







我们经常会去百度上找一些图片啊素材啊什么的,但是要一个个下载又很麻烦。为了解决这个问题,我们要使用工具来帮助我们完成这些工作。
一、 准备工作
- 1、语言:Python3
- 2、需要使用的模块:
- requests 用于进行网络访问,对请求进行发送并接收服务器的响应
- re 正则表达式模块,为正则表达式相关操作提供支持
- hashlib 提供字符加密功能
- time 时间相关模块
- 3、环境:Python 3.7
- 4、IDE:Visual Studio Code
二、分析网页
查看百度图片搜索结果页,往下拉会有新的图片出现,通过网页的开发者工具,可以看到是通过Ajax进行异步请求获取图片的。
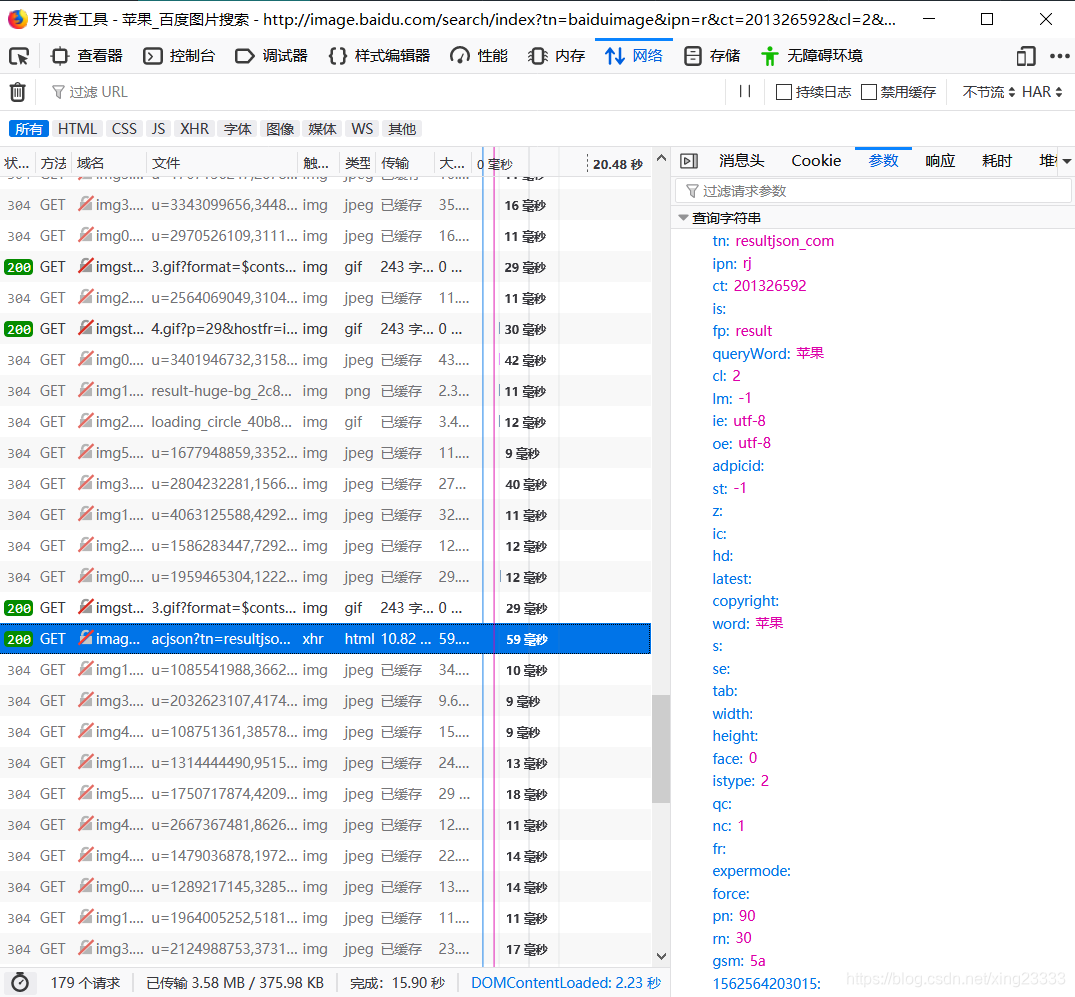 这个请求相应的是Json数据,这里我们需要获取thumbURL的数据,即缩略图地址。
这个请求相应的是Json数据,这里我们需要获取thumbURL的数据,即缩略图地址。
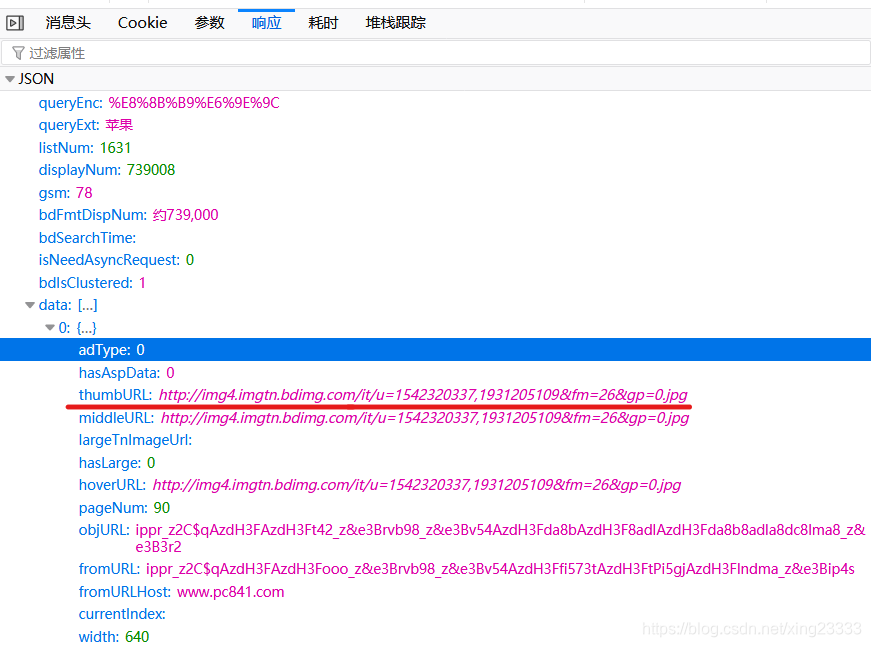 那要找的东西知道了,怎么去找呢,我们先要了解这个Ajax请求如何组成的,请求的参数很多,但大多数对我们来说是不需要的,需要从中找出几个关键的参数!如下图。
那要找的东西知道了,怎么去找呢,我们先要了解这个Ajax请求如何组成的,请求的参数很多,但大多数对我们来说是不需要的,需要从中找出几个关键的参数!如下图。
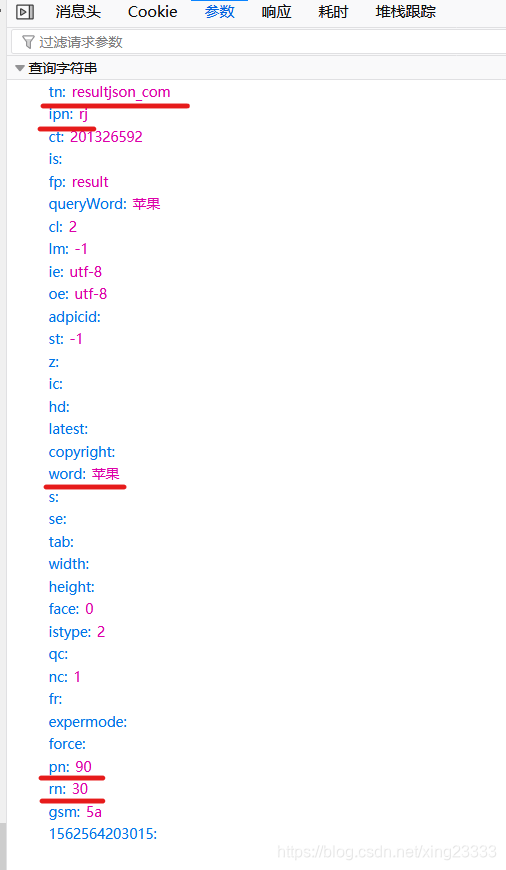
word是请求的关键字,pn图片开始的位置,即从已出现的最后一张图片开始继续获取图片,rn是每次请求的图片数量,另外两个也不可以少。
三、代码实现
网页元素分析好了,现在就要使用代码去实现它!以下是完整代码。
import requests #导入所需的模块
import re
import hashlib
import time
def main():
pictype = input("请输入要爬取的图片类型:") #这里获取两个值,想要爬取的图片类型以及需要的页数
