






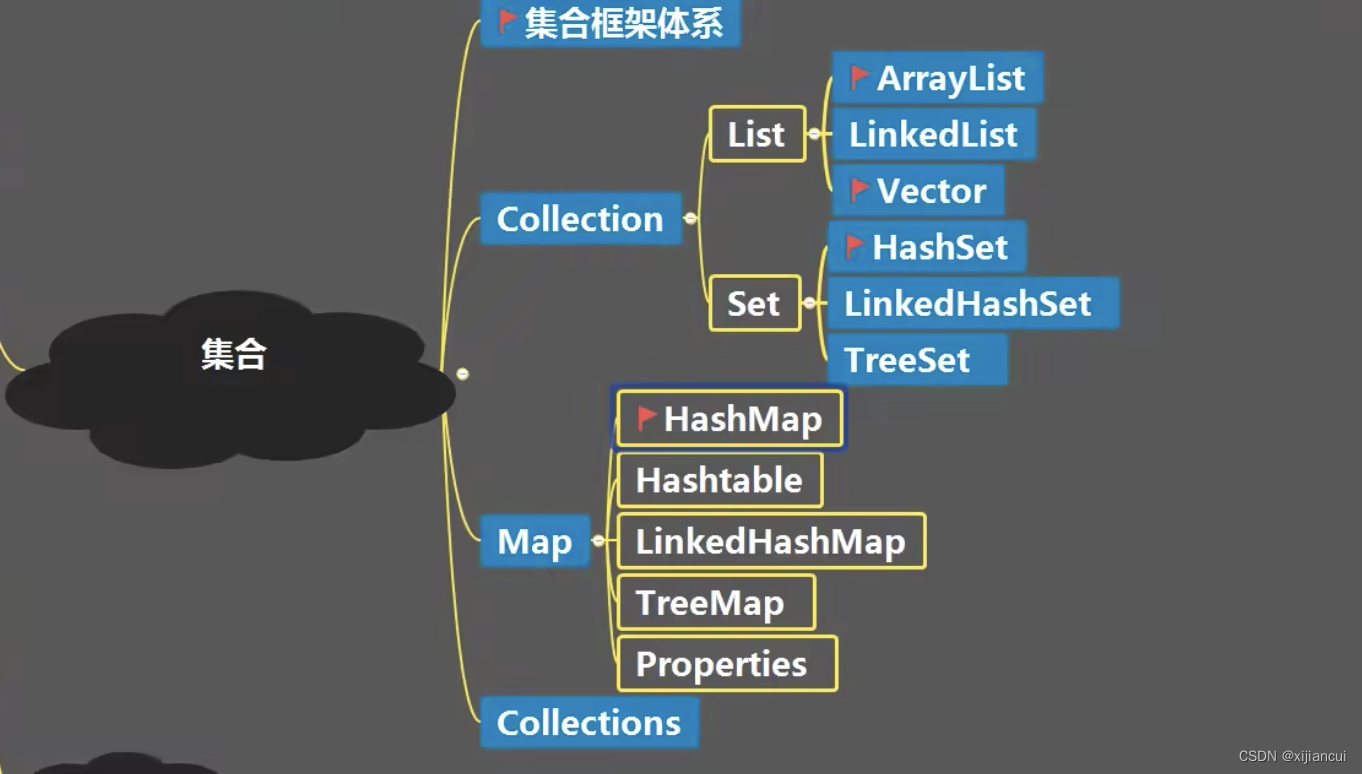
 本文详细介绍了Java中的Collection、List(如ArrayList、LinkedList)和Set(如HashSet、LinkedHashSet、TreeSet)接口,以及它们的子接口和实现类的特点、方法、遍历方式以及底层实现原理。重点讨论了添加、删除和扩容策略,以及如何选择合适的集合类型以优化程序性能。
本文详细介绍了Java中的Collection、List(如ArrayList、LinkedList)和Set(如HashSet、LinkedHashSet、TreeSet)接口,以及它们的子接口和实现类的特点、方法、遍历方式以及底层实现原理。重点讨论了添加、删除和扩容策略,以及如何选择合适的集合类型以优化程序性能。
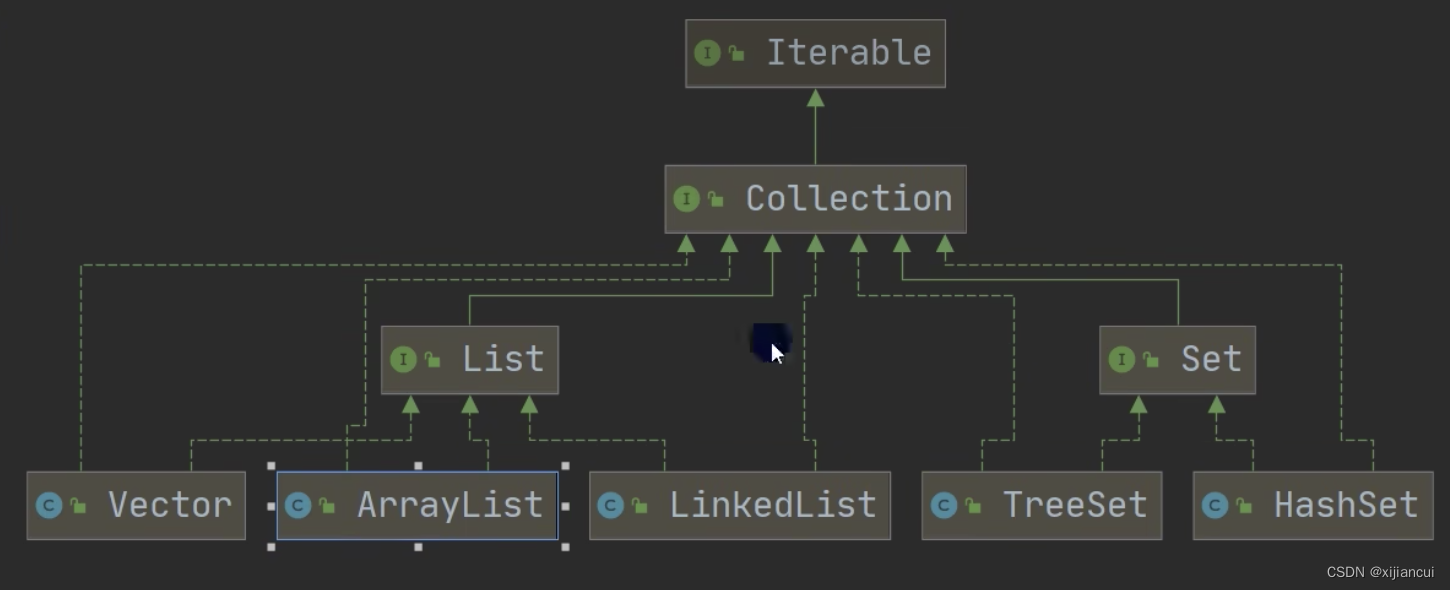
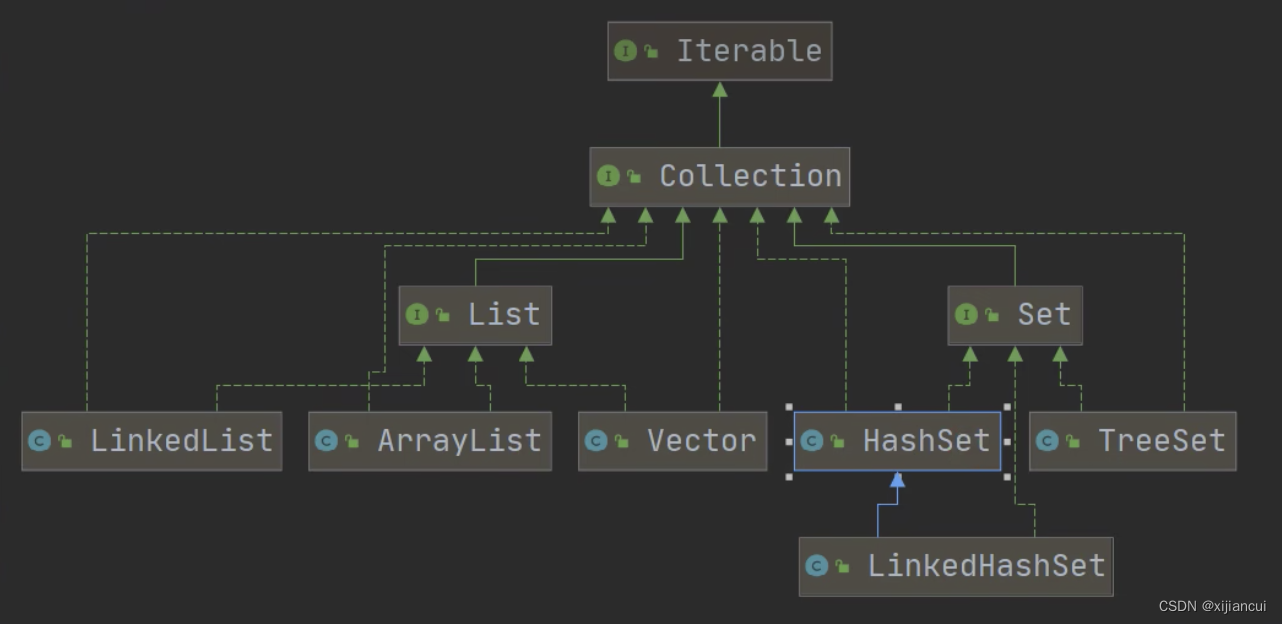
Collection 接口有两个重要的子接口 List Set,他们的实现子类都是单列接口;
Map 接口实现的子类是双列集合,存放键值对。
Collection 接口遍历方式
1、使用迭代器 Iterator 遍历
iterator 基本介绍
- Iterator 对象称为迭代器,主要用于遍历 Collection 集合中的元素。
- 所有实现了 Collection 接口的集合类都有一个 iterator() 方法,用以返回一个实现 iterator 接口的对象,即可以返回一个迭代器。
- iterator 仅用于遍历集合,iterator 本身并不存放对象。

iterator 基本使用
- 定义 ArrayList 并初始化。
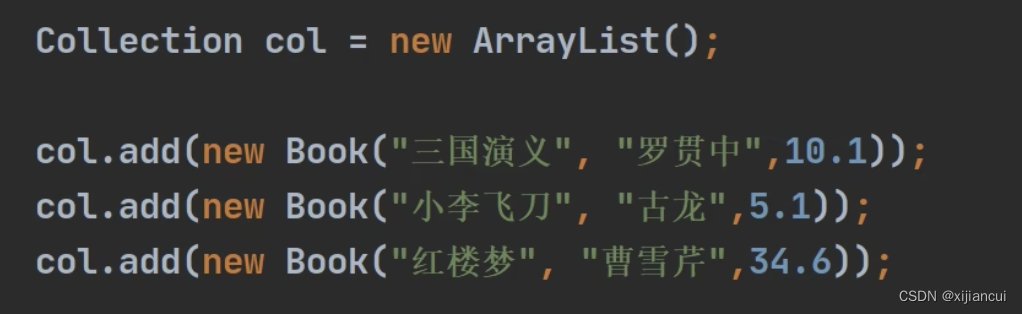
- 得到 col 对应的迭代器
-
Iterator iterator = col.iterator(); - 使用 while 循环 hasNext()、next() 方法。快捷键itit
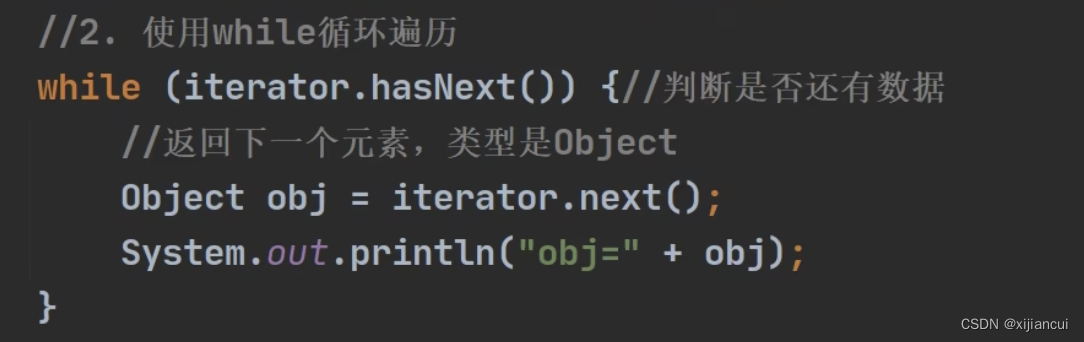
- 退出 while 循环时,iterator 指向集合最后一个元素。如果要重新遍历集合,需要重置 iterator 。

2、使用增强 for 循环
语法:for(元素类型 obj:集合名){
