






元素定位
可参考官方文档:https://www.selenium.dev/zh-cn/documentation/webdriver/elements/finders/
ID定位
HTML 标签 的 id 属性值是唯一的,故不存在根据 id 定位多个元素的情况。
driver.find_element(By.ID,value)
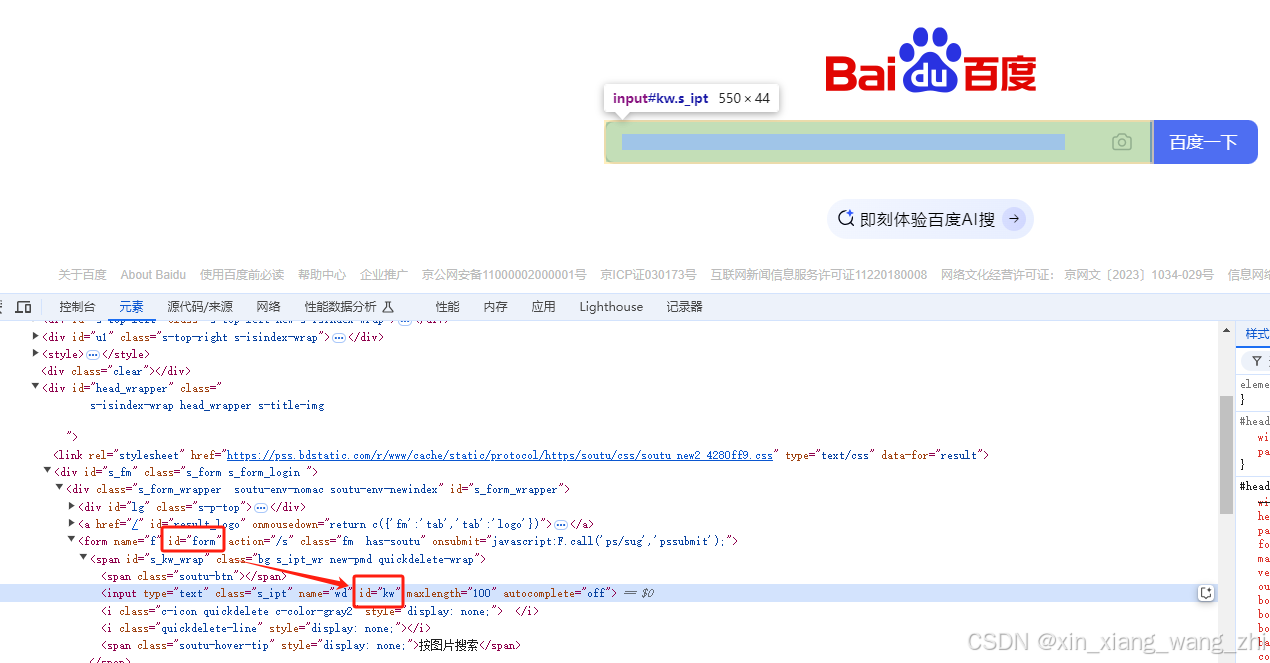
如下图定位百度搜索框:
element = driver.find_element(By.ID,”kw”)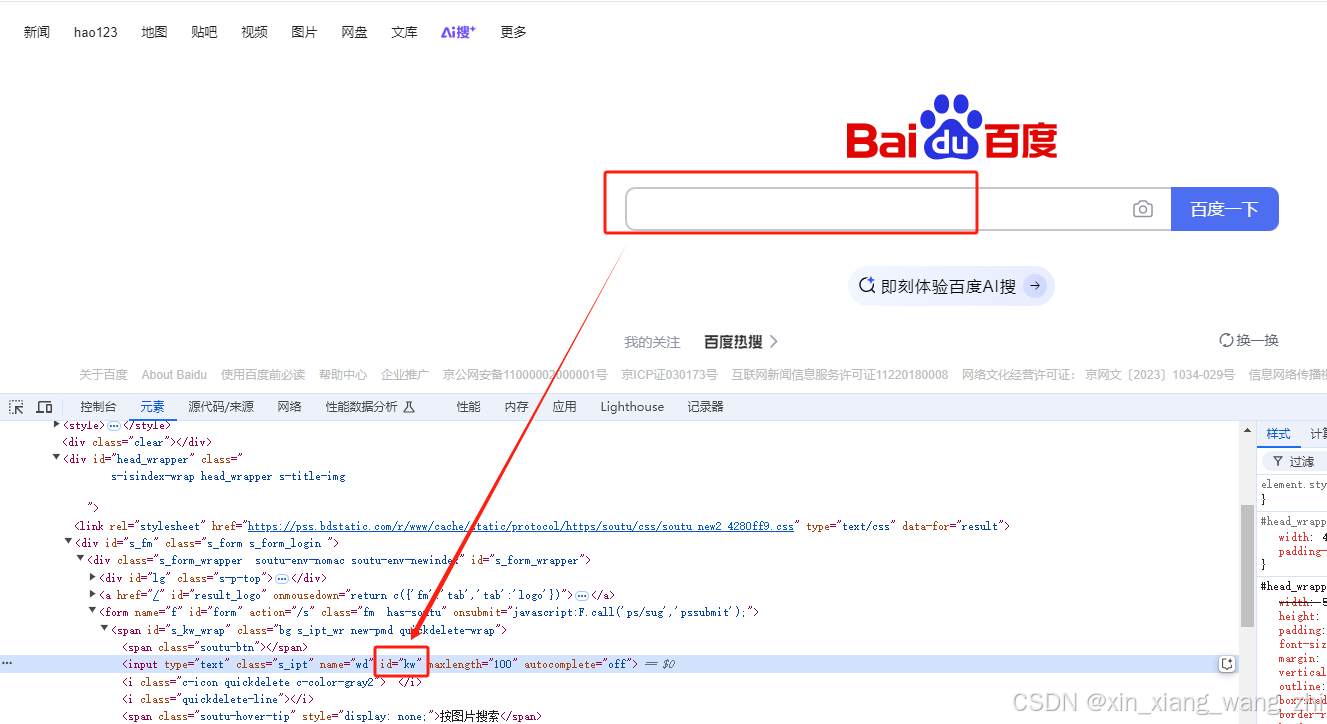
name 定位
在HTML当中,name属性和id属性的功能基本相同,只是name属性并不是唯一的,如果遇到没有id标签的时候,我们可以考虑通过name标签来进行定位。
driver.find_element(By.NAME,value)
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位:
element = driver.find_element(By.NAME,”wd”)class 定位
基于class属性来定位元素。
driver.find_element(By.CLASS_NAME,value)
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位:
element = driver.find_element(By.CLASS_NAME,”s_ipt”)注意:若class的值中有空格,则需要借助CSS Selector处理。
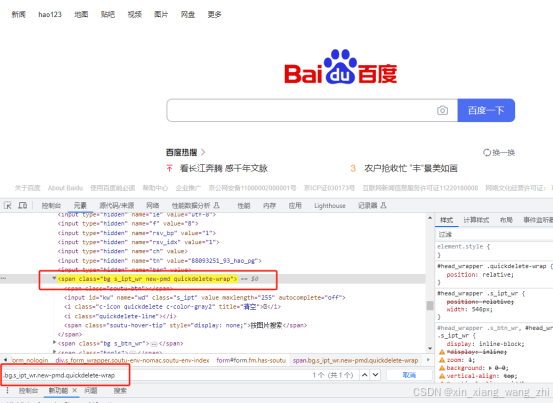
tag_name 定位
HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag(标签),由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。
driver.find_element(By.TAG_NAME,value)
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位:
