







一、研究背景
弱监督学习在计算机视觉领域中是一个至关重要的任务。因为在视觉应用场景中,难以获取大量的clean label(需要经过人验证),但是我们可以通过一些预训练好的model去获得大量的noisy label(不精确或有错误)。所以如何利用大量noisy label数据去提高model的准确度和鲁棒性就显得十分重要。
当前在图像分类领域的弱监督学习方法大都会对noisy label的类型有一定的假设,即single-label noise或multi-label noise。单标签噪声可以在训练过程中引入类似聚类相似图像的方法[14],而多标签噪声可以使用标签与标签的关系来使算法更健壮[33](如下图)。这些方法虽然可以提高model的表现,但是单标签噪声学习方法不适用于多标签噪声的问题,多标签噪声的方法在单标签数据集上的效果未知。也就是在single-label和multi-label之间存在gap。

大多数弱监督图像分类方法试图只通过带有noisy label的数据去进行学习。主要为以下两类:
1、从全部的数据中去分辨出噪声数据,这些方法一般将焦点集中于去发现噪声数据和clean数据的不同。
2、从损失函数和网络结构上去实现noise robust learning。
本文的方法属于另一个支流,在有少量clean label已知的情况下。此类方法旨在利用带有少量的clean label的大量noisy label数据来学习鲁棒性强的图像分类器。与仅从带有noisy label的数据中学习相比,clean label可以在某种程度上将模型导向正确的方向。 此类方法的实验结果表明,即使是少量带有clean label的数据也对性能改善有积极的影响。本文的方法通过利用带有noisy label的数据去减少model对clean label数据的过拟合,以此来提高model的泛化能力。
除此之外一些研究还介绍了辅助信息(例如,知识图)以帮助提高模型对噪声标签的鲁棒性。但是,辅助信息有时与标签数据高度相关,这在某种程度上也限制了模型的泛化能力。
二、研究动机
利用大量的noisy label数据和少量的clean label数据(5%左右),去实现一个鲁棒性强的图片分类算法。
两个目的:
1、利用大量noisy label数据去增强分类算法的鲁棒性;
2、能在单类别和多类别分类问题中都有效果。
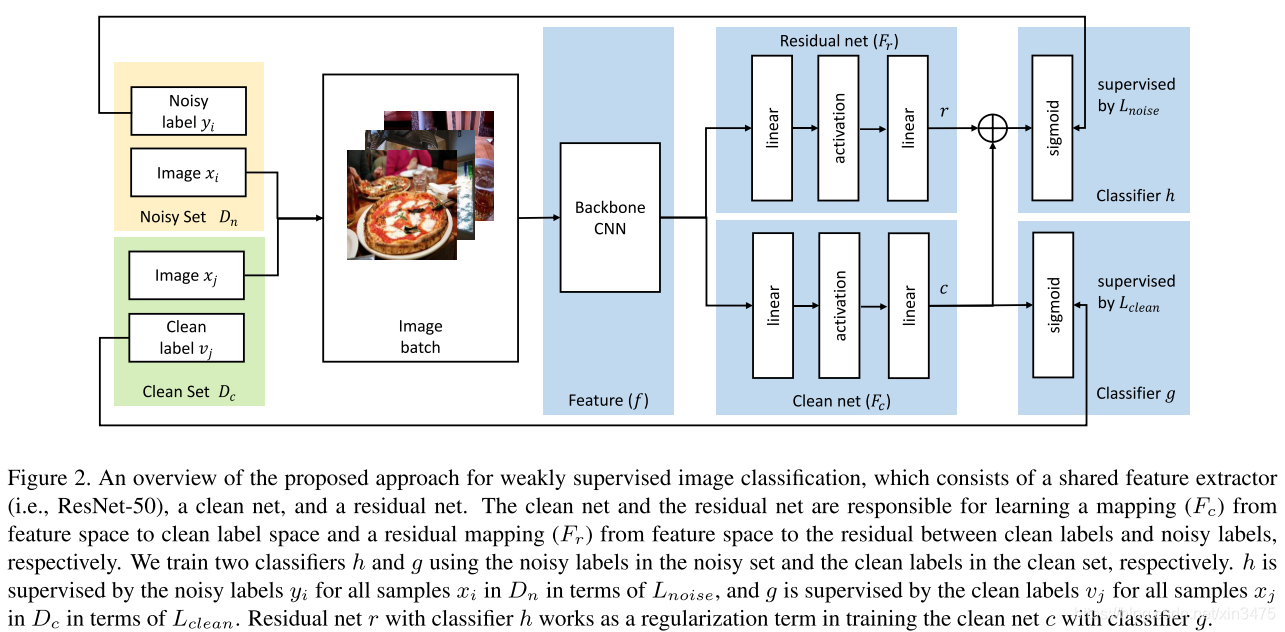
三、实现方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