//循环体操作 obj
}
快捷键 I
解读:
增强for 底层仍然是迭代器,可以理解成简化版的迭代器。
List
List 接口特点:
- List 集合类中元素有序、且可重复
- List 集合中每个元素都有其对应的顺序索引,即支持索引
- 实现List 接口的常用实现类有Vector、ArrayList、LinkedList
List 接口常用方法
- void add(int index, Object ele); 在 index 位置插入 ele 元素;
- boolean addAll(int index, Collection eles); 从 index 位置开始将 eles 中的所有元素添加进来;
- Object get(int index); 获取指定 index 位置的元素;
- int indexOf(Object obj); 返回 obj 在当前集合中首次出现的位置;
- int lastIndexOf(Object obj); 返回 obj 在当前集合中末次出现的位置;
- Object remove(int index); 移除指定 index 位置的元素,并返回此元素;
- Object set(int index, Object ele); 设置指定 index 位置的元素 ele;
- List subList(int fromIndex, int toIndex); 返回 [ fromIndex,toIndex ) 位置的子集合。
ArrayList 底层结构和源码分析
ArrayList 特点
- ArrayList 允许存放所有类型的元素,包括空 null,且可以有多个。
- ArrayList 底层是由数组来实现数据存储的。
- ArrayList 基本等同于 Vector ,但 ArrayList 线程不安全,没有加 synchronized 修饰,效率高。
ArrayList 源码
记住结论
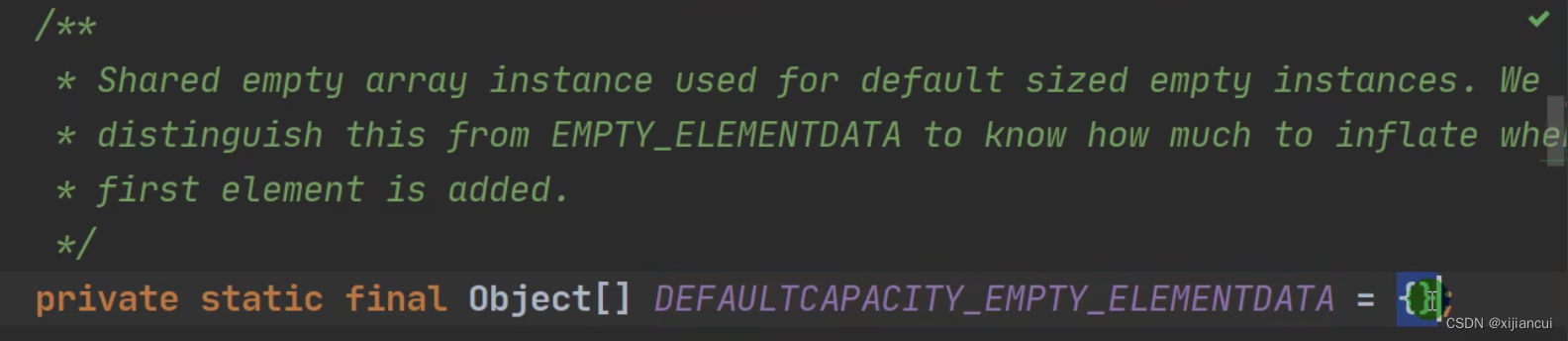
1、ArrayList 中有一个 Object 类型的数组 elementData 属性。
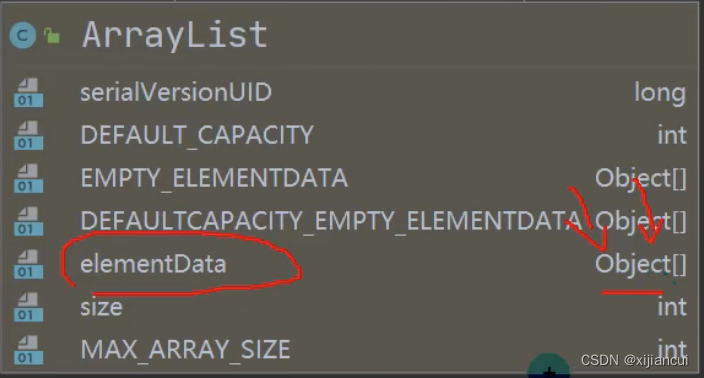
2、当创建 ArrayList 对象时,如果使用的是无参构造器 ArrayList( ),则初始 elementData 容量为0。第一次添加,则扩容 elementData 为10;如果要再次扩容,则扩容 elementData 为1.5 倍。