element = driver.find_element(By.TAG_NAME,”input”)link_text 定位
通过超链接的文本定位元素。
element = self.driver.find_element(By.LINK_TEXT,value)
百度上方超链接”新闻“元素如图所示:
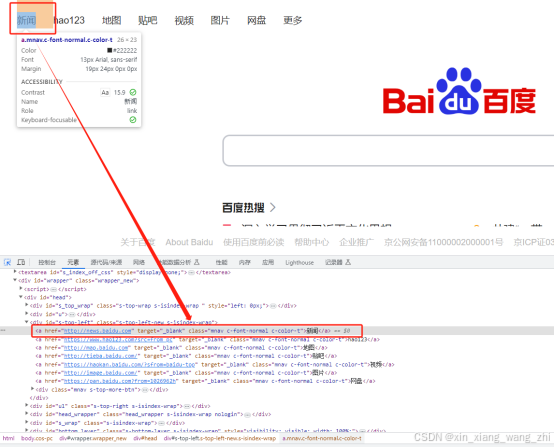
百度新闻元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>
元素定位:
element = driver.find_element(By.LINK_TEXT, ”新闻”)partial_link_text 定位
当超链接的文本过长时,可以只截取一部分字符串,进行模糊匹配。
driver.find_element(By.PARTIAL_LINK_TEXT,value)
百度新闻元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>
元素定位:
element = driver.find_element(By.PARTIAL_LINK_TEXT, ”新”)CSS 定位
CSS 定位的优点是速度快、语法简洁。
driver.find_element(By.CSS_SELECTOR,value)
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位:
1、以class选择器为例: . 加 class属性实现CSS定位
element = driver.find_element(By.CSS_SELECTOR, ”.s_ipt”)2、class中有空值,空格换成”.”
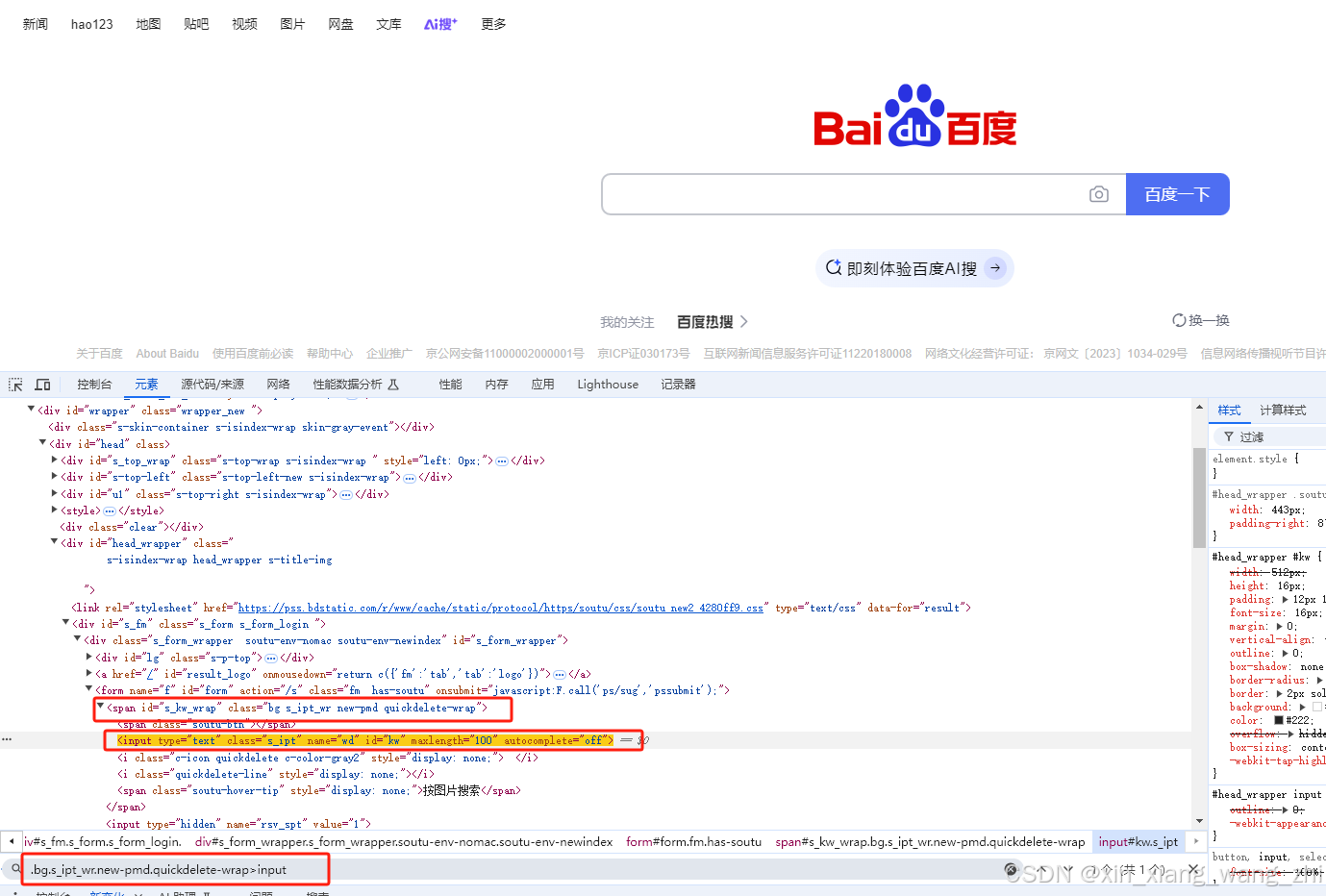
element=driver.find_element(By.CSS_SELECTOR, '.bg.s_ipt_wr.new-pmd.quickdelete-wrap>input')3、以id定位语法结构为:#加 id 名,实现CSS定位
element = driver.find_element(By.CSS_SELECTOR, ”#kw”)4、CSS 定位主要利用属性 class 和 id 进行元素定位。也可以利用常规的标签名称来定位,如输入框标签“input”,在标签内部又设置了属性值为“name=’wd’”
