







 本文介绍了决策树学习的概念及其在机器学习中的应用,强调了其优点和缺点。通过熵和信息增益的概念解释了如何在决策树中选择划分特征。提供了包含熵计算和决策树构建的Python代码示例,并建议通过pickle模块保存和加载决策树以提高效率。
本文介绍了决策树学习的概念及其在机器学习中的应用,强调了其优点和缺点。通过熵和信息增益的概念解释了如何在决策树中选择划分特征。提供了包含熵计算和决策树构建的Python代码示例,并建议通过pickle模块保存和加载决策树以提高效率。
决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树。决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则。决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。缺点为:可能产生过度匹配的问题。决策树适于处理离散型和连续型的数据。
在决策树中最重要的就是如何选取用于划分的特征
在算法中一般选用ID3,D3算法的核心问题是选取在树的每个节点要测试的特征或者属性,希望选择的是最有助于分类实例的属性。如何定量地衡量一个属性的价值呢?这里需要引入熵和信息增益的概念。熵是信息论中广泛使用的一个度量标准,刻画了任意样本集的纯度。
假设有10个训练样本,其中6个的分类标签为yes,4个的分类标签为no,那熵是多少呢?在该例子中,分类的数目为2(yes,no),yes的概率为0.6,no的概率为0.4,则熵为 :
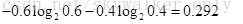
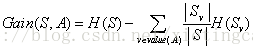
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3158
3158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