3、如果使用的是指定大小的构造器,则初始 elementData 容量为指定大小;如果需要扩容,则直接扩容 elementData 为1.5 倍。
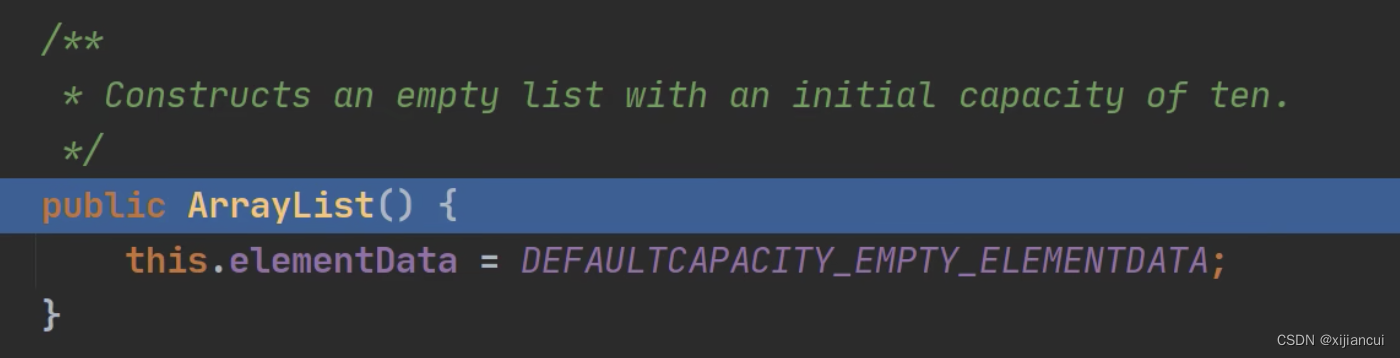
分析下面这段源码——无参构造器
1、创建了一个空的 elementData 数组。
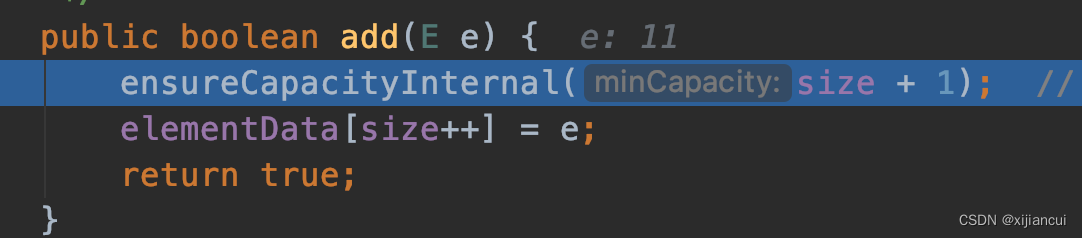


5、调用 ensureExplictCapacity 方法
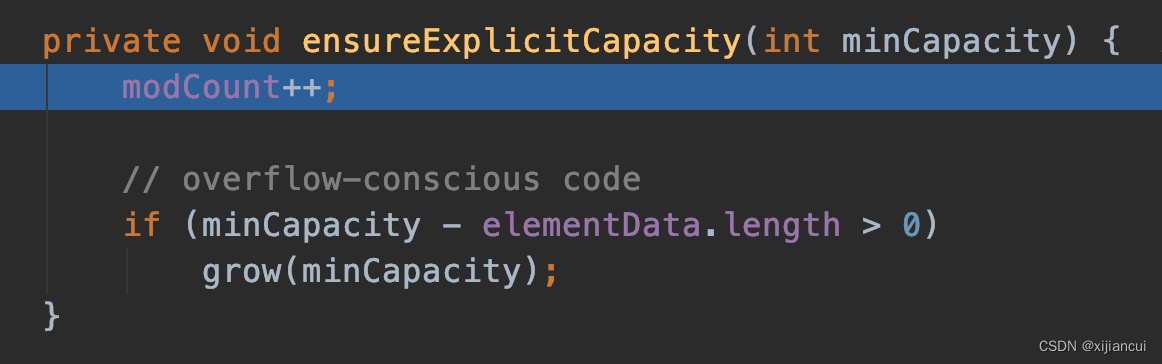
第一次扩容时,minCapacity=10,elementData.length = 0;满足 if 语句,调用 grow 方法
6、调用 grow 方法
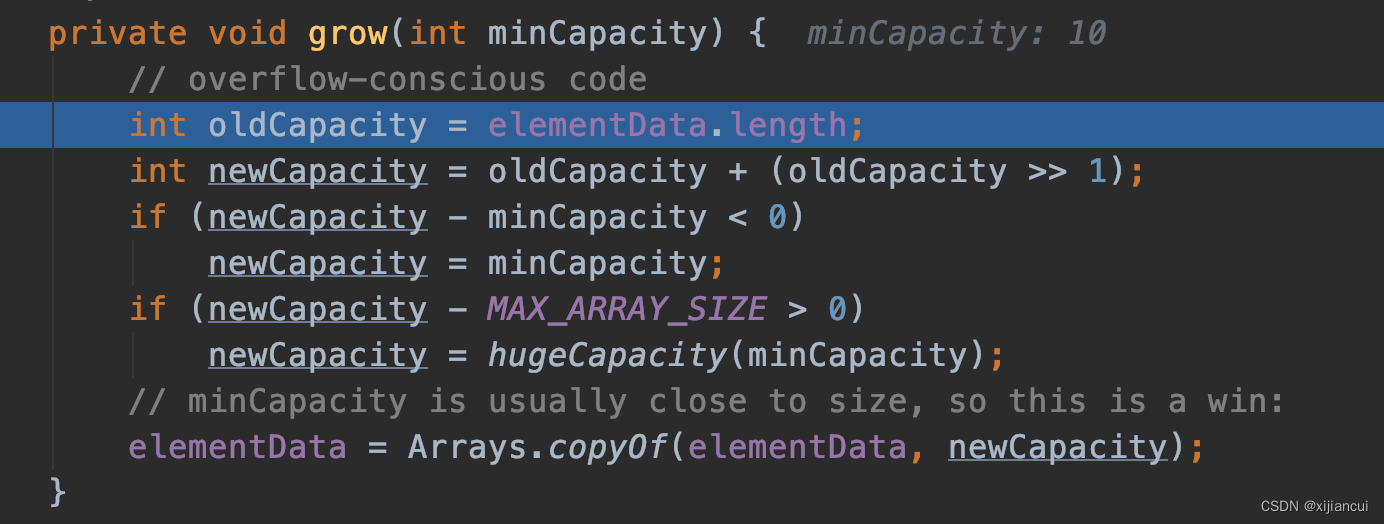
新容量变为原来容量的 1.5 倍
int newCapacity = oldCapacity + (oldCapacity >> 1); //新容量变为原来容量的 1.5 倍第一次扩容时,newCaoacity = 0+0/2=0,瞒住 if ,newCapacity 为10
if (newCapacity - minCapacity < 0) //第一次扩容时,newCaoacity = 0+0/2=0
newCapacity = minCapacity; //新容量赋为 10;elementData = Arrays.copyOf(elementData, newCapacity);ArrayList 底层使用 Arrays 的 copyOf 方法给数组扩容。实际就是开辟一个大小为 newCapacity 的数组空间,再把elementData 的元素复制到新数组,剩余空间置空。
Vector 源码
Vector 和 ArrayList 比较

LinkedList 源码
LinkedList 基本介绍
- LinkedList 底层实现了双向链表和双端队列;
- LinkedList 可以添加任意元素,包括 null ;
- LinkedList 线程不安全。
LinkedList 底层操作机制
- LinkedList 底层维护一个双向链表,元素结点 Node 维护一个 prev 和一个 next 指针。

