






 本文详细解释了Spark任务的提交流程,涉及SparkContext、资源管理器和Executor的角色,以及Spark运行时环境的构建、DAG的转换和调度。通过实例说明了从需求提出到任务执行的完整过程,包括数据本地性和推测执行等优化策略。
本文详细解释了Spark任务的提交流程,涉及SparkContext、资源管理器和Executor的角色,以及Spark运行时环境的构建、DAG的转换和调度。通过实例说明了从需求提出到任务执行的完整过程,包括数据本地性和推测执行等优化策略。
Spark任务角色对应
- SparkContext:产品经理,提交需求,制定预计开发计划;
- 资源管理器RM:开发小组长,对接需求跟组内资源协调;
- Executor:开发工程师,需求落地。
Spark的任务提交流程其实跟我们日常大数据部门需求开发流程极其类似。SparkContext相当于我们的产品经理,他会提出需求、确认口径,并且会规划整体的开发计划;资源管理器就是我们数据部门的小组长,他知道组内的开发资源,包括哪个工程师有时间,哪个工程师对需求响应的业务更加了解;Executor更像是我们的开发工程师,不断地向小组长反馈手中的工作量,并且向项目产品经理实时反馈开发进度。
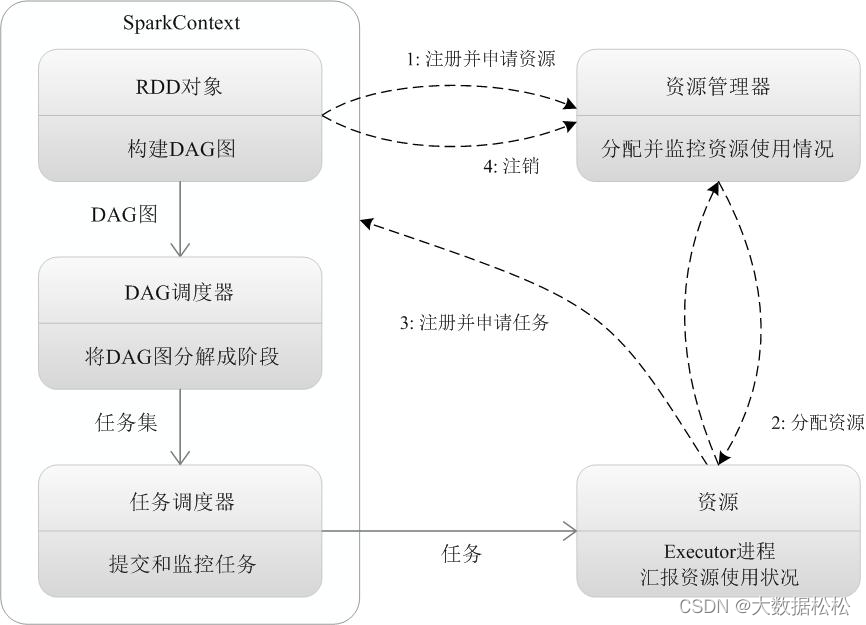
Spark的工作流程
-
客户端提交程序后,Driver端的SparkSubmit进程和Master进行通信,构建Application运行环境,并创建SparkContext;
- SparkContext向资源管理区(可以是Standalone、Mesos或者Yarn)注册并申请运行Executor;(产品经理向小组长询问是否有人能开发需求)
- 资源管理器分配Executor资源并且启动,Executor的运行情况将随着心跳发送给资源管理器;(小组长排查资源找到有时间且对业务相对熟悉的人员开发)
- SparkContext构建DAG有向无环图,通过款窄依赖将DAG有向无环图拆分成不同的Stage,也就是TaskSet,同时启动DAG Schedule跟TaskSchedule两个进程,将TaskSet任务提交给TaskSchedule;(产品经理拆分任务环节,沟通需求口径,规划预计上线时间等)
- Executor向SparkContext申请task,taskSchedule将Task发放给Executor运行,同时SparkContext将运行程序代码也发放给Executor;(任务发放到工程师手里,工程师开始开发)
- Task在Executor上运行,运行完成后释放所有资源。(开发完成,上线交付,释放开发人力资源)
Driver开始执行main函数,Spark查询为懒执行,transform算子可以理解为产品经理再推算预计上线计划;当执行Action算子开始反向推算,只有需求到开发人员手里的时候才是真正开始开发的时间,并且根据手里的总工作量开始排期,根据优先级划分手中的工作优先级顺序;随后每个Stage对应一个TaskSet,根据工程师的能力和时间进行开发。
Spark任务提交的全流程
- 调用SparkSubmit类,内部执行submit-->doRunMain-->通过反射获取应用程序的主类对象-->执行主类的main方法;
- 构建SparkConf和SparkContext对象,在SparkContext入口做了三件事,创建了SparkEnv对象(创建了ActorSystem对象),TaskScheduler(用来生成并发送task给executor),DAGScheduler(用来划分Stage);
- ClientActor将任务信息封装到ApplicationDescription对象里并且提交给Master;
- Master收到ClientActor提交的任务信息后,把任务信息存在内存中,然后将任务信息放到队列中;
- 当开始执行这个任务信息的时候,调用Scheduler方法,进行资源的调度;
- 将调度好的资源封装到LaunchExecutor并发送给对应的Worker;
- Worker接收到Master发送过来的调度信息(LaunchExecutor)后,将信息封装成一个ExecutorRunner对象;
- 封装成ExecutorRunner后,调用ExecutorRunner的start方法,开始启动CoarseGrainedExecutorBackend对象;
- Executor启动后向DriverActor进行反向注册;