element = driver.find_element(By.CSS_SELECTOR, "input[name='wd']")5、CSS 定位方式可以使用元素在页面布局中的绝对路径来实现元素定位。百度首页搜索输入框元素的绝对路径为“html>body>div>div>div>div>div>form>span>input[name="wd"]”
element=driver.find_element(By.CSS_SELECTOR, 'html>body>div>div>div>div>div>form>span>input[name="wd"]')6、CSS 定位也可以使用元素在页面布局中的相对路径来实现元素定位。
element = driver.find_element(By.CSS_SELECTOR, "//*[@id="kw"]")7、多个值
driver.find_element(By.CSS_SELECTOR, '#form #id')CSS 定位的选择器有十几种,这里主要介绍几种比较常用的选择器。其余查看W3School 的 CSS 参考手册:https://www.w3cschool.cn/cssref/53s812dp.html
XPath 定位
对比较难以定位的元素,一般都通过 XPath 来定位元素。
XPath 是一门在 XML 文档中查找信息的语言。它在 XML 文档中通过元素名和属性寻找节点。
XPath定位比 CSS 定位有更大的灵活性。XPath 可以向前搜索也可以向后搜索,而 CSS 定位只能向后搜索,但是 XPath 定位的速度比 CSS 慢一些。
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
driver.find_element(By.XPATH, value)
节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
文档(根)节点:<bookstore>
元素:<book>、<author>
属性:lang="en"
文本:2005、29.99
节点关系
