







单节点的redis并发能力是有限的,如果需要进一步提高redis的并发能力,就需要搭建集群。
Redis中的集群分为三种:
主从复制,哨兵模式,分片集群
先来看一下主从复制:
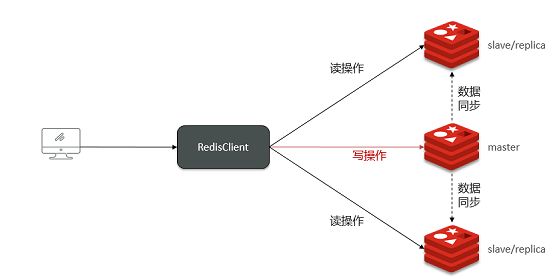
在主从集群中一个主节点可以有多个从节点,一个从节点只能有一个主节点。主节点负责写数据,从节点负责读数据。当数据写入主节点以后会被同步到从节点,从而保证所有节点上的数据一致性。
主节点的数据同步到从节点有两种方式:全量同步和增量同步。
先来看一下全量同步,全量同步分为三个阶段:

第一阶段:建立连接
Slave(从)服务器执行slaveof ip host和master(主)服务器建立连接,其中ip、host 是 master 服务器的 IP 地址和端口号。比如:slaveof 127.0.0.1 6376
第二阶段:数据同步
在 slave 初次连接 master 后,复制 master 中的所有数据到 slave,步骤如下:
1.slave 发送 psync 指令到 master 请求同步数据(psync ? -1)。psync 指令包含两个参数,完整的格式为 psync {replid} {offset},其中 replid为replid,offset 为复制的偏移量,因为现在是首次复制,所以 replid并不知道,设为『?』,offset设置为 -1。
2.master判断是否是第一次同步,判断方法为比较自己的replid和从服务器发送过来的replid看看是否一致,如果不一致则是第一次同步,主服务器会 将自己的 replid发送给从服务器(FULLRESYNC {replid} {offset}),从服务器收到后会记录 replid和 offset。
3 master 执行 bgsave 生成 RDB 文件,并通过 socket 发送给 slave,同时将 bgsave 之后的命令写进repl_baklog日志文件。
4 slave 接收 RDB 文件后,清空本地数据,并加载 RDB 文件,加载完毕之后,向 slave 请求部分同步数据。
5 master 将repl_baklog日志文件的信息发送给 slave。
6 slave 接收到信息后,执行这些命令,恢复数据。
这里的Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid。
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
再来看一下增量同步:
slave节点重启或者后期数据发生变化的时候可以使用增量同步.
增量同步的步骤如下:
1.当slave节点重启以后向master发送命令psync {replid} {offset}
2.master判断是否第一次同步,如果replid相同则不是第一次同步,返回continue
3.master会从repl_baklong中获取到slave发送的offset之后的数据并将命令发送给slave
4.slave接收到后执行命令完成增量同步。
接下来看一下哨兵模式:
在Redis主从复制模式中,因为系统不具备自动恢复的功能,所以当主服务器(master)宕机后,需要手动把一台从服务器(slave)切换为主服务器。在这个过程中,不仅需要人为干预,而且还会造成一段时间内服务器处于不可用状态,同时数据安全性也得不到保障,因此主从模式的可用性较低,不适用于线上生产环境。
Redis Sentinel 哨兵模式,它弥补了主从模式的不足。Sentinel 通过监控的方式获取主机的工作状态是否正常,当主机发生故障时, Sentinel 会自动进行 Failover(即故障转移),并将其监控的从机提升主服务器(master),从而保证了系统的高可用性。
哨兵的结构和作用如下:
监控:Sentinel 会不断检查master和slave是否按预期工作
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master,然后使用 PubSub 发布订阅模式,通知其他的从节点,修改配置文件,跟随新的主服务器