- LinkedList 中维护两个属性 first 和 last 分别指向首节点和尾节点。
ArrayList 和 LinkedList 比较
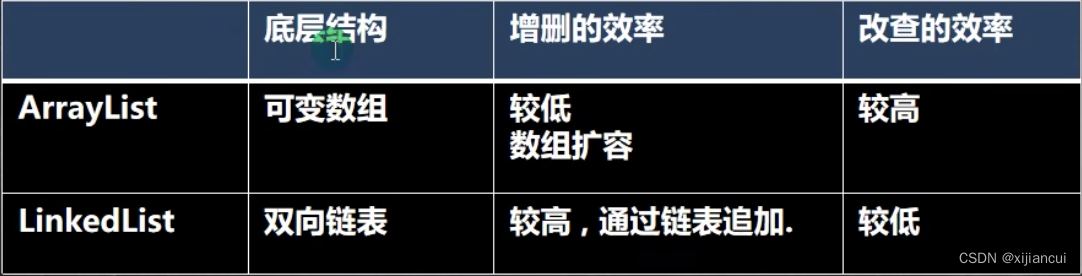
- 如果改查操作多,选择 ArrayList;
- 如果增删操作多,选择 LinkedList;
- 一般来说,在程序中,80%~90%都是查询,因此大部分情况下会选用 ArrayList。
Set 接口
Set 接口基本介绍
- 元素无序,添加和取出的顺序不一致,没有索引;
- 不允许重复元素,所以最多包含一个 null;
- JDK API中 Set 接口的实现类有 TreeSet、HashSet
Set 接口的常用方法
Set 接口的遍历方式
- 可以使用迭代器;
- 增强 for 循环
- 不能使用索引的方式获取;
HashSet
特点:
- HashSet 实现了 Set 接口;
- HashSet 底层是 HashMap,HashMap 底层是 数组+链表+红黑树;

HashSet 构造器 - HashSet 可以存放 null 值,但是只能有一个null;
- HashSet 不保证元素是有序的,取决于 hash 后确定的索引值;
- HashSet 不能存放重复的元素/对象。存放重复元素会返回 false;
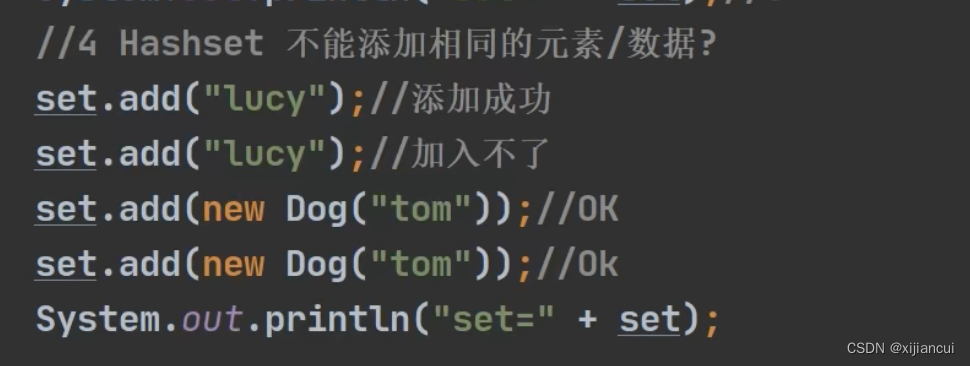
但有一个易错点

HashSet 添加元素底层机制
1、HashSet 底层是 HashMap,数据结构是一个邻接表;
2、添加一个元素时,先得到 hash 值(hashCode 方法);
3、找到存储数据表的 table ,看这个索引位置是否已经存放有元素;
4、如果没有,直接加入;如果有调用 equals 方法比较(程序员确定)。
5、如果相同,就放弃添加;如果不相同,则添加到链表最后;
6、在java8 中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认为8),并且 table 的大小 >= NIM_TREEIFY_CAPACITY( 默认为64 ),就会进化成红黑树。
HashSet 扩容底层机制
1、HashSet 底层是 HashMap,第一次添加时,table 数组扩容到 16。(临界值threshold) = (16*加载因子loadFactor) = (16*0.75)=12
