






目录
作编辑DataFra编辑七:filter()/where条件查询
九:sort()/orderBy():对特定字段进行排序desc:降序;asc:升序
1、通过SparkSession中的createDataset来创建Dataset
2、DataFrame通过“as[ElementType]”方法转换得到Dataset
一:Spark SQL的简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
二:Spark SQL主要提供了以下三个功能:
三:Spark SQL 架构详解
Spark SQL 的核心组成部分包括:
- DataFrame: 这是 Spark SQL 提供的一个分布式数据集,它带有 Schema 元信息,使得 Spark SQL 可以进行某些形式的执行优化。DataFrame 是从 RDD 派生而来的,但它带有额外的结构信息,使得 Spark 可以对数据进行更好的优化处理23。
- SQL 查询引擎: Spark SQL 内置了一个 SQL 查询引擎,它支持执行 SQL 语句,使得用户可以以 SQL 的方式查询数据。Spark SQL 还支持将 SQL 查询与 Spark 程序无缝混合使用,这大大提高了其灵活性和易用性23。
- 优化器: Catalyst 是 Spark SQL 的执行优化器,它负责对 SQL 查询进行解析和优化,以提高执行效率。Catalyst 优化器可以处理和优化多种类型的 SQL 语句,包括那些涉及复杂数据处理逻辑的语句3。
- 插件系统: Spark SQL 有一个插件系统,允许开发者扩展其功能,如添加新的数据源或数据 sink。

四:DataFrame简介
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
DataFrame 是 Spark SQL 提供的一个分布式数据集,它是带有 Schema 元信息的 DataSet,可以看作是关系数据库中的一个表。DataFrame 可以从多种源构建,如结构化数据文件、Hive 表、外部数据库或现有的 RDD。它支持 Spark SQL 查询和 DataFrame API,可以方便地进行数据处理和转换23。

五:DataFrame的创建
创建DataFrame的两种基本方式:
通过Spark读取数据源直接创建DataFrame
 若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,在创建Dataframe之前,为了支持RDD转换成Dataframe及后续的SQL操作,需要导入import.spark.implicits._包启用隐式转换。若使用SparkSession方式创建Dataframe,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,具体操作API如表4-1所示。
