







 博客记录了一次由于YARN集群启动错误导致MR Job无法提交的问题。问题表现为resourcemanager未正常启动,进而阻塞了任务执行。解决方法是重新正确启动YARN集群,问题随即得到解决。
博客记录了一次由于YARN集群启动错误导致MR Job无法提交的问题。问题表现为resourcemanager未正常启动,进而阻塞了任务执行。解决方法是重新正确启动YARN集群,问题随即得到解决。
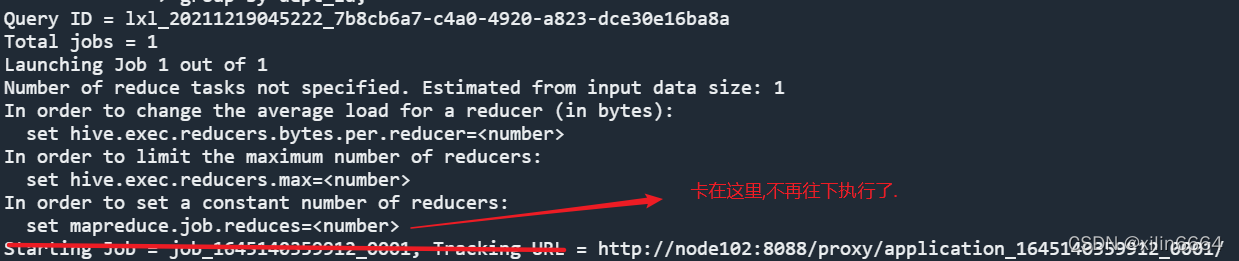
后来经过排查是由于,yarn集群启动不正确造成的.yarn的resourcemanager没有正确启动造成mr的job 不能正确提交导致卡住,不再往下执行.
解决:重新正确启动yarn集群然后.问题解决了,特此记录.
后来经过排查是由于,yarn集群启动不正确造成的.yarn的resourcemanager没有正确启动造成mr的job 不能正确提交导致卡住,不再往下执行.
解决:重新正确启动yarn集群然后.问题解决了,特此记录.

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 2936
2936