2、如果临界表中存放元素个数达到临界值 12 ,就会扩容。扩容到大小为 16*2 = 32,新的临界值为 32*0.75 = 24;
下次使用到24个,继续扩容到64,临界值48 ,以此类推。
3、在 java 8 zhong ,如果一条链表元素个数达到 TREEIFY_THRESHOLD(默认是8),并且 table 大小 >= MIN_TREEIFY_CAPACITY(默认为64),就会进行树化(红黑树),否则仍然采用数组扩容机制。
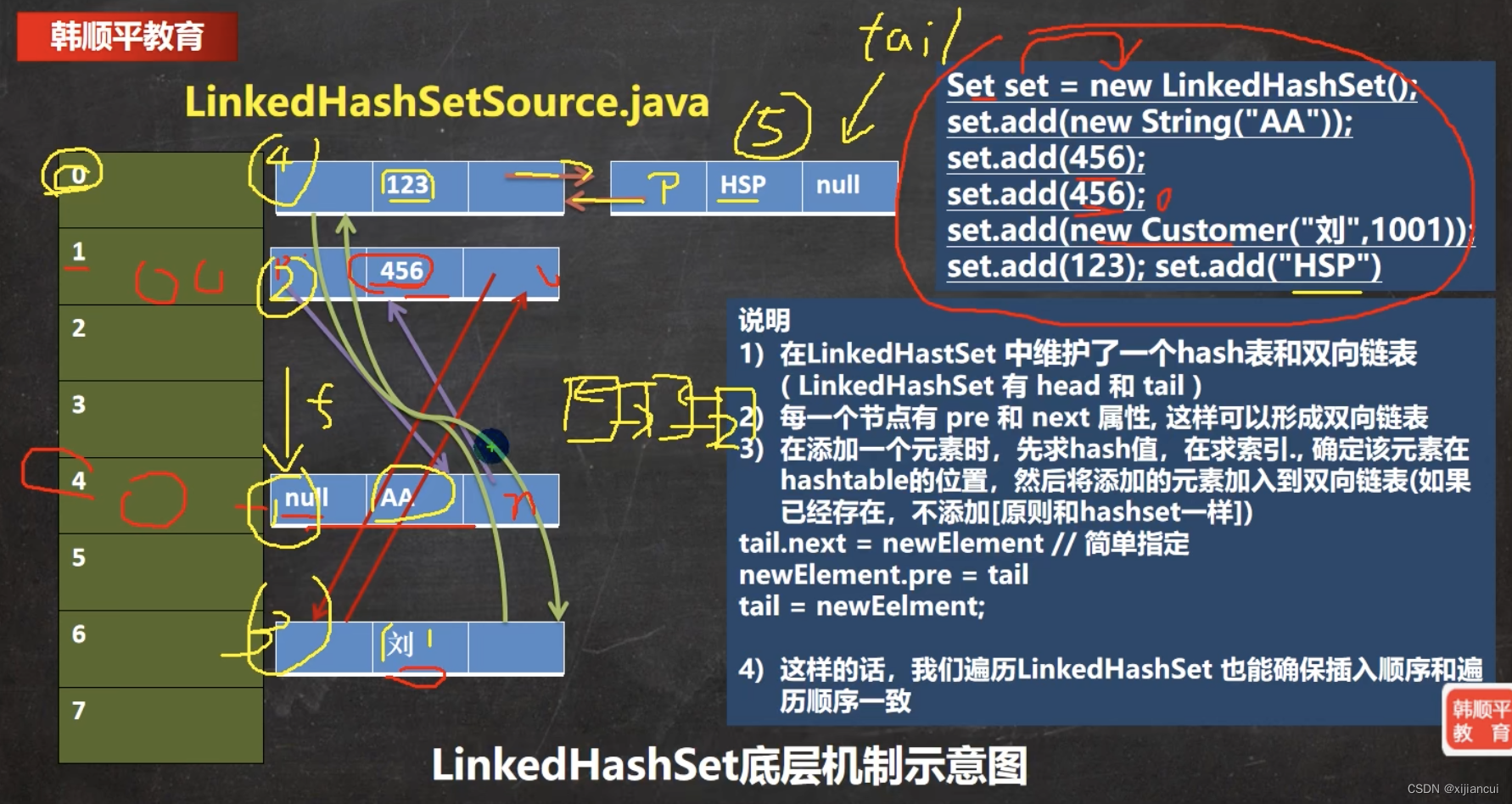
LinkedHashSet
LinkedHashSet 继承关系
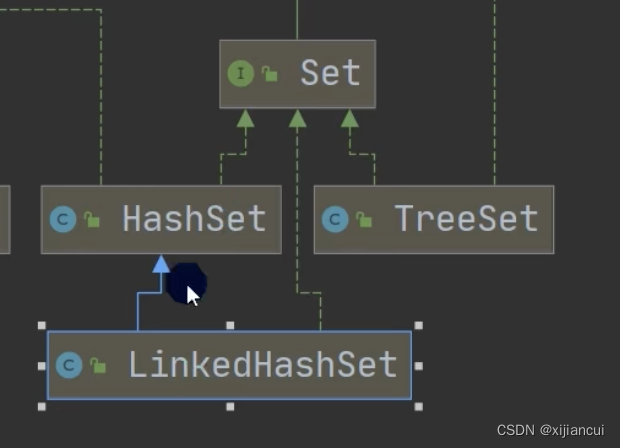
LinkedHashSet 基本介绍
- LinkedHashSet 是 HashSet 的子类;
- LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个hash表+双向链表;
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
- LinkedHashSet 不允许添加重复元素。
双向链表保存元素插入顺序

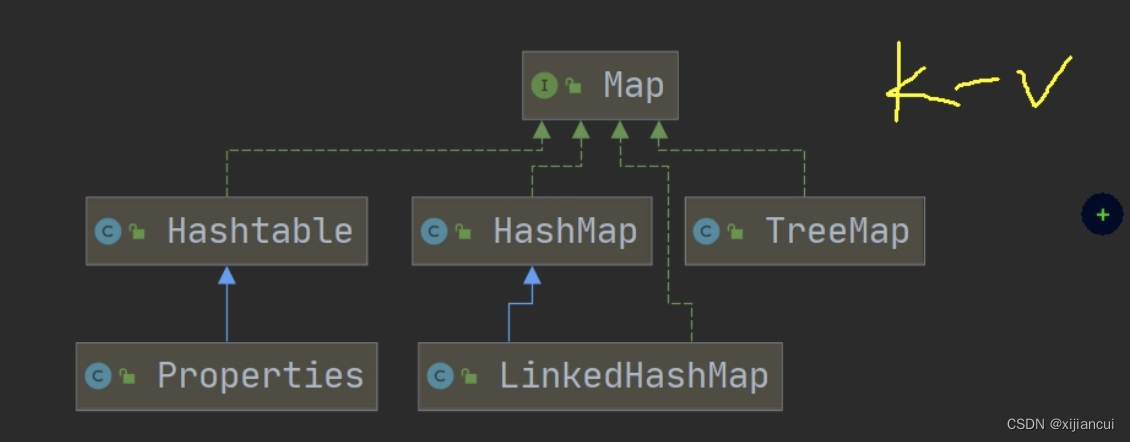
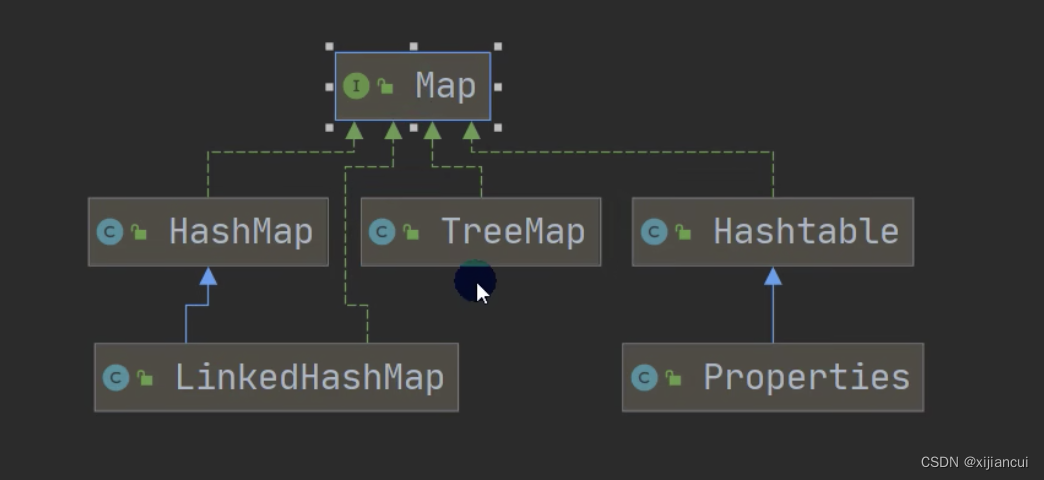
Map
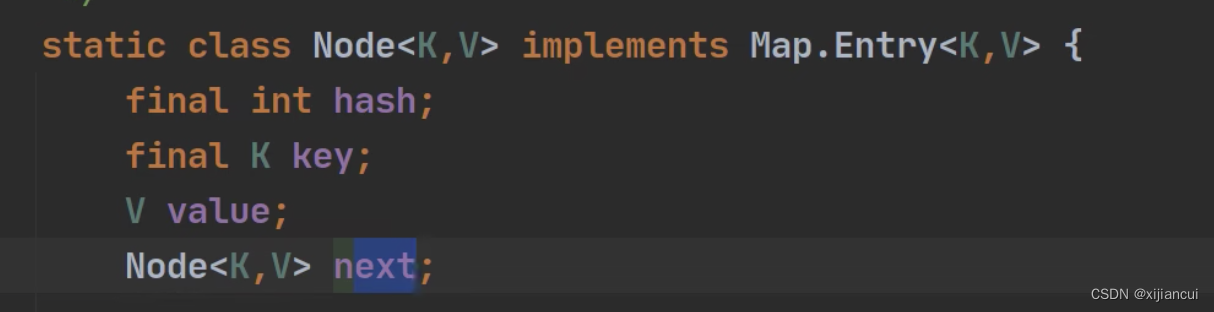
Map 接口特点
1、Map 用于保存具有映射关系的数据 key-Value (双列元素);
2、Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中;
3、Map 中的 key 值不能重复,出现的重复 key 会替换之前的;
4、Map 中的 Value 可以重复;
5、Map 中 key 可以为空,但只能有一个; Value 可以为空,可以有多个;
6、常用 String 类作为 Map 的 key;
7、Key 和 value 之间存在单向一一对应的关系 ,即通过指定的 Key 总能找到对应的 Value 值。
8、Map 存放数据的 Key-Value ,一对 k-v 是放在一个 HashMap$Node 中的,Node 实现了 Entry 接口。