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,在创建Dataframe之前,为了支持RDD转换成Dataframe及后续的SQL操作,需要导入import.spark.implicits._包启用隐式转换。若使用SparkSession方式创建Dataframe,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,具体操作API如表4-1所示。
| 方法名称 | 相关说明 |
| spark.read.text("people.txt") | 读取txt格式文件,创建DataFrame |
| spark.read.csv ("people.csv") | 读取csv格式文件,创建DataFrame |
| spark.read.json("people.json") | 读取json格式文件,创建DataFrame |
| spark.read.parquet("people.parquet") | 读取parquet格式文件,创建DataFrame |
1.数据准备
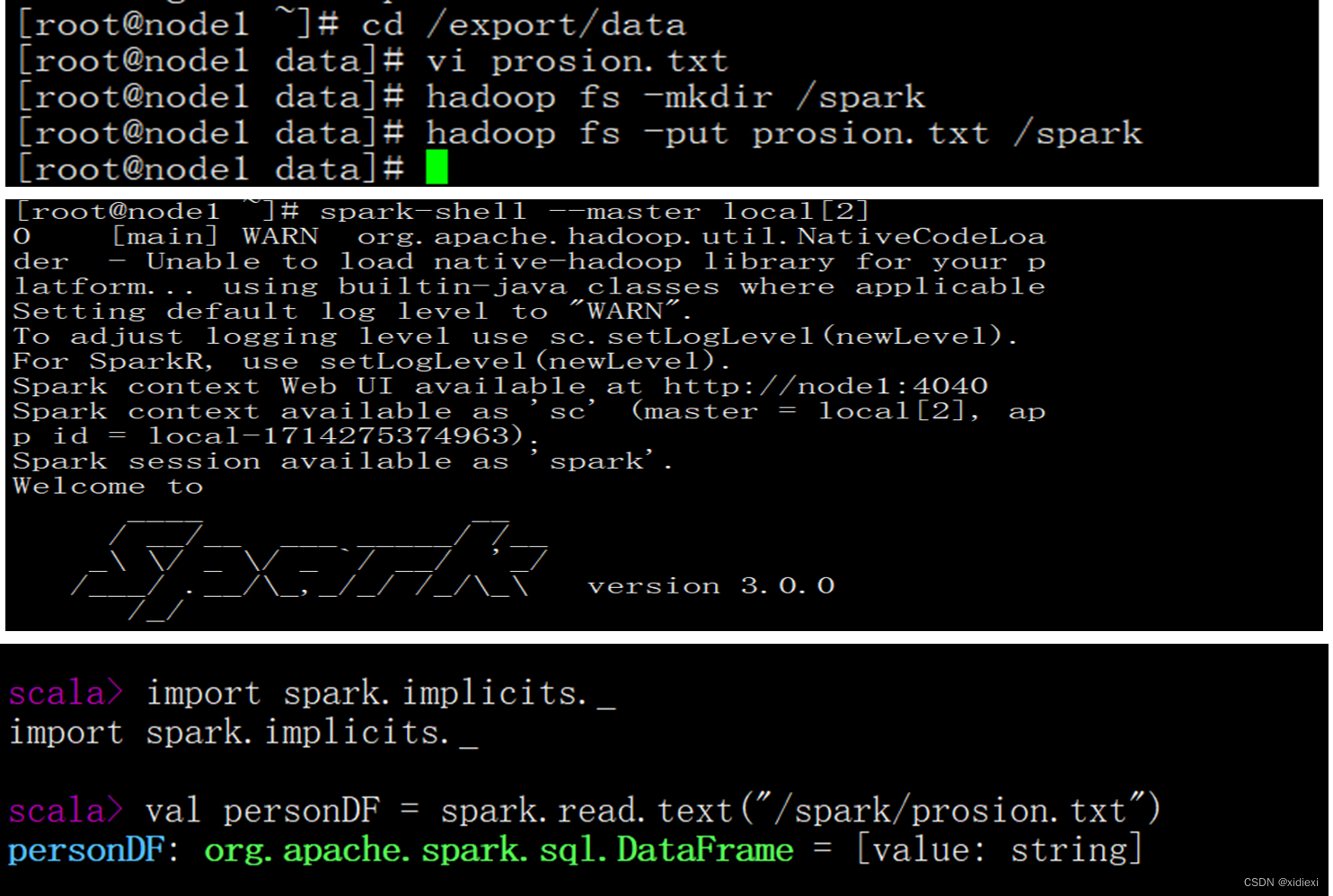
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 jerry 40
2.通过文件直接创建DataFrame
我们通过Spark读取数据源的方式进行创建DataFrame
scala > val personDF = spark.read.text("/spark/person.txt")
personDF: org.apache.spark.sql.DataFrame = [value: String]
scala > personDF.printSchema()
root
|-- value: String (Nullable = true)
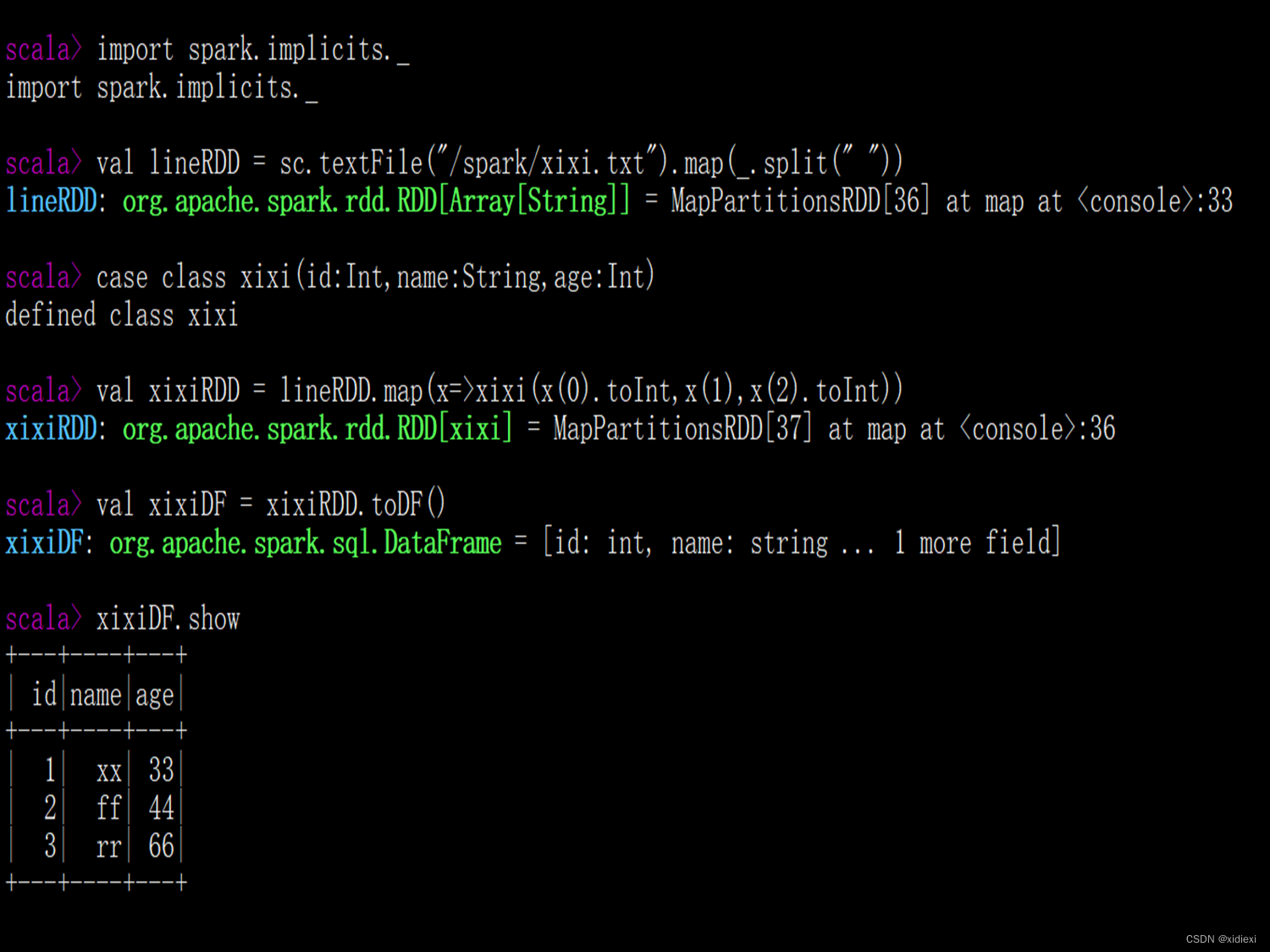
3.RDD直接转换为DataFrame
scala > val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))
lineRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[6] at map at <console>:24
scala > case class Person(id:Int,name:String,age:Int) defined class Person