举例:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
父:book 元素是 title、author、year 以及 price 元素的父
子:title、author、year 以及 price 元素都是 book 元素的子
同胞:title、author、year 以及 price 元素都是同胞
先辈:title 元素的先辈是 book 元素和 bookstore 元素
后代:bookstore 的后代是 book、title、author、year 以及 price 元素
语法
举例:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性 |
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
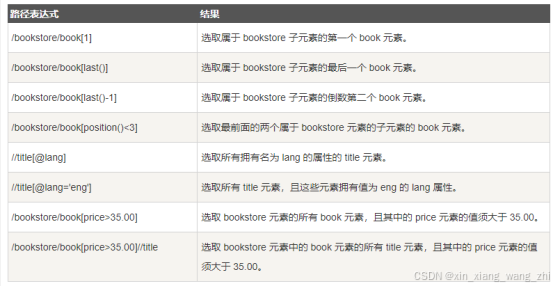
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

绝对路径
绝对路径:表示页面元素在网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
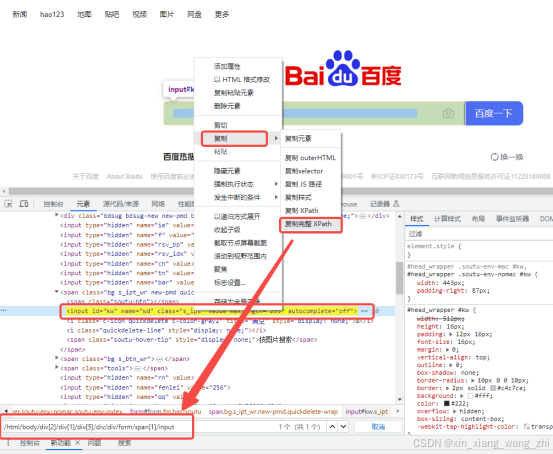
element = driver.find_element(By.XPATH, ”/html/body/div[2]/div[1]/div[5]/div/div/form/span[1]/input”)相对路径
相对路径:从匹配选择的当前节点开始选择文档中的节点,而不考虑它们的位置,起始于双斜杠(//)。
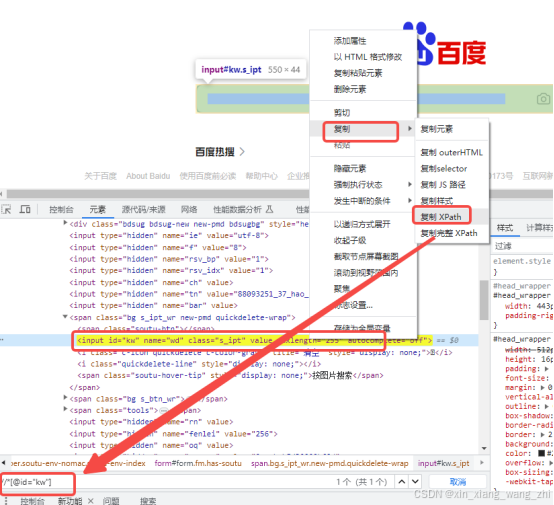
element = driver.find_element(By.XPATH, ‘//*[@id="kw"]’)向前搜索
# 向前搜索,“..”表示选择当前节点的父节点
# 点击搜索
driver.find_element(By.XPATH, '//*[@id="kw"]/../../span[2]/input').click()根据文本定位
可用于新增一个文本后,查找文本是否新增成功。
例:
<div>文本</div>
<div>文本1</div>