Map 接口的常用方法
1、put ( k ,v ) 添加
2、remove ( k )根据键删除映射关系
3、get ( k ) 根据键获取 v
4、size 获取当前键值对数
5、containsKey ( k ) 查找键是否存在
6、clear 清空
7、isEmpty 判断个数是否为 0
Map 接口遍历的六种方式
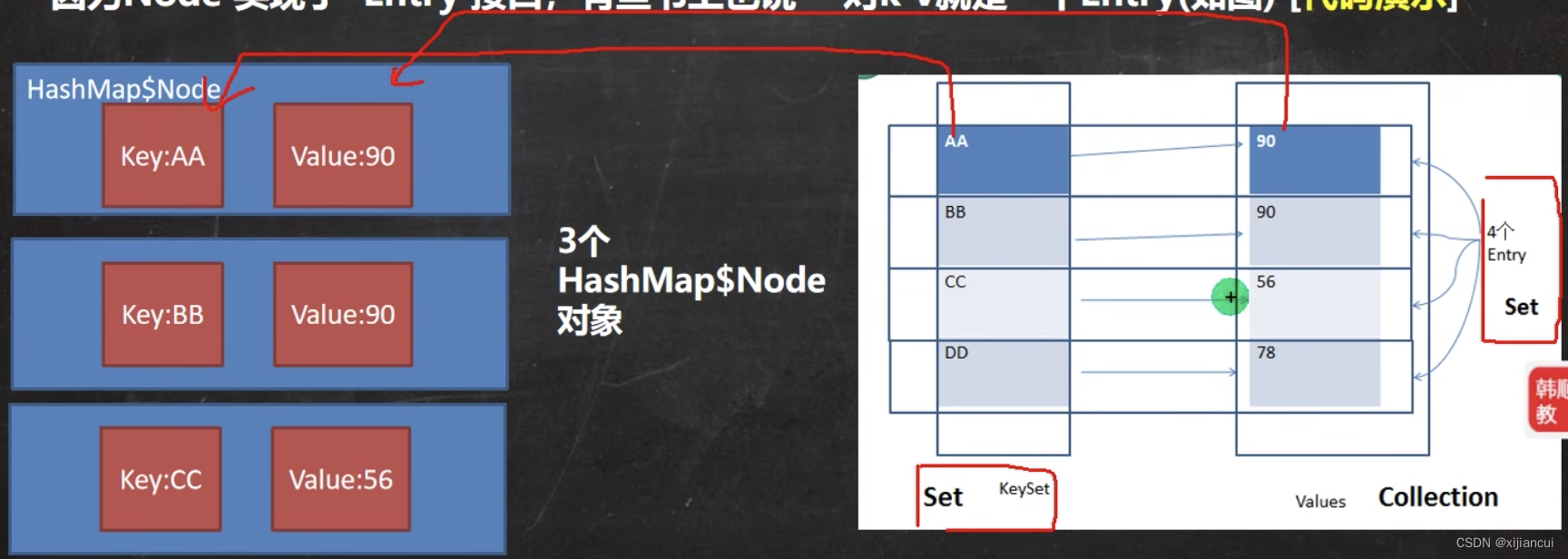
为了方便遍历,key值会构建一个 Set ,Value 值也会构建一个 Set。
方法
1、containsKey 查找键是否存在
2、keySet 获取所有的键
3、values 获取所有的值
4、entrySet 获取所有的键值对 k-v
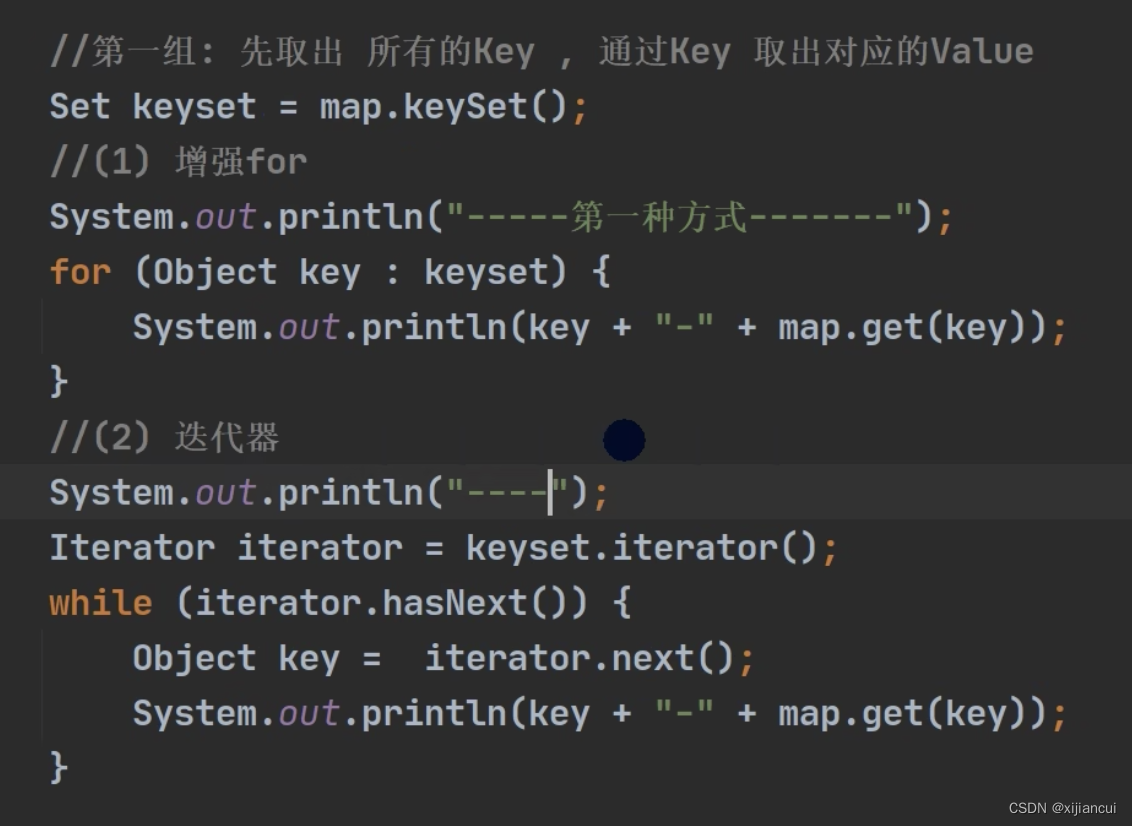
方式一:先用keySet 方法,获得 Set 接口对象取出所有的 key ,再通过 Key 用 get 方法取出对应的 Value。
实际上,就是转换成立遍历 Set 。 对 keySet 可以用增强 for 和迭代器 两种方式遍历。
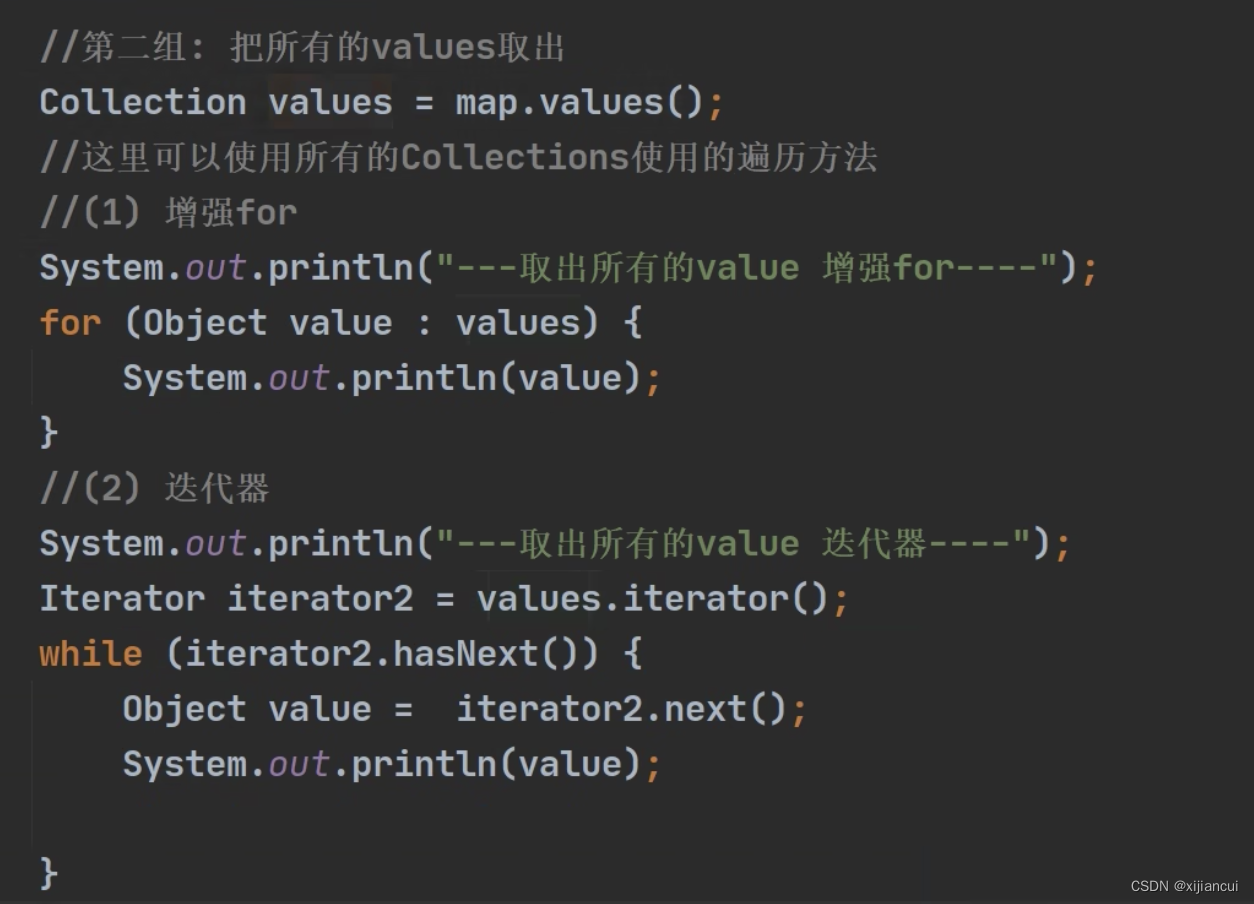
方式二:用values 方法把值全部取出,获得的是 Collection 对象
对集合 Collection 的遍历,可以用1、增强for ; 2、迭代器;
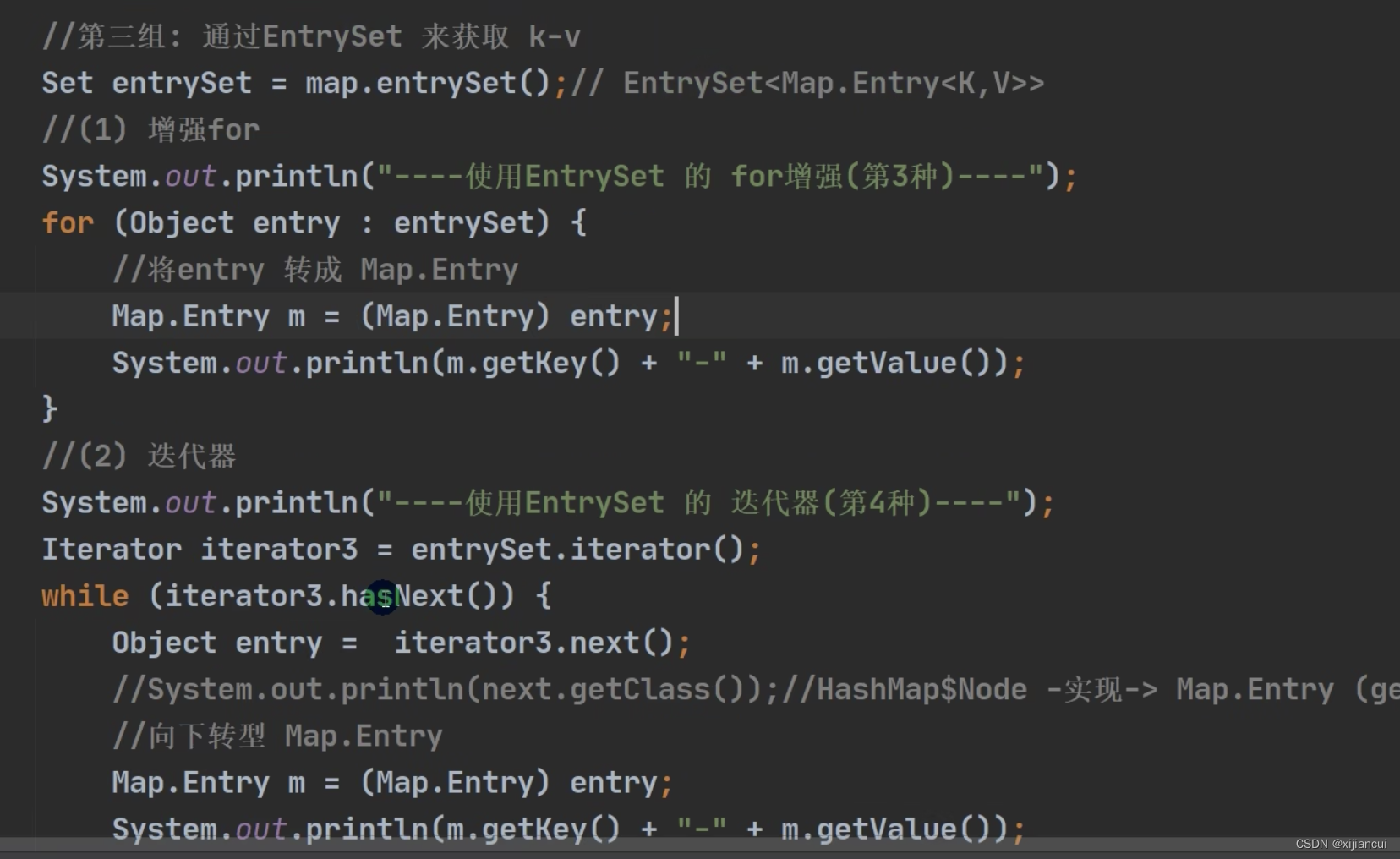
方式三:通过 entrySet 获取 k-v 。entrySet 的元素类型为 Map.Entry 提供 getkey 和 getValue 方法。
HashMap 小结
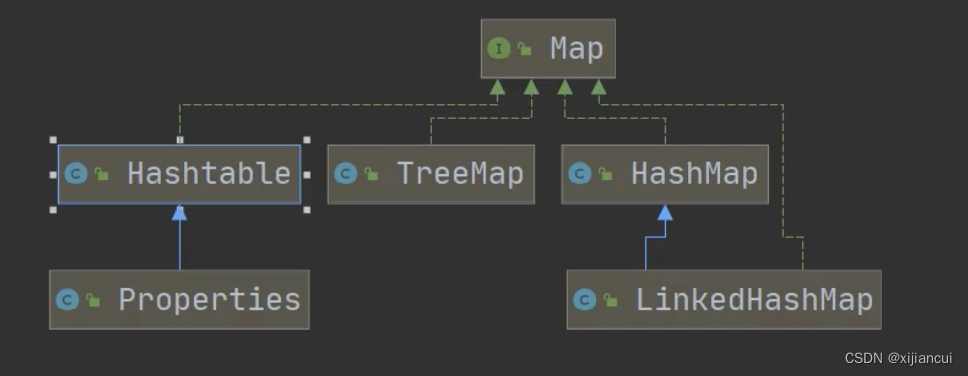
1、Map 接口的常用实现类:HashMap、HashTable、Properties;
2、hashMap 是 Map 接口使用评率最高的实现类;
3、与 hashSet 一样,不保证映射的顺序,因为底层是 hash 表的方式存储的
4、HashMap 不保证线程互斥,没有实现同步
5、如果添加重复的 key 值,则会覆盖原来的 key-value ,等同于修改。但 key 不会替换,只替换 value
Hashtable
Hashtable 基本介绍
1、存放的元素是键值对