scala > val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[7] at map at <console>:27
scala > val personDF = personRDD.toDF()
personDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
 六: DataFrame的常用操作
六: DataFrame的常用操作
. 1操作DataFrame的常用方法,具体如下表如示。
| 方法名称 | 相关说明 |
| show(30) | 查看DataFrame中的具体内容信息 |
| selectExpr() | 对指定字段进行特殊处理(替换) |
| select() | 查看DataFrame中获取指定字段 |
| filter()/where | 实现条件查询,过滤出想要的结果 |
| groupBy() | 对记录进行分组 |
| sort() | 对特定字段进行排序操作 |
作 DataFra
DataFra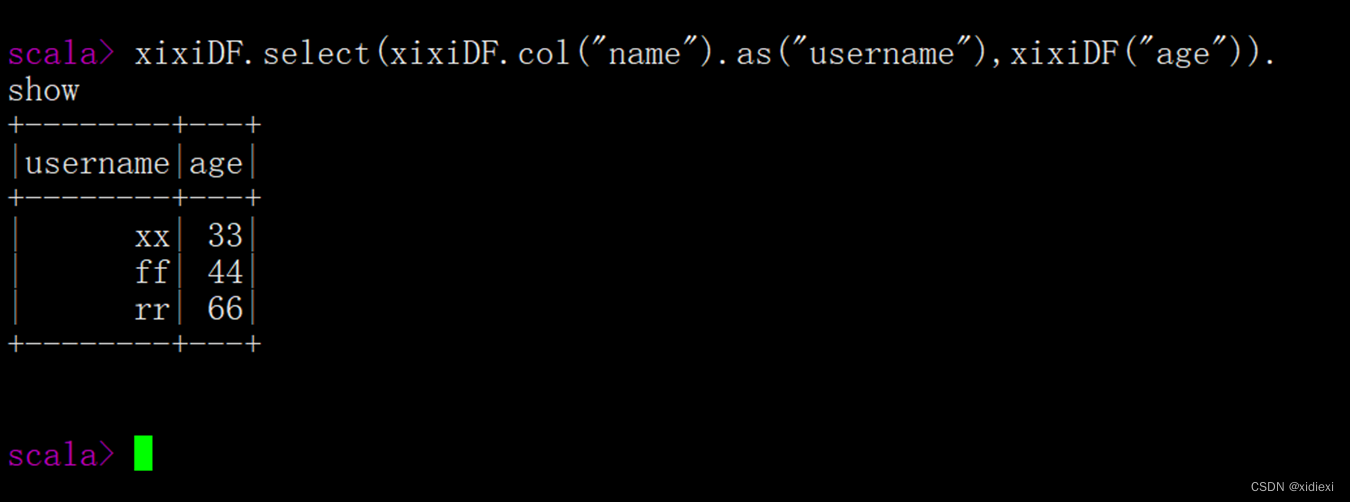 七:filter()/where条件查询
七:filter()/where条件查询
filter() 与 where 条件查询
在JavaScript中,filter()方法可用于从数组中筛选出符合特定条件的元素。该方法接受一个回调函数作为参数,该回调函数定义了筛选的条件。例如,如果要筛选出数组中所有年龄超过20岁的对象,我们可以使用以下代码:
const people = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 18 },
{ name: 'Charlie', age: 22 }
];
const adults = people.filter(person => person.age > 20);
console.log(adults);输出结果将是所有年龄超过20岁的对象。
类似地,在数据库查询中,WHERE条件用于过滤结果集,只返回符合特定条件的记录。例如,在SQL中,如果我们想查询所有年龄超过20岁的用户,我们会使用:
SELECT * FROM users WHERE age > 20;八:mgroupBy()对数据进行分组
mgroupBy() 对数据进行分组
在JavaScript中,尽管没有内置的mgroupBy()方法,但我们可以通过其他方法实现数据的分组。常见的方法包括使用哈希表(Object.keys())和数组的reduce()方法来进行分组。
例如,以下代码展示了如何使用哈希表对一组数据进行分组:
const data = [