通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
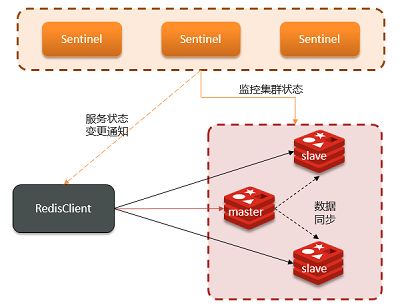
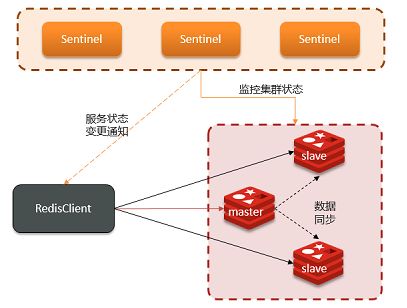
下面详细讲解一下服务状态监控:
Sentinel基于心跳机制检测服务状态,每隔一秒向集群中的每个实例发送ping命令。
如果某sentinel节点发现某实例未在规定时间响应则认为该实例主观下线。
若超过指定数量的sentinel都认为该实例主观下线,则该实例客观下线。指定数量值最好超过sentinel实例总数量的一半。
再来看一下哨兵的选主规则:
1.首先判断一下主与从节点断开的时间长短,如果超过指定值说明断开时间过长,数据丢失过多,于是排除该从节点。
2.判断从节点的优先级(slave-priority)该值越小优先级越高。
3.如果优先级一样则判断该从节点的offset值,offset值越大说明该从节点和主节点的数据越接近,被选主的优先级也就越高。
哨兵模式下的脑裂问题:
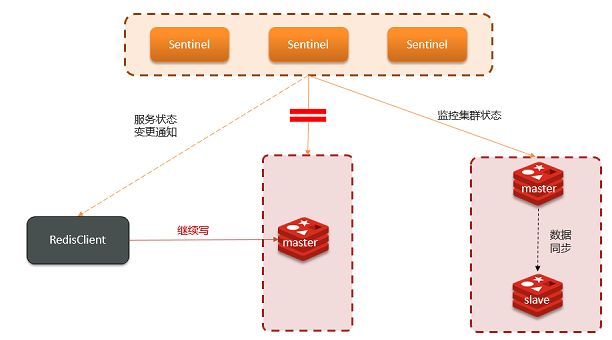
什么是脑裂问题,一旦网络发生了故障,master和sentinel及slave分别处于不同的网络,sentinel检测不到master于是从slave中选择一个提升为master,于是就有了两个master,这也是脑裂名称的由来,此时客户端还在向master中写入数据,等故障恢复以后原来的master被降级为slave,它会将自己的数据清空然后从新的master同步数据这样就会有一部分数据丢失。
怎么解决脑裂问题呢?
可以通过两个配置参数来解决:
min-replicas-to-write 1 表示最少的salve节点为1个
min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过5秒
配置这两个参数以后当发生脑裂时,原来的master会拒绝数据的写入。
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:海量数据存储问题,高并发写的问题
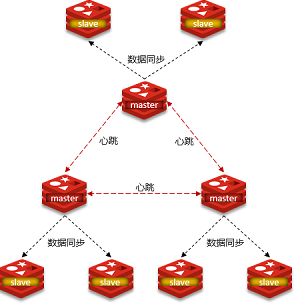
使用分片集群可以解决上述问题,分片集群特征:
集群中有多个master,每个master保存不同数据这样就解决了高并发写的问题。
每个master都可以有多个slave节点,可以解决海量数据的存储和高并发读的问题
master之间通过ping监测彼此健康状态,master起到了哨兵的作用。
客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
既然分片集群有多个master节点,那么如果我要写一个数据究竟会被写到哪个节点上呢?
Redis分片集群引入了哈希槽的概念,redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
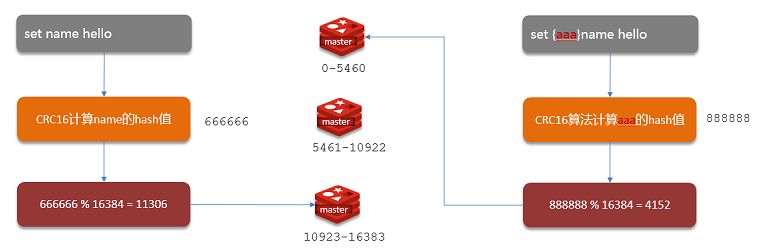
比如集群中有三个master第一个master的哈希槽为0-5460第二个为5461-10922第三个为10923到16383.
假如要执行set name hello 将name hello存入,则会使用CRC16算法计算name的hash值得到666666对16384取模结果为11306,11306处于10923到16383之间,所以该值会被存储到第三个master节点。
如果想将多个键值对放到同一个节点,可以通过设置键的前缀的方式,比如set name hello可以给键name一个前缀set {aaa}name hello用CRC16算法计算其前缀aaa的hash值得到888888,对16384取模结果为4152根据区间放在第一个master节点。如果需要再存入set city Beijing 也可以设置前缀set {aaa}city Beijing这样该键值对也会写入第一个master节点。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











