






ES 的分布式架构原理
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在
多台机器上启动多个 ES 进程实例,组成了一个 ES 集群。
ES 中存储数据的基本单位是索引,
很多情况下,一个 index 里可能就一个 type,但是确实如果说是一个 index 里有多个 type 的情
况(注意, mapping types 这个概念在 ElasticSearch 7. X 已被完全移除,详细说明可以参考
官方文档),你可以认为 index 是一个类别的表,具体的每个 type 代表了 mysql 中的一个表。
每个 type 有一个 mapping,如果你认为一个 type 是具体的一个表,index 就代表多个 type 同
属于的一个类型,而 mapping 就是这个 type 的表结构定义,你在 mysql 中创建一个表,肯定
是要定义表结构的,里面有哪些字段,每个字段是什么类型。实际上你往 index 里的一个 type
里面写的一条数据,叫做一条 document,一条 document 就代表了 mysql 中某个表里的一行,
每个 document 有多个 field,每个 field 就代表了这个 document 中的一个字段的值。
你搞一个索引,这个索引可以拆分成多个 shard ,每个 shard 存储部分数据。拆分多个 shard
是有好处的,一是支持横向扩展,比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,
若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进
去;二是提高性能,数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器
上并行分布式执行,提高了吞吐量和性能。
接着就是这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard
,负责写入数据,但是还有几个 replica shard 。 primary shard 写入数据之后,会将数
据同步到其他几个 replica shard 上去。
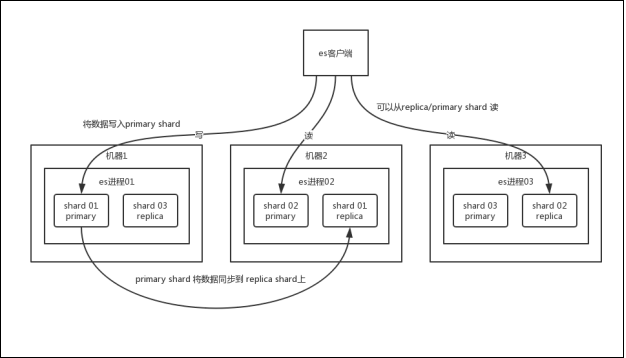
通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,没关系啊,
还有别的数据副本在别的机器上呢。高可用了吧
ES 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理
的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是
master 节点宕机了,那么会重新选举一个节点为 master 节点。
如果是非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身
份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master
节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。
说得更简单一点,就是说如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就
没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary
shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
其实上述就是 ElasticSearch 作为分布式搜索引擎最基本的一个架构设计。
ES 写入数据的工作原理是什么啊?
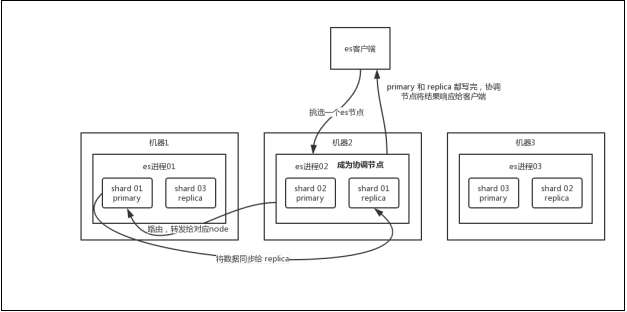
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节
点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary
shard)。
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node 。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就
返回响应结果给客户端
ES 查询数据的工作原理是什么啊?
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了
哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node 。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用
round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,
让读请求负载均衡。接收请求的 node 返回 document 给 coordinate node 。
coordinate node 返回 document 给客户端。
es 搜索数据过程
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊
java好难学啊
j2ee特别牛
你根据 java 关键词来搜索,将包含 java 的 document 给搜索出来。es 就会给你返回:
java真好玩儿啊,java好难学啊。
客户端发送请求到一个 coordinate node 。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,
都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id )返回给协调节点,
由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,
最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary
shard 或 replica shard 读取,采用的是随机轮询算法。
写数据底层原理
总结一下,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache
数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将
数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),
translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush
到 segment file 磁盘文件中。















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