{ key: 'a', value: 1 },
{ key: 'b', value: 2 },
{ key: 'c', value: 3 }
];
const groupedData = Object.keys(data).reduce((acc, key) => {
acc[key] = data[key];
return acc;
}, {});
console.log(groupedData);这段代码将data数组中的数据按key进行分组,最终输出一个对象,其键为a、b和c,对应的值为1、2和3。
在数据库中,GROUP BY用于对数据进行分组。例如,在SQL中,如果我们想对用户按年龄分组:
SELECT age, COUNT(*) FROM users GROUP BY age;这将返回每个年龄组的用户计数。
九:sort()/orderBy():对特定字段进行排序
desc:降序;asc:升序
sort() / orderBy() 对特定字段进行排序
JavaScript的sort()方法可用于对数组中的元素进行排序。当应用于数组对象时,可以提供比较函数来根据特定字段进行排序。例如,以下代码展示了如何根据年龄对用户数组进行排序:
const users = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 18 },
{ name: 'Charlie', age: 22 }
];
users.sort((a, b) => a.age - b.age);
console.log(users);输出结果将是按年龄排序的用户数组。
在数据库中,ORDER BY用于根据一个或多个字段对结果进行排序。例如,在SQL中,如果我们想按年龄降序排序用户:
SELECT * FROM users ORDER BY age DESC;这将返回按年龄降序排序的用户结果。
总结
综上所述,无论是通过filter()进行条件查询,还是通过mgroupBy()进行数据分组,抑或是通过sort()和orderBy()对特定字段进行排序,这些操作都是在数据处理中常见的步骤,而在不同的编程环境和语言中,这些功能的实现方式虽有所不同,但概念是一致的。在JavaScript中,由于缺乏某些内置方法,我们常常需要借助数组的其他方法或手动实现来完成这些操作。在数据库中,这些操作通常是通过专门的SQL语句来完成的。在使用这些技术时,理解它们的工作原理和适用场景是非常重要的。
十:
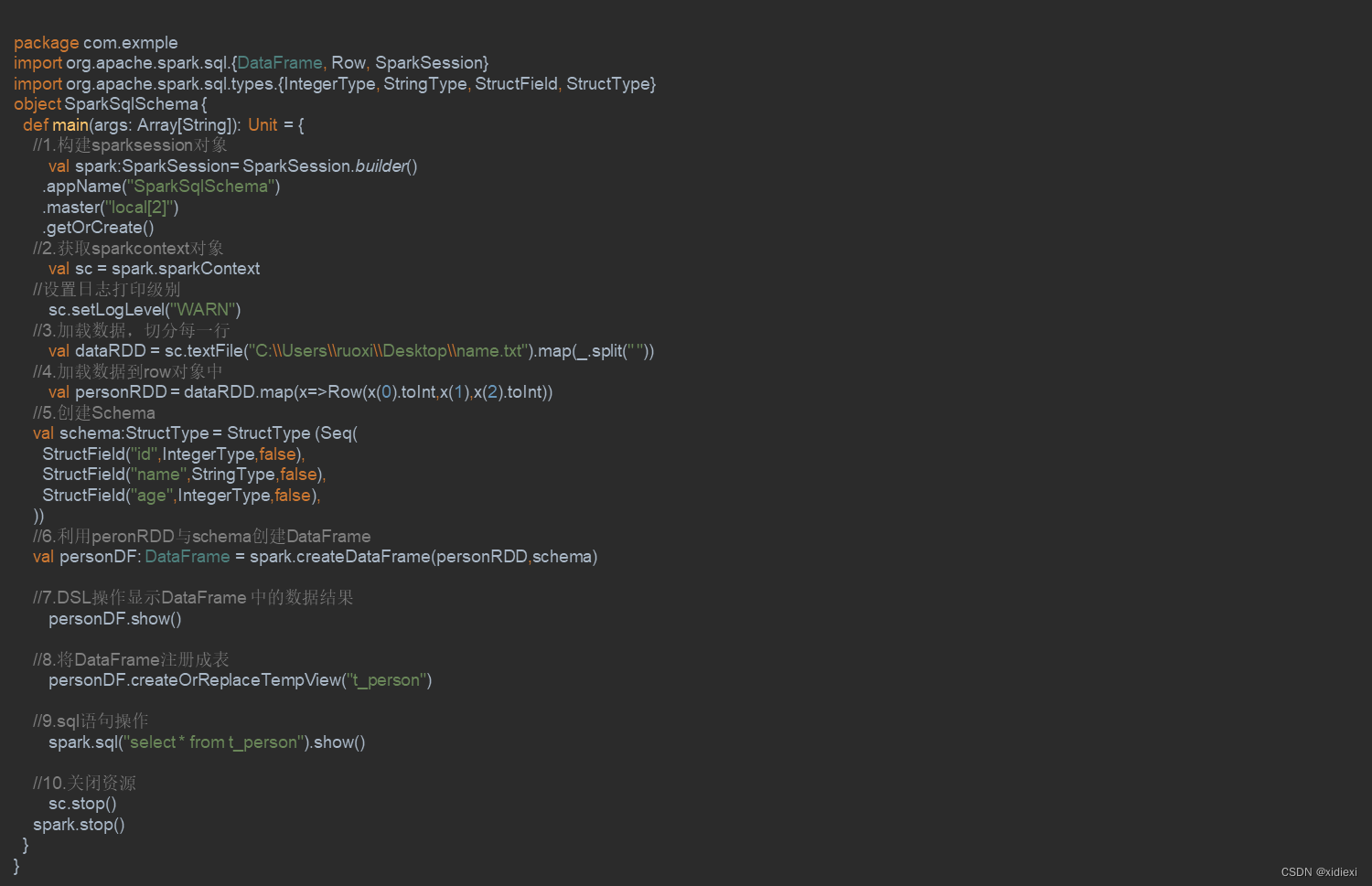
1. 将DataFrame注册成一个临时表 2.
Sscala > xixiDF.registerTempTable("t_xixi")QL风格操作DataFramee操
