






集合框架:
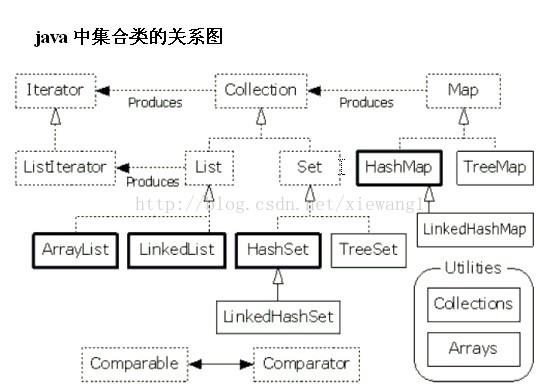
1.Iterate迭代器:取出集合中的元素,只有三个方法:
hasNext():是否有下一个,
next():取出下一个元素
remove():在取出的时候可以删除元素
Iterate迭代器取出时不可以并发操作元素,但iterate可用于操作元素的方法仅有一个,在取出时想要更多的操作可以用ListIterate。
2.list集合的主要两个子集合
ArrayList 和LinkedList
1)ArrayList集合:底层数据结构是数组结构,可以像数组一样存贮元素。
ArrayList常用方法:
创建集合对象 :ArrayList al = new ArrayList();
添加:
删除:
clear() 清空集合中的元素
remove(int index) 删除角标(index)上的元素
判断:
isEmpty() 集合是否为空
获取:
size() 集合的长度(同数组中的length)
get(int index) 获取角标(index)上的元素
替换:
2)LinkedList集合:底层使用的是链表数据结构。
LinkedList常用方法:
添加:
删除:
clear()
判断:
获取:
size()
get(int index)
getFirst()
getLast()
lastIndexOf(Object o)
替换:
ArrayList与LinkeList比较:
ArrayList和LinkedList的方法类似,
由于数据结构不同,ArrayList查询、判断、获取优于LinkedList
LinkedList添加、删除优于ArrayList
ArrayList去重代码示例:
import java.util.ArrayList;
import java.util.ListIterator;
public class ArrayListTest {
public static void main(String [] args){
ArrayList<String> al = new ArrayList<String>();
al.add("java01");
al.add("java02");
al.add("java01");
al.add("java02");
al.add("java03");
ArrayList<String> newal = new ArrayList<String>();
for(ListIterator<String> it = al.listIterator();it.hasNext();){
String s = it.next();
if(!newal.contains(s))
newal.add(s);
}
System.out.println(newal);
}
}
运行结果:
[java01, java02, java03]
2.set集合的两个主要子集合:HashSet集合 TreeSet
1)HashSet集合:特点:底层调用hashcode,无序,不可重复,因为HashSet集合底层使用的hashtable结构 存取时比较的是hashcode,所以HashSet存取对象是要覆写hashcode方法和equals方法
hashcode常用方法:
clear()
isEmpty()
remove(Object o)
size()
覆写hashcode和equals方法示例:
@Override
public int hashCode() {
return this.name.hashCode()+age*23;
}
@Override
public boolean equals(Object obj) {
if(!(obj instanceof Student))
throw new ClassCastException("类型不匹配");
Student s = (Student)obj;
return this.name.equals(s.name)&&this.age==s.age;
}
2)TreeSet集合:特点:底层调用二叉树,有序,不可重复,存储对象是要覆写hashcode方法和equals方法(可选)TreeSet底层结构是二叉树结构,存储时需要排序,想达到排序的目的有两种方法,一种是让对象自身具备比较性:实现Comparable覆写compareTo方法 另一种是写一个比较器:实现Comparator覆写compare方法
TreeSet常用方法:
clear()
isEmpty()
size()
pollLast()
对象自身具备比较性代码示例:
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String [] args){
TreeSet<Student> ts = new TreeSet<Student>();
ts.add(new Student("zhangsan02",32));
ts.add(new Student("zhangsan01",34));
ts.add(new Student("zhangsan03",23));
for(Iterator<Student> it = ts.iterator();it.hasNext();){
Student s = it.next();
System.out.println(s.getName()+"::"+s.getAge());
}
}
}
class Student implements Comparable<Student>{
private String name;
private int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public int compareTo(Student s){//必须跟泛型类型相同,如果不用泛型需要判断是否是Student类不是不要比较抛异常终止程序,是需要强转。
int num =this.name.compareTo(s.name);//比较姓名是否相同
if(num==0)//名字相同比较年龄
return this.age-s.age;//比较年龄是否相同,姓名年龄相同是同一个人
return num;
}
}
运行结果:
zhangsan01::34
zhangsan02::32
zhangsan03::23
zhangsan02::32
zhangsan03::23
自定义一个比较器示例:
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetTest1 {
public static void main(String [] args){
TreeSet<Student> ts= new TreeSet<Student>(new MyComparator());//传比较器让集合自身具备比较性
ts.add(new Student("zhangsan04",23));//上一个示例中有Student的class文件可以直接用,不在代码里重写了.
