系统采用多bucket模式,借助负载均衡算法,确保每个节点能够均衡处理任务,同时支持无限水平扩展,轻松应对海量任务调度 |
| 接入成本 | 只依赖DB接入成本低 | 需引入Zookeeper增加系统复杂性和维护成本 | 只依赖DB接入成本低 | 依赖DB接入成本低 | 只依赖DB接入成本低 |


















 2418
2418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