2、hashtable 的键和值都不能为 null,否则会抛NullPointer 异常
3、Hashtable 的使用方法基本上和 HashMap 一样
4、Hashtable 是线程安全的,HashMap是线程不安全的
Hashtable 底层
1、Hashtable 底层有一个数组 Hashtable$Entry[] ,初始化大小为 11;
2、临界值 threshold = 8 = 11*0.75;
3、扩容:按照自己的扩容机制 2n +1;
4、执行 addEntry ( hash, key, value, next);
HashMap 和 Hashtable 比较

Properties
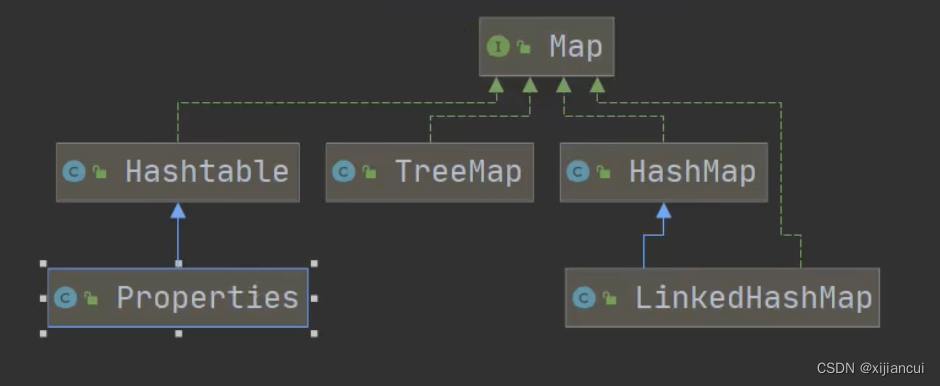
基本介绍
1、Properties 类继承自 Hashtable 类,并实现了 Map 接口,也使用键值对的形式来保存数据;键和值都不能为 null;
2、Properties 的使用特点和 Hashtable 类似;
3、Properties 还可以用于从 xxx.properties 文件中,加载数据到 Properties 类对象,并进行读取和修改
4、xxx.Properties 文件通常作为配置文件
java 开发中集合的选择

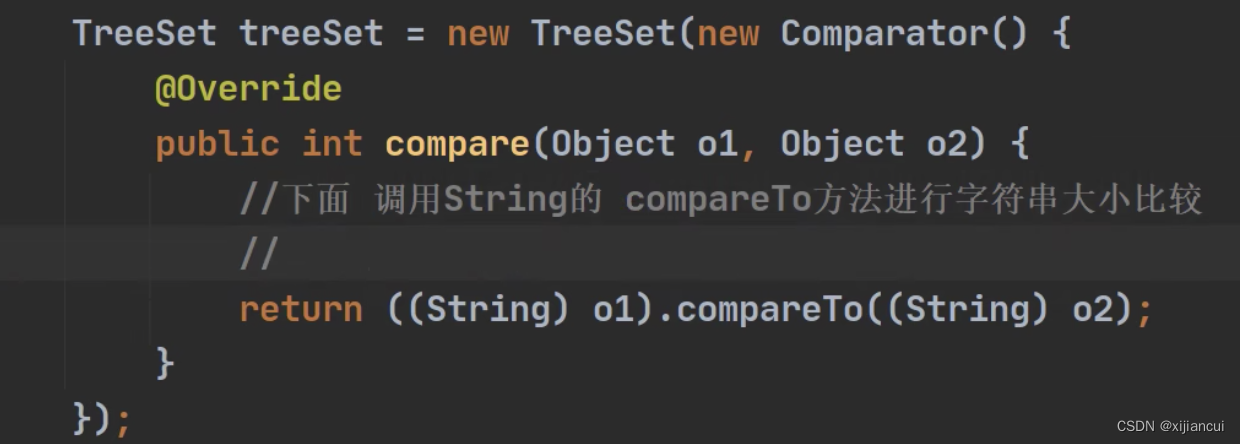
TreeSet
TreeSet 实现排序
1、当使用无参构造器创建 TreeSet 时,仍然是无序的;
2、当希望添加的元素,按照字符串大小来排序时,使用 TreeSet 提供的一个构造器。
3、传入一个比较器 comparetor (匿名内部类),重写 compare 方法设置排序规则;

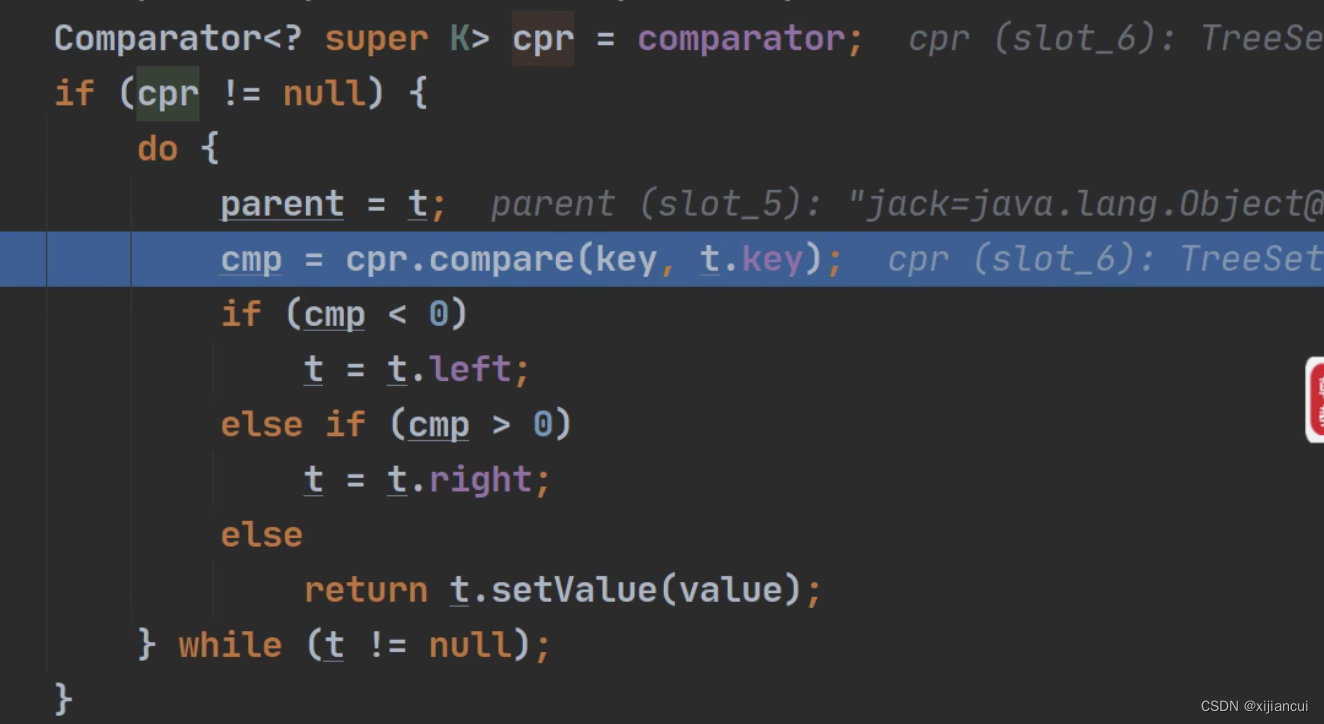
TreeSet 的底层是 TreeMap,构造器把传入的比较器对象赋给 TreeMap 的 comparator 属性

加入数据时,put 方法里会进行
1、cpr 就是我们传入的匿名内部类对象
2、调用匿名内部类重写的 compare 方法 得到一个数值,根据其正负性进行加入链接操作。
TreeMap
Collections 工具类
基本介绍
1、Collections 是一个操作Set、List、Map 等集合的工具类;
2、Collections 中提供了一系列的静态方法对集合元素进行排序、查询和修改等操作。
