



论文信息
name_en: High Fidelity Neural Audio Compression
name_ch: 高保真神经音频压缩
paper_addr: http://arxiv.org/abs/2210.13438
date_read: 2023-04-27
date_publish: 2022-10-24
tags: [‘深度学习’,‘音频’]
author: Alexandre Défossez, Meta AI, FAIR Team
code: github.com/facebookresearch/encodec
1 读后感
方法与SoundStream相似,模型主要使用了卷积,LSTM,还加入Transformer优化量化单元,以减少带宽。
2 摘要
Encodec也是一个音频编码器 audio codec,包括编码器-解码器架构、量化方法和感知损失等要素。EnCodec在多个音频压缩比和采样率条件下,在语音和音乐的压缩中均达到了最先进的质量水平。
文章还讨论了神经网络压缩模型的两个问题:如何表示噪音和如何高效地压缩,作者通过构建大而多元化的训练集和引入辨别器网络,解决了第一个问题,而通过引入熵编码和实时模式流的控制来解决第二个问题。
检验了EnCodec的运算速度、实时和压缩效果,得到了较好的实验效果。
3 方法
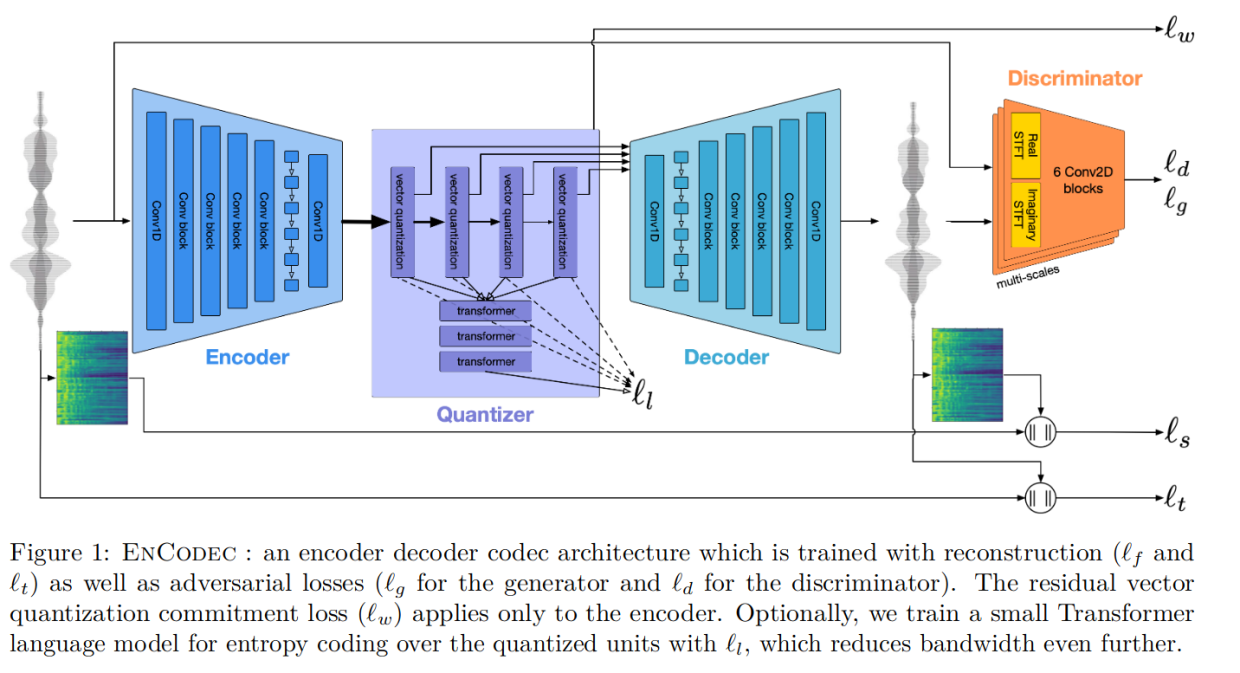
模型由编码器,量化器,解码器三部分组成。
3.1 编解码器结构
如图所示,主要使用卷积结构。另外,同时提供针对流式数据和非流式数据的处理方法。
3.2 残差向量量化
同StreamSound类似,通过在训练时选择不同数量的残差步骤,可以使用单个模型支持多个带宽目标。
3.3 语言建模和熵编码
另外训练了一个小型基于Transformer的语言模型,旨在通过单个CPU核心保持快于实时的端到端压缩/解压缩速度。
