







在这篇博文中,我们将探讨如何使用AWS服务设计并实现一个完全适用于生产环境的无服务器消息推送/通知系统。该架构能够根据系统内特定事件,向客户发送各类通知。
此系统专为可扩展性而设计,支持大规模应用程序,每秒能够处理数百甚至数千条通知。我们将利用AWS服务构建这一解决方案,并探索不同的设计模式,从成本、性能及其他关键因素进行评估。
一、理解功能需求
我们的目标是设计一个每秒能够处理大量通知的系统,同时确保其可扩展性,以便在系统发展过程中适应新的通知类型。该系统的主要功能需求包括:
- 支持多种通知类型:系统必须支持各种通知类型,如推送通知、短信和电子邮件。
- 客户选择接收或不接收的偏好设置:用户应能够管理自己的通知偏好,选择希望接收的通知类型。
- 通知提供商的可扩展性:为使系统具有前瞻性,应设计为能够在业务需求增长时轻松集成新的通知类型。
- 为利益相关者提供分析功能:利益相关者应能够在通知系统中使用分析功能,以便深入了解特定时间段(如过去几小时、几天等)内最常发送的通知等指标。
二、非功能需求
业务目标指引我们明确了通知系统的几个关键非功能需求:
- 可扩展性:系统必须能够高效扩展,以处理不断增加的通知量,包括传入和传出的通知。
- 高可用性:为确保服务不间断,系统必须始终保持高可用性。
- 可靠性:系统应保证所有通知都能准确无误地送达。
- 可扩展性:架构应具备灵活性,未来支持新的通知类型或提供商时只需进行最小限度的更改。
- 成本优化:鉴于系统的高使用率,成本效率至关重要。设计应侧重于利用最具成本效益的AWS服务和功能,以降低运营成本。
三、大致估算
我们正在设计的通知系统作为微服务架构中的单个服务运行。在我们的生态系统中,大约有150个服务同时运行,每个服务都会生成事件。然而,并非所有事件都与通知相关。经过对这些服务的分析,我们确定约有20个服务负责生成与通知相关的事件。
在正常情况下,这20个服务每秒总共产生约2000个事件。然而,在高峰使用场景下,如促销活动、限时抢购或系统范围的更新期间,事件生成量可能会大幅飙升。根据历史数据和预测,我们估计峰值负载可能达到每秒5000个事件。系统的设计必须能够处理这些峰值,且不降低性能。
为满足业务需求,系统在处理和发送通知时应追求低延迟。理想情况下,通知应在事件生成后1秒内送达终端客户。在极端高峰场景下,延迟可略有增加,最长可达5秒,但这仅作为持续高峰期间的备用方案。
四、高层次设计
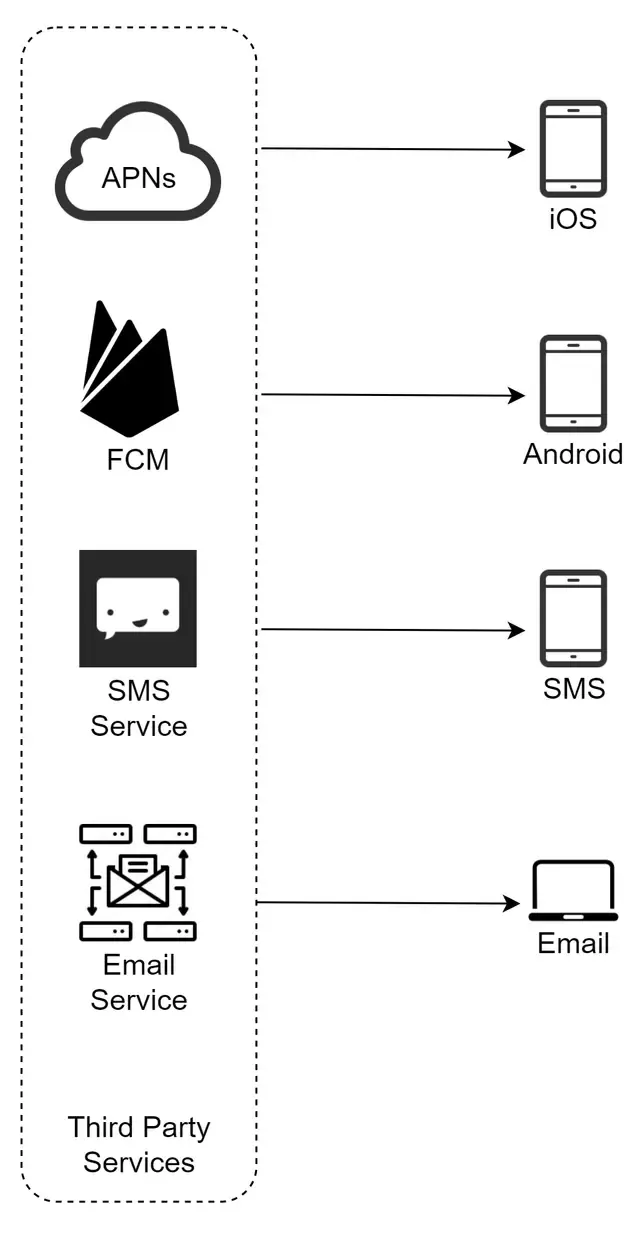
本节概述了支持多种通知类型(包括iOS推送通知、安卓推送通知、短信和电子邮件)的通知系统的高层次设计。该设计分为以下几个组件:
- 高层系统设计:系统架构概述,详细说明不同组件如何交互,以高效处理和传递通知。
- 支持多种通知类型:细分系统如何处理各种通知渠道,如iOS和安卓推送通知、短信和电子邮件,确保灵活性和可扩展性。
- 联系信息收集流程与数据建模:解释如何收集、存储和管理用户联系信息,包括讨论支持用户偏好和通知路由的数据建模。
- 服务调用类型:详细介绍所使用的服务调用模式,如同步、异步或事件驱动机制,以优化通知处理和传递。
- 通知服务职责:通知服务是通知系统的核心,在本节中,我们将讨论通知服务的职责。
4.1 高层次系统设计
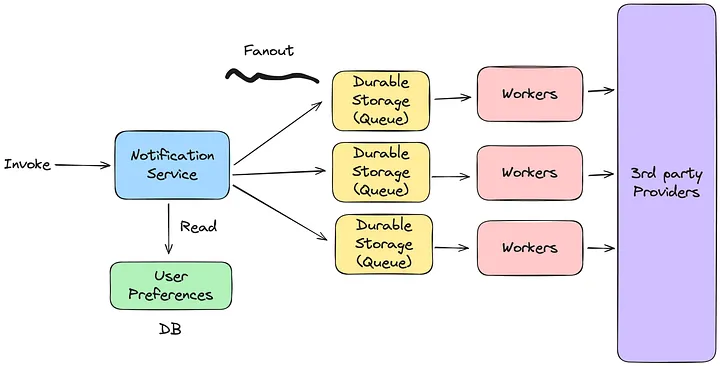
为理解通知系统的高层次设计,我们需要明确其核心职责:
- 事件调用:通知服务必须由系统内生成的相关事件触发。
- 事件类型处理和用户偏好:对于每个事件,服务应确定通知类型,并获取用户对该类型通知的偏好。这确保通知符合用户选择接收或不接收的设置。
- 分发到通知提供商:服务必须处理将通知分发(扇出)到适当的通知提供商,如推送通知、短信网关或电子邮件服务。
- 通知的持久存储:通知应保留在持久存储中,直到成功处理。如果通知处理失败,必须保留在存储中并重试,直至成功送达。
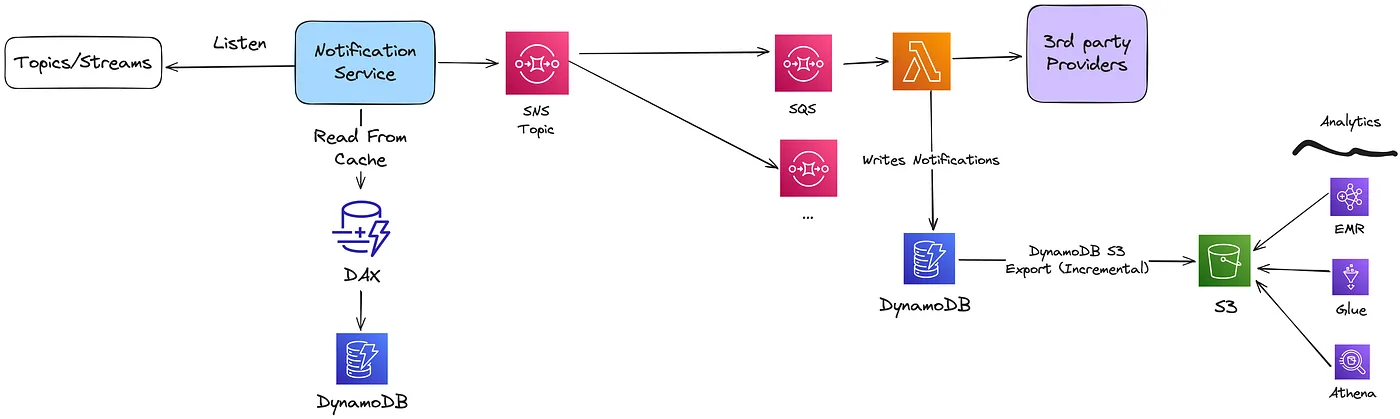
基于这些需求,架构可大致如下所示:
4.2 不同类型的通知
我们首先从高层次上了解每种通知类型。
1. iOS推送通知:
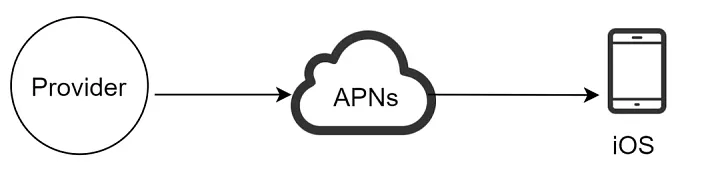
发送iOS推送通知主要需要三个组件:
- 提供商:提供商构建并向苹果推送通知服务(APNs)发送通知请求。为构建推送通知,提供商需提供以下数据:
- 设备Token:这是用于发送推送通知的唯一标识符。
- 负载Payload:这是一个JSON字典,包含通知的负载内容。
{
"aps":{
"alert":{
"title":"订单已提交",
"body":"您有一个新订单已提交,查看订单详情获取更多信息",
"action-loc-key":"查看"
},
"badge":5
}
}
APNs:这是苹果提供的远程服务,用于将推送通知广播到iOS设备。
iOS设备:它是最终客户端,接收推送通知。
2. 安卓推送通知:
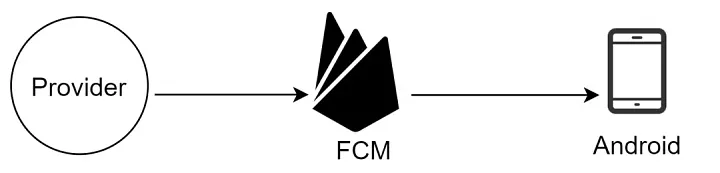
安卓采用类似的通知流程。与iOS不同,安卓通常使用Firebase云消息传递(FCM)向安卓设备发送推送通知。
3. 短信:
对于短信,通常使用第三方短信服务,如Twilio、Infobip等,其中大多数是商业服务。