- 与DriverActor注册成功后,创建一个线程池(ThreadPool),用来执行任务;
- 当所有的Executor注册完成后,意味着作业环境准备好了,Driver端会结束与SparkContext对象的初始化;
- 当Driver初始化完成后(创建了sc实例),会继续执行我们提交的App的代码,当触发了Action的RDD算子时,就触发了一个Job,这时就会调用DAGScheduler对象进行Stage划分;
- DAGScheduler开始进行Stage划分;
- 将划分好的Stage按照区域生成一个一个的task,并且封装到TaskSet对象,然后将TaskSet提交到TaskScheduler;
- TaskScheduler接收到提交过来的TaskSet,拿到一个序列化器,对TaskSet序列化,将序列化好的TaskSet封装到LaunchExecutor并提交到DriverActor;
- 把LaunchExecutor发送到Executor上;
- Executor接收到DriverActor发送过来的任务(LaunchExecutor),会将其封装成TaskRunner,然后从线程池中获取线程来执行TaskRunner;
- TaskRunner拿到反序列化器,反序列化TaskSet,然后执行App代码,也就是对RDD分区上执行的算子和自定义函数。
二、Spark运行原理解析
一个Spark运行时环境由四个阶段构成:
- 阶段一:构建应用程序运行时环境;
- 阶段二:将应用程序转换成DAG有向无环图;
- 阶段三:按照依赖关系调度执行DAG图;
- 阶段四:销毁应用程序运行时环境。
2.1构建运行程序运行时环境
为了运行一个运行程序,Spark首先根据应用程序资源需求构建一个运行时环境,这是通过与资源管理器交互来完成的。通常而言,存在两种运行时环境构建方式:粗粒度和细粒度。
- 粗粒度:应用程序被提交到集群之后,他在正式运行任务之前,将根据应用程序资源需求一次性将这些资源凑齐,之后使用这些资源运行任务,整个运行过程中不再申请新的资源;
- 细粒度:应用程序被提交到集群后,动态向集群资源管理器申请资源,只要等到资源满足一个任务的运行,便开始运行该任务,而不是必须等到所有资源全部到位。目前,基于Hadoop的MapReduce任务就是基于细粒度运行时环境构建方式。
对于Spark on YARN,目前仅支持粗粒度构建方式。不管何种方式,除了启动任务相关的组件外,每个Executor还需要启动一个RDD缓存管理服务BlockManager,该服务采用了分布式Master/Slaves架构,其中主控节点上启动Master服务BlockManagerMaster,它掌握了所有RDD缓存的位置,从节点则启动Slave服务BlockManager,供客户端存取RDD使用。
2.2 应用程序转换DAG
Spark将依赖分为窄依赖于宽依赖;在将应用程序转换成DAG的过程中,Spark的调度程序会检查依赖关系的类型,根据RDD依赖关系将应用程序划分为若干个Stage,每个Stage启动一定数目的任务进行并行处理。
Spark采用了贪心算法划分阶段,即如果子RDD的分区到父RDD的分区是窄依赖,就实施经典的Fusion(融合)优化,把对应的操作划分到一个Stage,如果连续变换算子序列都是窄依赖,就可以把很多个操作并到一个Stage,指导遇到一个宽依赖。这不但减少了大量的全局屏障(Barrier),而且无需物化很多中间结果RDD,极大的提升了性能,Spark把这个称为流水线(pipeline)。宽依赖在一个执行中会跨越连续的Stage,同时需要显示指定多个子RDD的分区。
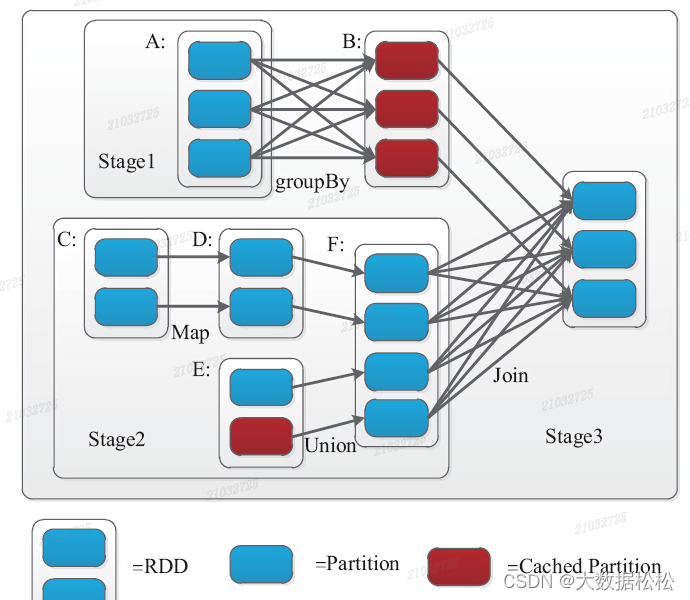
一个框代表一个RDD;一个蓝色单元格标识一个分区Partition;一个红色框代表RDD缓存Cached Partition。一个Stage的边界,输入时外部存储或者一个Stage Shuffle的结果;输出是Job的结果(result task对应的stage)或者shuffle的结果。上图stage3的输入则是RDD A和RDD F Shuffle的结果。而A和F优于到B和G需要shuffle,因此需要划分到不同的stage。DAGscheduler将Stage划分完成后,提交实际上是通过把Stage转换为TaskSet,然后通过TaskScheduler将计算结果提交到集群。
2.3调度执行DAG图