作十
2. 查询年龄最大的前两名人的信息
scala > spark.sql("select * from t_xixi order by age desc limit 2").show()
+---+------+---+
| id| name|age|
+---+------+---+
| 6| jerry| 40|
| 5|tianqi| 35|
+---+------+---+
3. 查询年龄大于25的人的信息
scala > spark.sql("select * from t_xixi where age > 25").show()
+---+-------+---+
| id | name |age|
+---+-------+---+
| 2 | lisi | 29 |
| 4 | zhaoliu| 30 |
| 5 | tianqi | 35 |
| 6 | jerry | 40 |
+---+-------+---+
十一:RDD、DataFrame及Dataset的区别
接下来,我们来比较一下这三者的不同之处:
| 特性 | RDD | DataFrame | Dataset |
|---|---|---|---|
| 数据类型 | 不可变、可分区、支持并行计算 | 结构化数据、有序、可索引 | 强类型、可变、支持数据流 |
| 适用场景 | 大数据处理、批处理 | 数据仓库、结构化数据处理 | 实时数据处理、复杂数据流处理 |
| 内存占用 | 较低,因为它不可变 | 较高,因为有序且可索引 | 较高,因为支持数据流 |
| 容错性 | 高,通过Lineage重建数据 | 高,因为基于RDD | 高,因为支持数据流 |
| 性能 | 适合大规模数据集 | 适合交互式查询和复杂转换 | 适合实时分析和复杂数据处理 |
| 数据处理能力 | 有限,主要是基础转换操作 | 强大,支持SQL查询和复杂数据处理 | 最强,支持最新数据处理技术和复杂操作 |
D综上所述,RDD、DataFrame和Dataset在Spark SQL中各自扮演着不同的角色,它们共同构成了Spark SQL强大的数据处理能力。在选择使用哪一个时,我们需要根据自己的数据处理需求和场景来决定。
十二:Dataset对象的创建
1、通过SparkSession中的createDataset来创建Dataset

2、DataFrame通过“as[ElementType]”方法转换得到Dataset

十三:RDD转换DataFrame
十四:反射机制推断Schema
反射机制推断Schema的过程
反射机制推断Schema的过程可以通过以下几个步骤来概括:
- 定义样例类:首先需要定义一个包含所需字段的样例类,例如
Person,它代表了数据框中每行的结构。