定位div元素且div的text内容为“文本”:
//div[text()='文本']
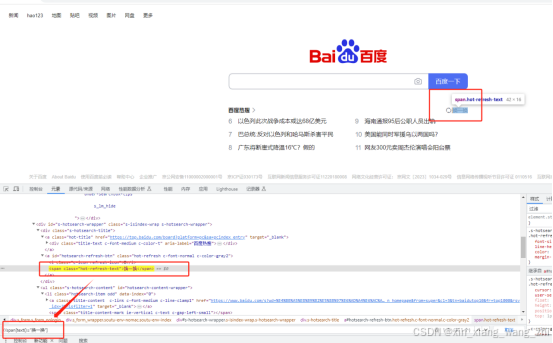
element = driver.find_element(By.XPATH, ‘//span[text()="换一换"]’)根据部分属性内容定位(使用contains()函数)
contains() 是一个XPath函数,用于检查一个字符串是否包含另一个子字符串。XPath 可以使用 contains() 函数来匹配 属性包含指定内容的元素。
注:使用 contains() 函数匹配时查询出的是单个还是多个元素,根据需要使用定位方法find_element()或find_elements()。
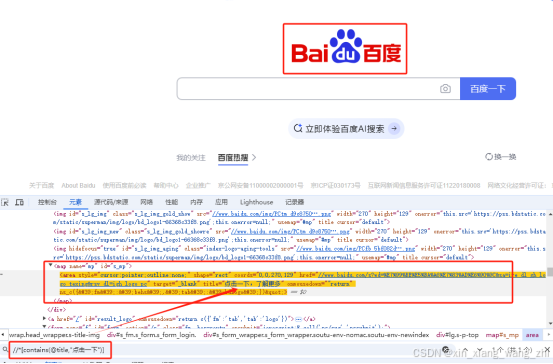
如上图若只知道元素属性title的部分内容“点击一下”
element = driver.find_element(By.XPATH, ‘//*[contains(@title,"点击一下")]’)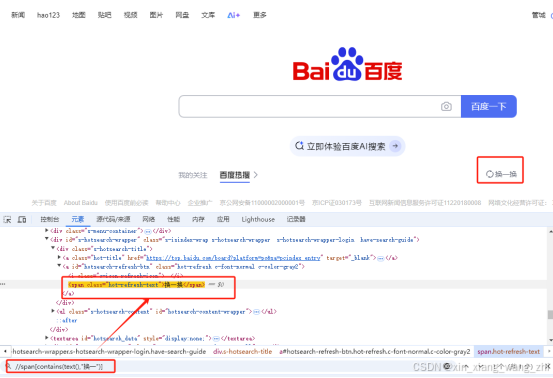
element = driver.find_element(By.XPATH, ‘//span[contains(text(),"换一")]’)定位方法
查找单个元素
driver.find_element(By.ID, 'kw').send_keys('单个元素')
嵌套查找
在查找一个元素时,可以先找到元素的父辈,在从父辈的子集找元素
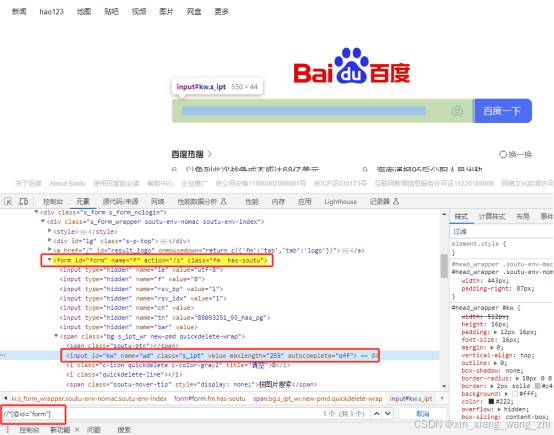
form = driver.find_element(By.ID, 'form')
form.find_element(By.NAME, 'wd').send_keys('嵌套查找')优化定位器
使用CSS或XPath在单个命令中查找该元素
driver.find_element(By.CSS_SELECTOR, '#form [name="wd"]').send_keys('优化定位器')查找一组元素
elements = driver.find_elements(By.XPATH, '//*[@id="s-top-left"]/a')
