






 本文介绍南京帆软公司的FineBI如何通过分布式部署解决大数据分析的性能瓶颈,重点讲解了FineBI与Hive的数据连接过程,包括配置HadoopHive的JDBC驱动及测试连接的方法。
本文介绍南京帆软公司的FineBI如何通过分布式部署解决大数据分析的性能瓶颈,重点讲解了FineBI与Hive的数据连接过程,包括配置HadoopHive的JDBC驱动及测试连接的方法。
之前讲过帆软FineReport软件,FineReport的定位是报表,把数据通过报表的方式展示出来,除了FineReport软件,南京帆软公司还推出一款大数据分析和BI的工具FineBI,定位是大数据分析和商业智能,从名字上看这不仅仅是FineReport的增强版,同时还融入很多创新元素。
一、分布式部署
之前用过FineReport的读者可能知道,当数据量大了之后,访问数量指数级增长的情况下,服务器响应会很慢,一言不合就卡机,对数据分析人员来说是难言之隐。南京帆软推出FineBI可能也是基于这个原因,分布式部署,缓解单节点压力。
二、支持大数据存储
FineReport是不支持大数据的数据存储方式的,像HDFS、Hive、AWS、华为云等等都是不支持的,其实支持也没用,单节点的性能瓶颈在那里,数据量和访问量一上来资源就迅速耗尽了,而且是毫无破解之法,现在推出FineBI颇有破解之道,从这个角度来说,南京帆软对用户需求的把握上还是很精准的,难怪活的这么滋润。接来下笔者主要讲下FineBI和Hive连接的案例。
- 启动Hive,我们知道平时我们使用hive都是以cli的方式访问的,现在我们要接入FineBI就需要通过hiveserver2的接口去访问。

- 下载FineBI软件,登录web配置页面,选择“创建”->“新建数据连接”

- 下载并配置Hadoop Hive的JDBC连接驱动;通过上面一个步骤,跳转到Hive驱动配置页面,如下:
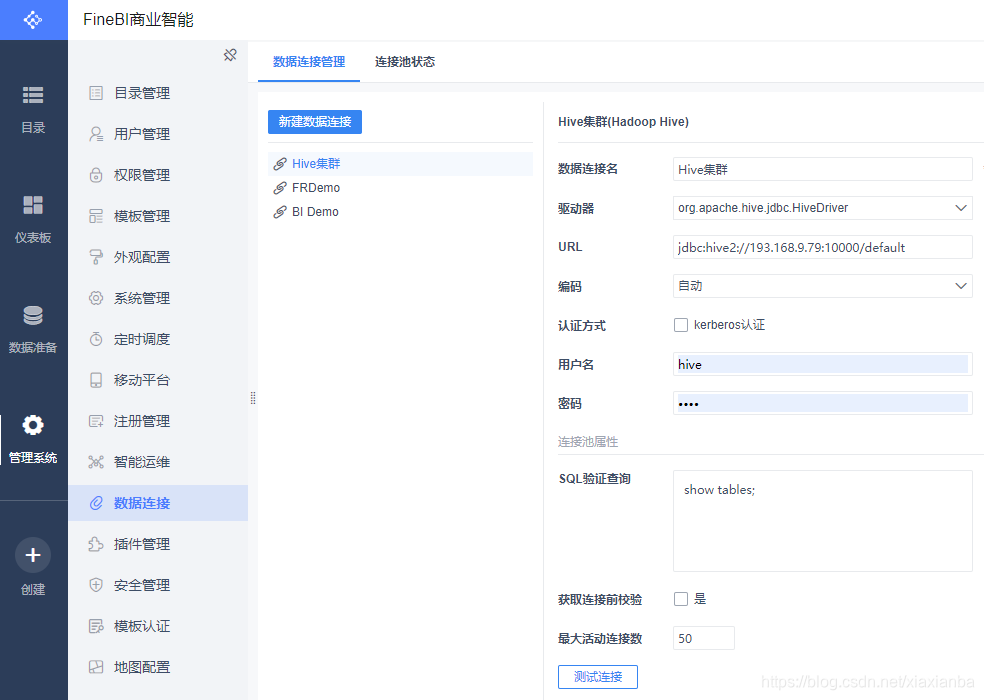
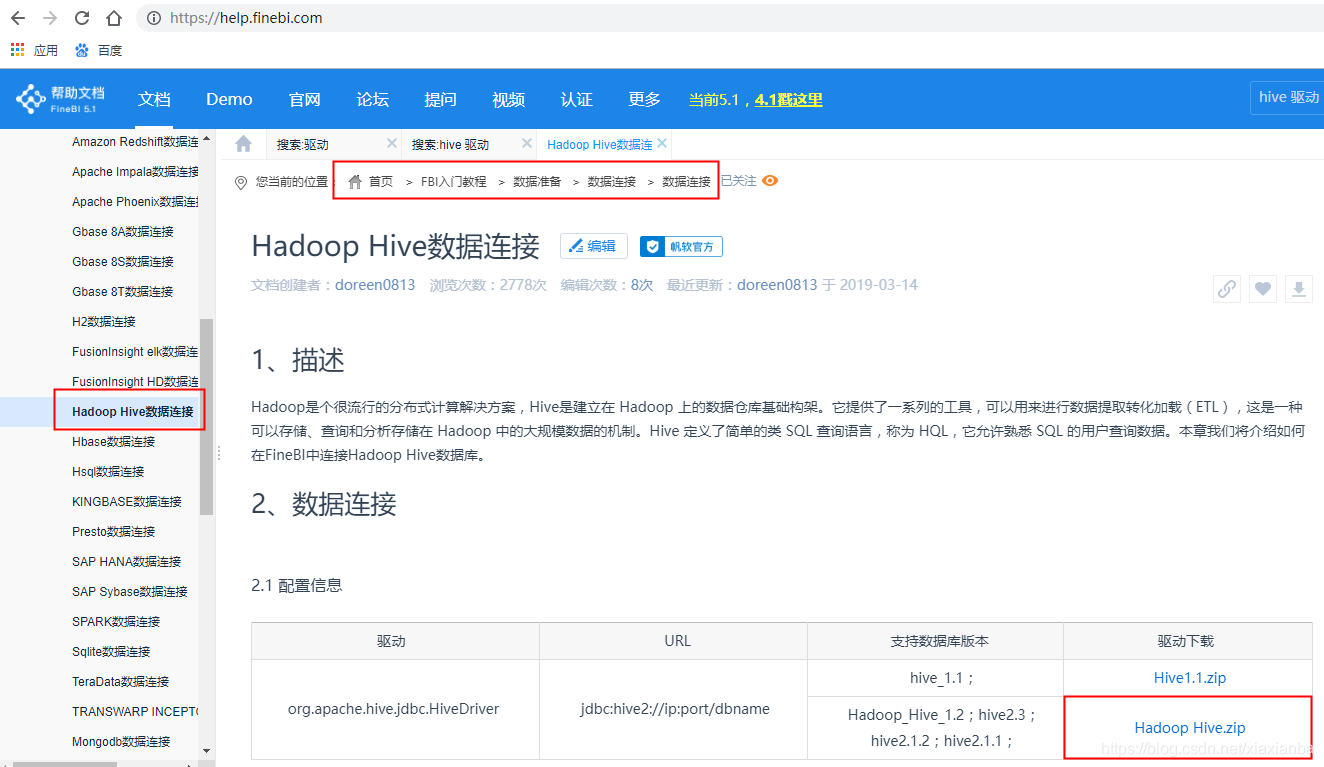
