







 本文介绍了朴素贝叶斯算法,包括其基本原理、特点、应用场景及变种,如拉普拉斯平滑和逻辑回归。文章通过实例展示了如何对连续数据进行离散化并进行分类决策。
本文介绍了朴素贝叶斯算法,包括其基本原理、特点、应用场景及变种,如拉普拉斯平滑和逻辑回归。文章通过实例展示了如何对连续数据进行离散化并进行分类决策。
简介
Naive和Bayes
Naive:假定向量中的所有特征是相互独立的
Bayes:
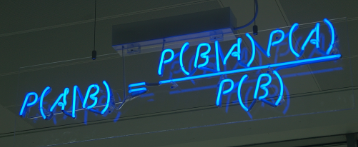
面向的问题
NB主要用于解决有监督分类问题。相比于其他模型,其具备简单(不需要复杂的迭代式参数估计,由此方便处理大数据)、可解释性强(生成模型)、效果佳的特点。
目标
针对二分类问题,利用训练集数据学习一个判断阈值α,对于新来的数据做判定,大于α的数据属于正类,小于α的数据属于负类。有监督分类中存在两大流派 diagnostic paradigm 和 sampling paradigm ,前者注重于发现类间的区别,后者注重于发现类本身的分布形式,NB兼而有之。
算法描述
从sampling paradigm角度出发,定义 P(i|x) 为样本 x=(x1,x2...xp) 属于类别 i 的概率; f(x|i) 为条件为 i 类样本的分布; P(i) 为在没有任何已知数据情况下,样本属于 i 类的先验概率; f(x) 是样本的总体分布,有 f(x)=f(x|1)P(1)+f(x|0)P(0) 。显然, P(i|x)∈[0,1] 就是我们要找的阈值计算公式,一个典型的情况是设置阈值为 0.5。
由Bayes公式,
P(i|x)=f(x|i)P(i)f(x)
P(i)
是类别先验概率,很好估计,
f(x)
在所有样本上一致,因此可以忽略。那么问题就是怎么求
f(x|i)
。根据朴素性假设
f(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