4. 电子邮件:
尽管公司可以自行设置电子邮件服务器,但许多公司选择商业电子邮件服务。Sendgrid和Mailchimp是最受欢迎的电子邮件服务之一,它们提供更高的送达率和数据分析功能。
因此,我们可以在下图中总结所有提供商的列表:
4.3 用户信息收集流程
为使用AWS服务设计一个有效的通知系统,我们必须根据应用程序的需求选择合适的数据存储解决方案。考虑到系统在正常情况下每秒处理约2000个事件,高峰时每秒处理多达5000个事件,数据库必须能够高效处理高读取负载。每个事件都需要读取用户的通知偏好,使得该流程以读取为主。
对于这种情况,我们需要一个满足以下条件的数据库:
- 易于设置和维护。
- 能够无缝扩展以处理不断增长的读取需求。
- 在性能和成本方面进行优化。
为满足这些要求,我们考虑两种AWS数据库选项:
- Amazon DynamoDB:这是一个NoSQL、可扩展且高可用的数据库,旨在管理大量的读写操作。它提供强大的性能,但需要精心设计Schema以优化查询。
- Amazon RDS Aurora:这是一个基于SQL的、按需自动扩展的亚马逊Aurora数据库。它会根据应用程序需求自动调整容量,简化数据库管理。
在选择这两种数据库类型时,我们必须评估以下因素:
- 数据模型兼容性
- 可扩展性和性能
- 生态系统兼容性
- 成本
现在,让我们基于这些关键标准对这些数据库进行比较。
4.3.1 数据模型兼容性:
在我们的案例中,数据建模需求相对简单。用户偏好可以按每个用户存储为单行或多行。让我们探讨这两种数据建模选项:
-
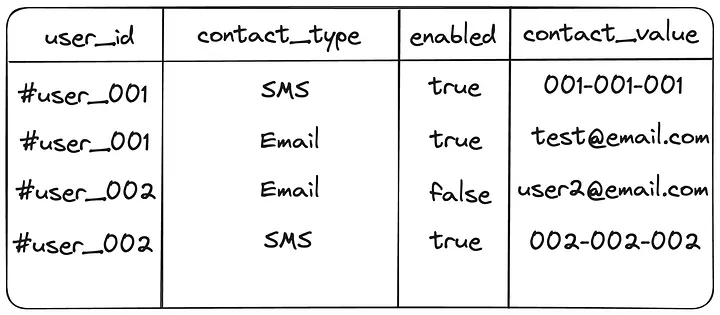
每个用户每种推送Preference单行存储:在这种模型中,每行代表一个独特的用户偏好。这种方法便于添加或删除偏好。我们可以使用用户标识符存储每个偏好,并在查询时根据“启用Enabled”字段过滤偏好。这种模型的优点包括:更容易更新,添加新偏好时更灵活;基于用户ID进行高效查询。
-
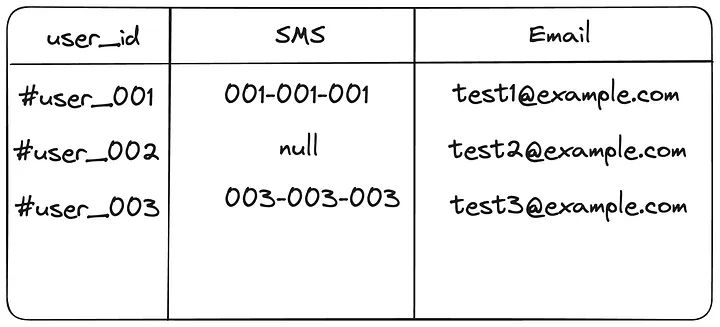
每个用户所有推送Preference单行存储:在此模型中,所有用户偏好存储在单行中。这意味着我们可以通过一次读取操作查询整个偏好集。但是,我们需要确保对同一行的并发写入不会覆盖偏好。其主要优点是:数据库中的行数较少,简化整体结构;单个查询可以一次性返回所有用户偏好,这可能提高性能。
这两种模式设计都适用于DynamoDB和Aurora(PostgreSQL),但有一些重要的考虑因素:
- 模式灵活性:随着系统的发展,添加新字段或偏好将是必要的。在