- 创建SparkSession:建立与Spark集群的连接,并创建一个
SparkSession对象,它是Spark 2.0之后用于数据处理的入口。
- 读取数据:使用
textFile或csv等方法读取数据文件,并将数据解析为一个RDD(Resilient Distributed Dataset)。
- 将RDD与样例类关联:通过
map函数将RDD中的每个元素转换为样例类实例,从而生成一个新的RDD。
- 转换为DataFrame:使用
toDF方法将RDD转换为一个DataFrame对象,这个对象包含了数据的逻辑结构和类型信息。
- 展示和处理DataFrame:可以使用
show方法查看DataFrame的前几行数据,使用printSchema方法查看其Schema。
- 执行SQL查询:可以将DataFrame注册为一个临时表,然后使用SQL语句对其进行查询和分析。
示例代码
以下是一个简化的代码示例,展示了如何使用反射机制推断Schema:
import org.apache.spark.SparkSession
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.Row
// 定义样例类
case class Person(id: Int, name: String, age: Int)
object ReflectiveSchemaInference {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark = SparkSession.builder()
.appName("ReflectiveSchemaInference")
.master("local[*]")
.getOrCreate()
// 读取数据
val data = spark.textFile("data/people.txt").map(line => line.split("\t"))
// 将RDD与样例类关联
val peopleRdd = data.map(row => Person(row(0).toInt, row(1), row(2).toInt))
// 转换为DataFrame
val peopleDf = peopleRdd.toDF
// 展示DataFrame前20行数据
peopleDf.show(20)
// 打印DataFrame的Schema
peopleDf.printSchema()
// 统计年龄大于30的人数
println(peopleDf.filter($"age" > 30).count())
// 关闭SparkSession
spark.stop()
}