常用方法
- reverse(List) :反转 List 中元素的顺序;
- shuffle( List ):对 List 集合元素进行随机排序;
- sort(List ):根据原始的自然顺序对指定的 List 集合按升序排序;
- sort(List, Comparator):根据指定的 Comparator 产生的顺序对 List 的元素进行排序;
- swap(List, int ,int):将指定的 List 集合中 i 处元素和 j 处元素进行交换。
- max(List) :根据元素的自然顺序返回给定集合的最大元素
- max(List, Comparator):根据 Comparator 指定的顺序,返回给定集合的最大值
- min(List );
- min(List, Comparator)
- frequency( List , obj):返回指定集合中指定元素出现的次数
- copy(List des, List src):将 src 中的内容复制到 des
分析 HashSet 和 TreeSet 分别如何实现去重
(1)HashSet 的去重机制:
hashCode() + equals() ,底层先通过存入对象进行运算得到一个 hash 值,通过 hash 值得到对应的索引,如果发现 table 索引所在的位置没有数据,就直接存放;如果有数据就进行 equals 比较(遍历链表比较);如果比较后不相同,则加入;否则不加入。
(2)TreeSet 的去重机制:
如果传入一个 Comparator 匿名内部类对象,就使用实现的 compare 方法比较对象。如果方法返回 0,就认为是相同的元素,不添加。
如果没有传入 Comparator 比较器,则默认使用传入对象实现的 Compareable 接口的 CompareTo 方法去重。
因此,需要注意,如果要用 TreeSet 存对象,加入时底层会执行 Comparable k = (Comparable) key; 即尝试把该对象向上转型成 Comparable 对象,所以该对象必须实现了 Compareable 接口。否则会报 ClassCastException 。















 3189
3189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