这个时候点击“测试连接”提示的是失败的信息,主要是因为FineBI默认安装没有支持Hive的驱动包,接下来要到官网根据实际的版本下载相应的驱动包,根据数据库的版本下载对应的Hadoop Hive驱动包,并将该驱动包放置到FineBI文件夹%FineBI%\webapps\webroot\WEB-INF\lib下,重启FineBI。
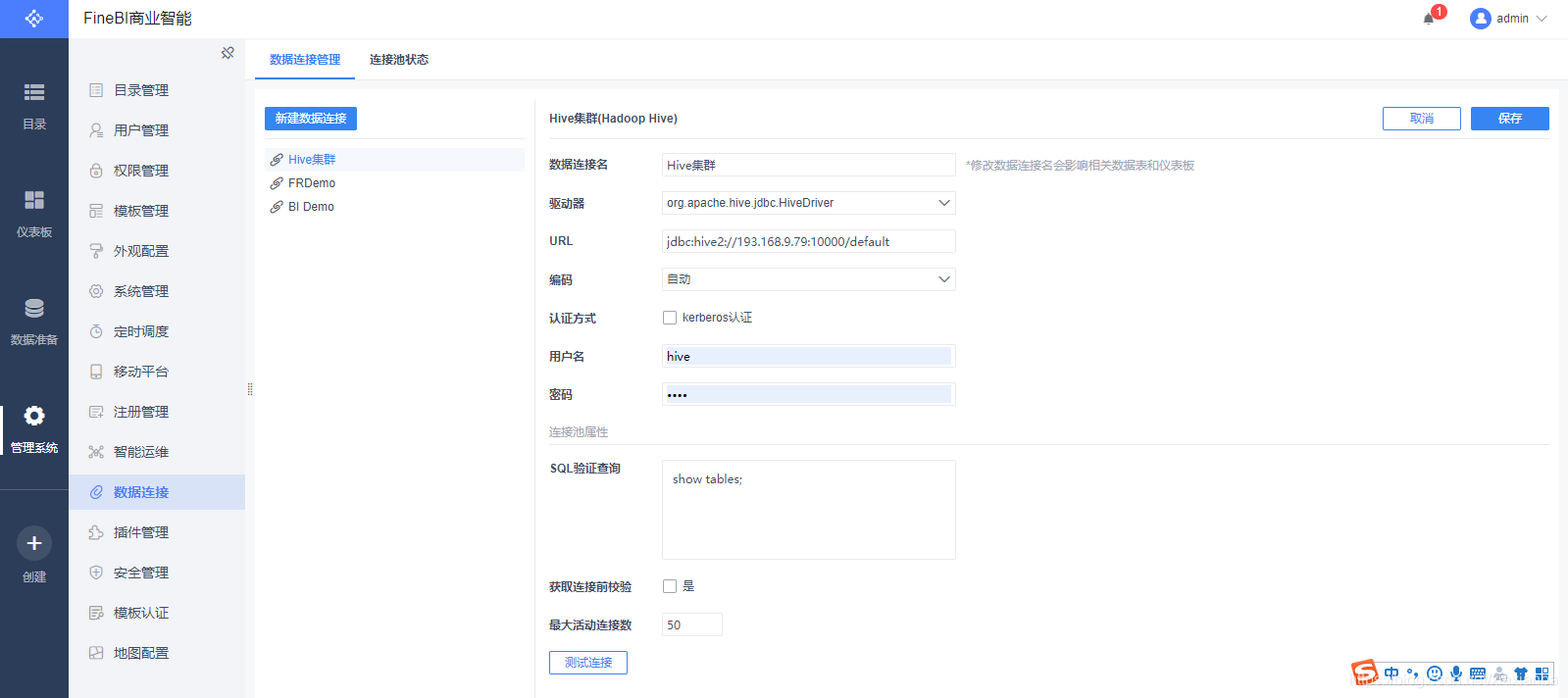
- 测试FineBI与Hadoop Hive连接,驱动放置好之后,Hive默认有个数据库叫default,配置上测试连接是否成功。最终配置的信息如下:
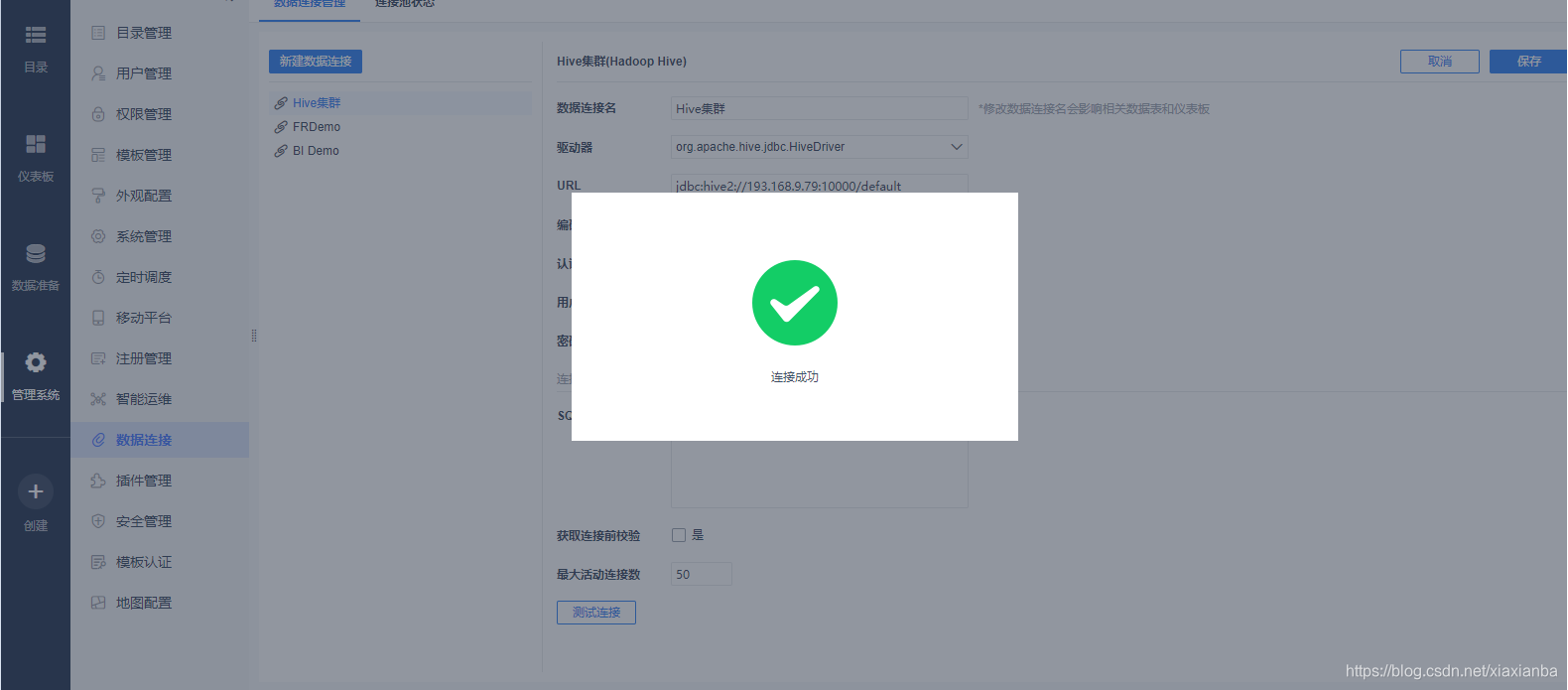
点击“测试连接”,连接成功的提示信息如下:
参考文献
1.FineBI帮助文档


















 3963
3963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