ts.add(new Student("zhangsan02",23));
ts.add(new Student("zhangsan01",23));
for(Student s:ts){//高级for循环
System.out.println(s.getName()+"::"+s.getAge());
}
}
}
class MyComparator implements Comparator<Student>{//自定义比较器
public int compare(Student s1,Student s2){ //覆写compare方法
int num =s1.getName().compareTo(s2.getName());//按照名字排序
if (num==0)
return s1.getAge()-s2.getAge();//名字相同按照年龄排序
return num;
}
}
运行结果:
zhangsan01::23
zhangsan02::23
zhangsan04::23
zhangsan02::23
zhangsan04::23
3.泛型:
特点:JDK1.5版本后出现的,是一个安全机制,提高安全性。将运行时异常转移到编译时异常
泛型定义。
当传递类型不确定的时候定义泛型
1)泛型定义在类上,整个类中有效,不包含静态方法
2)泛型定义在方法上,不同的方法操作不同类型时定义在方法上(类上定义了泛型,方法上还可以定义泛型)
3)泛型定义在静态方法上。静态方法优先于对象存在,不能使用类上的泛型,静态方法操作的类型不确定,可以将泛型定义在静态方法上。
4)泛型定义在接口上。
泛型限定:
上限:<? extends person>//person类或者person的子类。
下限:<? super person>//person类或者person的父类。
4.Map集合:双列集合:没有迭代器,可以取出键存入set集合,用set集合的迭代器。或者拿到map集合的视图存入set集合中,使用set集合的迭代器。
Hashtable:底层是hash表结构,不可以存入null键null值,线程同步,JDK1.0,效率低
HashMap:底层是hash表结构,可以存入null键null值,线程不同步,JDK1.2,效率高
TreeMap:底层是二叉树结构,线程不同步,可以给map集合中的键排序
Map集合常用的方法:
size()
keySet() 返回set集合
entrySet() 返回map视图的set集合
containsKey(Object key)
containsValue(Object value)
HashMap是Map的子类和Map集合中的方法差不多。
TreeMap也是Map集合的子类。(可以自动给键排序)
通过keySet获取Map元素:
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapKeySet {
public static void main(String [] args){
Map<Integer,String> map = new TreeMap<Integer,String>();
map.put(1,"zhangsan01");
map.put(3,"zhangsan03");
map.put(4,"zhangsan04");
map.put(2,"zhangsan05");
Set<Integer> set = map.keySet();
for(Iterator<Integer> it = set.iterator();it.hasNext();){
Integer key=it.next();
System.out.println(key+"..."+map.get(key));
}
}
}
通过entrySet获取Map集合元素:
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapEntrySet {
public static void main(String [] args){
Map<Integer,String> map = new TreeMap<Integer,String>();
map.put(1,"zhangsan01");
map.put(3,"zhangsan03");
map.put(4,"zhangsan04");
map.put(2,"zhangsan05");
Set<Map.Entry<Integer, String>> set = map.entrySet();
for(Iterator<Map.Entry<Integer, String>> it = set.iterator();it.hasNext();){
Map.Entry<Integer,String> entry = it.next();
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"...."+value);
}
}
}
-----------android培训、java培训、java学习型技术博客、期待与您交流!------------















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