print(len(elements))
for e in elements:
print(e.text)
time.sleep(2)从元素下查找一组元素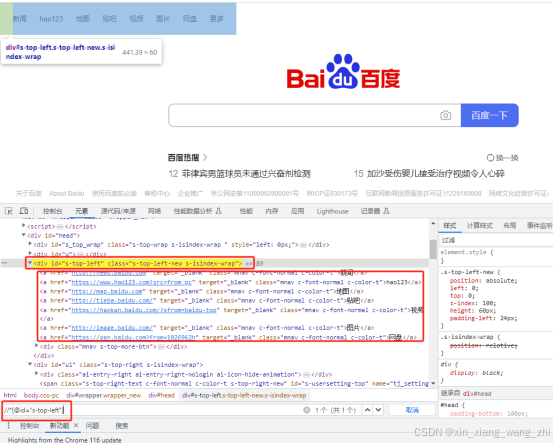
element = driver.find_element(By.ID, 's-top-left')
elements = element.find_elements(By.TAG_NAME, 'a')
print(len(elements))
for e in elements:
print(e.text)
time.sleep(2)获取活动元素
# 它用于跟踪(或)查找在当前浏览上下文中具有焦点的DOM元素。
# switch_to.active_element 返回当前焦点的WebElement对象
# get_attribute可以获取元素属性
driver.find_element(By.ID, 'kw').clear()
# driver.find_element(By.ID, 'kw').send_keys('获取活动元素')
attr = driver.switch_to.active_element.get_attribute("id")
print(attr)传参
传递参数,s是字符串,d指数字
number = 2
element = driver.find_element(By.XPATH, '//div[text()=%s]' % (repr(name)))
driver.find_element(By.XPATH, '//*[@id="s-top-left"]/a[%d]' % number)注:Repr是python的一个函数,可以返回字符串,,,也可以直接使用引号将%s引起来,如下方代码。但是不能同时使用repr和引号会因为存在多余引号报错。
element = driver.find_element(By.XPATH, '//div[text()="%s"]' % name)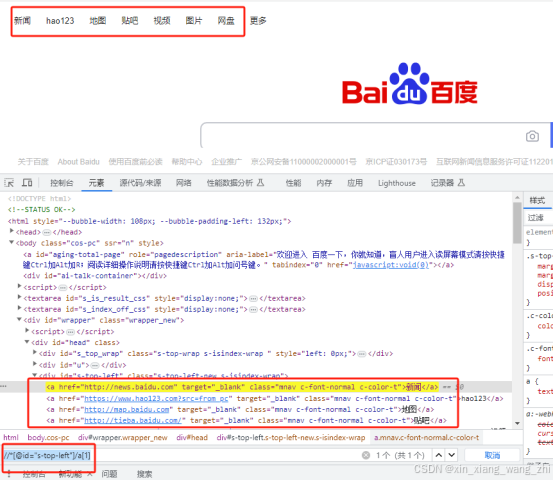
is_displayed(),判断元素在页面中是否显示
判断元素在页面中是否显示,前提是元素存在,在元素存在的情况下判断其是显示还是隐藏状态,存在时返回True,不存在时返回FALSE。
driver.find_element(By.TAG_NAME, "select").is_displayed()判断元素是否存在
方法一:
selenium因为找不到元素会抛出异常,导致执行结束
可以考虑使用driver.find_elements(),找不到元素时就会返回空列表,使用if-else语句,判断列表是否为空,非空,则正常找到元素,进行后续代码执行;空,则直接跳过,执行其他代码
if len(list) != 0 #判断列表的长度是否为0
# 非0,执行的代码
else:
#为0,执行的代码方法二:
函数在找不到网页元素的时候,会抛出异常,可以通过try/except捕获该异常进行判断。如下通过函数is_element_exist来判断网页中的元素是否存在。
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
import selenium.common.exceptions
def is_element_exist(self, element):
try:
self.find_element(By.Xpath, element)
return 1
except selenium.common.exceptions.NoSuchElementException:
return 0
def main():
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
driver.get('http://www.baidu.com')
if is_element_exist(driver, '//table[@calss="c-table opr-toplist1-table"]'):
print("元素2存在")
else:
print("元素2不存在")
if is_element_exist(driver, '//img[@id="s_lg_img"]'):
print("元素1存在")
else:
print("元素1不存在")
if __name__ == '__main__':
main()
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









