







转载请附上链接http://blog.csdn.net/iemyxie/article/details/38224753
算法简介
NBC是应用最广的分类算法之一。朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
算法假设给定目标值时属性之间互相条件独立。
算法输入
待分类数据x0=(x0(1),x0(2),……,x0(n))T
算法输出
待分类数据x0 的分类结果y0∈{c1,c2,……,ck}
算法思想

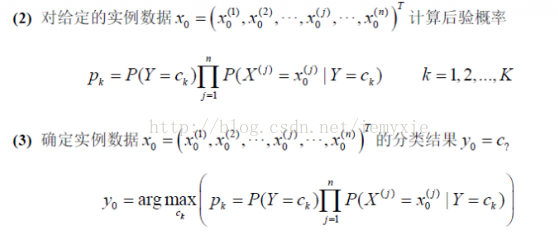
weka运行
以weather.nominal.arff为例运行结果部分截图如下:
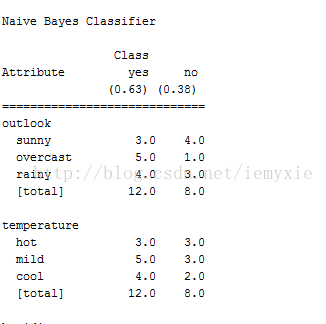

从结果中可以看出,有两个分类,因此生成一个2*2的混淆矩阵。
函数调用代码
//读入样本
Filefile= new File("F:\\Program Files (x86)\\Weka-3-7\\data\\weather.nominal.arff");
ArffLoaderloader = newArffLoader();
loader.setFile(file);
ins= loader.getDataSet();
ins.setClassIndex(ins.numAttributes()-1);
//初始化分类器并训练
cfs= (Classifier)Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();
cfs.buildClassifier(ins);
//获取分类器结果
testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs,testInst);
//打印分类结果
System.out.println("分类器的正确率:"+ (1-testingEvaluation.errorRate()));
运行结果如下:
分类器的正确率:0.9583333333333334
算法应用
垃圾邮件过滤系统可以参考论文:周威成 马素霞 齐林海,一种基于机器学习的垃圾邮件智能过滤方法。
转载请附上链接http://blog.csdn.net/iemyxie/article/details/38224753















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