每个用户每种推送Preference单行存储设计中,我们可以简单地添加新行,而无需担心模式迁移。相比之下,每个用户所有推送Preference单行存储设计在添加新字段时需要进行模式迁移。 - 迁移复杂性:对于
每个用户所有推送Preference单行存储方法,添加新偏好时可能需要进行模式迁移,尽管这种情况不太可能频繁发生。另一方面,对于DynamoDB,由于它是一个NoSQL数据库,可以轻松适应结构变化,因此无需迁移。
从我的角度来看,在模式管理方面没有明显的赢家,因为考虑到模式的简单性,两种选项都很直接。然而,DynamoDB具有无需模式迁移的优势,这可以简化操作。作为一个不希望在简单模式设计中管理模式迁移,特别是在没有复杂关系的情况下的人,我会倾向于在这个特定用例中使用DynamoDB。
4.3.2 可扩展性和性能:
为评估系统的可扩展性和性能,我们需要确定它是读密集型还是写密集型。
- 写操作:在我们的系统中,写操作相对较少。我们只遇到两种类型的写入:
- 账户创建:当用户创建账户时,存储他们的偏好。
- 偏好更新:当用户更新他们的通知偏好时,记录更改。
然而,账户创建并非繁重的写操作。考虑到流行应用程序的典型增长情况,每天可能获得5000到10000个新用户,就写入记录而言,这个数量并不庞大。同样,用户偏好的更新也不频繁。大多数用户只是偶尔更新他们的偏好,想想你上次在Medium.com上更新偏好是什么时候!鉴于用户数量众多,更新频率仍然相对较低,因此即使有大量用户,这些写入操作也可以轻松由任何数据库处理。
- 读操作:然而,我们的系统是读密集型的。每秒大约生成5000个事件,每个事件都需要读取用户偏好以确定合适的通知。这导致高峰负载时每秒约5000次读取,正常负载时每秒2000次读取。
DynamoDB和RDS Aurora都可以处理这种读取量,但它们各有独特的方法:
- DynamoDB:DynamoDB根据分区键(user_id)将读取请求分布到多个分区。每个分区最多可以处理3000个RCU(读取容量单位)。为计算每秒2000次读取所需的RCU:
- 假设每个项目大小为4KB或更小,我们计算正常负载:2000次读取÷每个RCU 2次读取 = 1000个RCU。
- 假设每个项目大小为4KB或更小,我们计算高峰负载:5000次读取÷每个RCU 2次读取 = 2500个RCU。
在生产环境中,读取操作可能会分布在许多分区上,因此DynamoDB可以轻松扩展以满足读取需求。随着读取流量的增加&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