在该阶段中,DAGScheduler将按照依赖关系调度关系调度执行每个Stage:优先选择哪些不依赖任何阶段的Stage,待这些阶段完成后,再调度那些需要依赖的阶段已经运行完成的Stage。依次进行,这样一直调度下去,直到所有阶段运行完成。
在处理某个阶段时,Spark将为之启动一定数目的Task并行执行,为了提高任务 的执行效率,Spark借鉴MapReduce中的优化机制,包括数据本地性和推测执行:
- 数据本地性:是指对任务进行调度时为算子选择数据匹配的节点,优先选择数据所在的节点,其次选择数据所在的机架上的节点,最后先择其他机架上的节点。针对输入数据数量较少时本地性变化的情况采用了延迟调度(delay Scheduling)机制,即当不存在满足本地性的资源时,暂时将资源分配给其他任务,直到出现满足本地性的资源或者达到设定的最大时间延迟;
- 推测执行:当检测到同类任务中存在明显比较慢的任务时,尝试为这些比较慢的任务启动备份任务,并将最先完成的计算结果作为最终结果。DAG的推测执行开始于DAG的叶节点,往上追溯父RDD需要的依赖性,最终追溯到源节点。
相对于传统的MapReduce计算框架,Executor针对以下两个方面进行了改进:
- 采取多线程执行具体的任务,减少多线程任务频繁启动的开销,使任务变得非常可靠和高效;
- Executor上会有一个BlockManager存储模块,类似KV系统(内存和磁盘共同作为存储设备),当需要多轮迭代时,可以将中间过程的数据先放到这个存储系统上,后续需要时直接读取该存储数据,而不需要读写到hdfs等相关的文件系统里;或者在交互查询场景下,事先将表缓存到该存储系统上,提高读写性能。
典型的DAG执行流程如下:
- RDD直接从外部数据源(HDFS、本地文件等)创建;
- RDD经历一系列的Transformation(Map、FlatMap、Fliter、Groupby、Join),每一次都会产生不同的RDD,供给下一个Transformation使用;
- 当触发Action(count、Collect、Save、Take)时,将最后一个RDD进行转换,输出到外部数据源。
这一系列处理过程称为一个血统(Lineage),即DAG拓扑排序的结果。在Lineage中生成的每个RDD都是不可变的。事实上,除非被缓存,每个RDD在进入下一个Transformation操作之前都只是用一次。
如果按照MapReduce,流程中任何一个步骤出了问题,都会重新计算,但是在Spark中,由于有血统Lineage的存在,可以采取中间持久化的方式进行容错处理,避免全部重新计算。
执行DAG的过程如下:首相应用程序创建SparkContext的实例,如实例为sc,这是应用程序与集群交互唯一的通道;其次,利用SparkContext的实例创建生成RDD,经过一连串的Transformation操作,原始的RDD转换成其他类型的RDD;最后,当Action作用于转换之后的RDD时,会调用SparkContext的runJob方法。sc.runmlil的调用是后面一连串反应的起点,提交应用程序进行针对性的计算。任务执行完毕,将销毁运行时环境,释放应用程序占用的资源,归还给集群,以供其他程序使用。
2.4Spark作业执行,运行实例
- 第一步:根据代码和集群交互,申请资源,初始化运行时环境;
- 第二步:将应用程序转换成DAG图。将应用程序转换成DAG图,实质上时通过Spark的操作函数来标记各种RDD,关联各种RDD之间的依赖关系构成DAG图,并划分成不同的Stage。textFile、Filter、Map、都属于Transformation操作,并不立即执行,而是处于延迟操作状态;Cache也是惰性(Lazy)执行的,只有当Cache过的数据做Action操作时,才会将Cache的RDD缓存起来,供后续迭代使用。
- 第三步:按照依赖关系调度执行DAG图。从HDFS文件中记录读取log日志信息,产生MappedRDD;经过Fliter过滤函数,结果产生FilteredRDD;使用Map执行分词去第一列的函数,返回新的MappedRDD;最后将其Cache到内存。
- 最后,执行完毕,销毁应用程序运行时环境,释放资源。
文章来源:《Spark核心技术与高级应用》 作者:于俊;向海;代其锋;马海平
文章内容仅供学习交流,如有侵犯,及时联系~


















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