}在这个示例中,首先定义了一个Person样例类,然后从文本文件中读取数据,并将其转换为Person类型的RDD。接着,将这个RDD转换为DataFrame,并展示了它的前20行数据以及完整的Schema。最后,进行了一个简单的统计查询,并关闭了SparkSession。
结论
反射机制推断Schema是一种在Spark中自动化数据处理任务的方法,它可以减少手动编写数据处理逻辑的工作量。这种方法的核心在于使用样例类来定义数据结构,并通过反射来自动推断数据的逻辑类型和关系。这种方法不仅适用于Spark,也适用于其他支持类似API的类似大数据处理框架。
十五:编程方式定义Schema
概述
定义Schema有多种方式,可以通过编程语言中的数据类型定义,也可以使用特定的数据描述语言,如XML Schema(XSD)或JSON Schema等。在编程中,定义Schema通常涉及到定义数据类型、数据结构以及数据之间的关系。以下将分别介绍在不同编程环境和语言下定义Schema的方法。
详细分析
Java环境下的定义
在Java环境中,可以使用如Java对象表示法(Java Object Notation)来定义数据类型,并通过反射机制来实现动态类型检查。此外,还可以使用第三方库如Jackson或Gson来更方便地处理JSON格式的Schema定义。
Python环境下的定义
Python通常使用内建的dict类型作为数据结构,通过键值对的方式定义数据类型和关系。在Python 3.5及之后的版本中,可以使用typing模块来定义类型注释,使得代码更为清晰。
JavaScript环境下的定义
在JavaScript中,可以使用对象字面量(Object Literal)来定义数据结构,并通过函数来定义数据类型。ES6之后,可以使用class关键字来定义类,从而更好地组织和管理数据类型。
XML环境下的定义
XML使用标记语言(如XML Schema Definition, XSD)来定义数据类型。通过编写XML Schema文件,可以定义数据元素的类型、结构和约束。
JSON环境下的定义
JSON本身是一种轻量级的数据交换格式,但它也可以用来定义数据类型。通过编写JSON文档,可以描述数据结构及其相互关系。
总结
定义Schema的方法取决于使用的编程语言和环境。无论是在编程语言中直接定义数据类型,还是使用特定的数据描述语言,重要的是确保定义能够准确反映所需的数据结构和行为。
以上内容综合了不同编程环境下定义Schema的方法,考虑到各种环境的特性和优势,在实际应用中,选择最合适的方法取决于具体的项目需求和技术栈。
shie八ata
F十二rame1. 操作DataFrame操作DataFrame
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