该模型包括5层、8个头、200个通道、每个前馈块的维度为800,没有dropout。
在训练时,选择一个带宽和相应的codebook数量Nq。对于时间步t,从时间t-1得到的离散表示使用学习的嵌入表之一变换成连续表示,然后相加。
Transformer的输出被馈送到Nq个线性层,并且每个线性层输出通道的数量与每个codebook的基数(例如1024)相同,这样可以给在时间t上估计占用每个codebook的分布的对数。
因此,在单个时间步骤上忽略了潜在的码书之间的互信息。这样就可以加速推理,并且对最终交叉熵的影响有限。
3.4 训练目标
目标函数结合了重建损失,判别损失,以及量化损失。
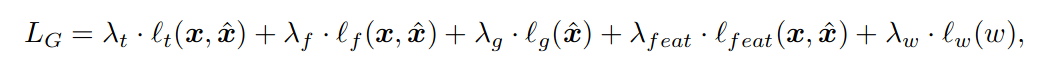
其中x是原始音频,x^是生成音频;
- 重建损失包含时域损失lt和频域损失lf
- lt:评价了音频帧的差异
- lf:评价了多个时间尺度在梅尔频谱的差异
- 对抗损失
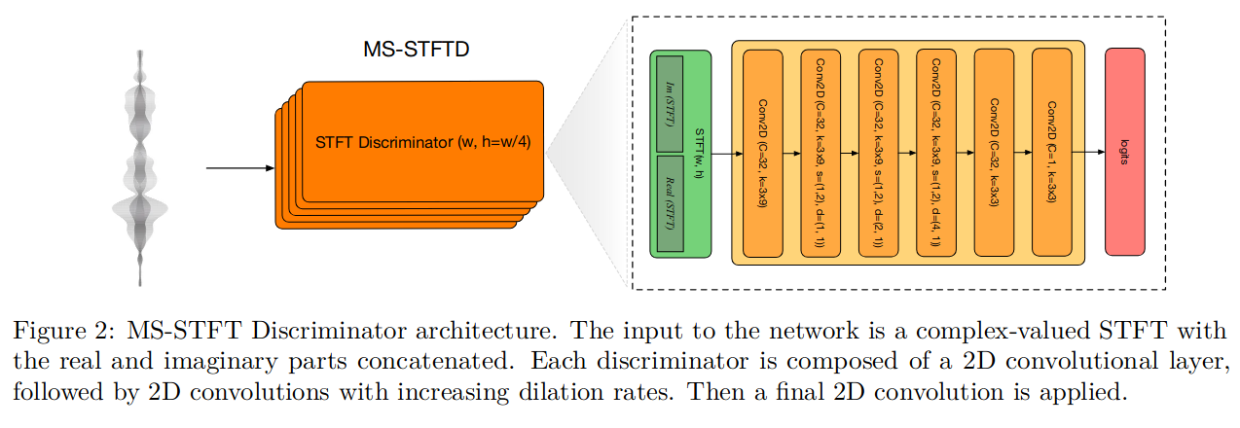
* lg:对抗中的判断器,评价了判别器的损失,引入了基于多尺度短时傅里叶变换(MS-STFT) 鉴别器的感知损失项
* lfeat:对抗中的生成器,评价了音频之间特征的差异,为生成器添加了相对特征匹配损失,
lw:VQ承诺损失,用于计算 zc 当前残差和 qc(zc) 相应码本中最近的条目的差异。
lr:另外,还训练一个小型 Transformer 语言模型(可选),用于使用在量化单元上进行熵编码,以进一步减少带宽。
3.5 损失函数的参数
引入了一个损失平衡器,平衡器可以更容易地推断出不同的损失权重,每个权重都可以解释为来自相应损失的模型梯度的分数。

















 3076
3076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