page = input("请输入要爬取的页数:")
getImage(pictype,page)
def getImage(pictype,page):
count = 0 #计数,每爬取一张图片count+1
for i in range(int(page)):
pn = 30 * i #开始位置为30 * i,每页为30张图片
'''
这里是请求的参数
'''
data = {'word':pictype,'pn':pn,'tn':'resultjson_com','ipn':'rj','rn':30}
url = "https://image.baidu.com/search/acjson" #请求的url
req = requests.get(url,headers={},params=data) #发送get请求
if str(req.status_code) == '200': #根据状态码判断请求是否成功
print('请求成功!url:' + req.url)
else:
print('请求失败!状态码:{},url:{}'.format(req.status_code,req.url))
resp = req.content.decode() #获取请求的主体数据
img_links = re.findall(r'thumbURL.*?\.jpg',resp) #寻找获得的数据中所有thumbURL数据,即缩略图图片的地址
for link in img_links: # 遍历每一个链接
print('正在保存图片:' + link)
m = hashlib.md5()
m.update(link.encode()) #使用md5加密图片链接,获得唯一的名字
name = m.hexdigest() #以16进制形式返回字符串
ret = requests.get(link[11:], headers = {}) #发送请求,根据链接获取图片
image_content = ret.content #获取响应的主体数据
'''
文件名格式是:链接的md5加密字符串 + count+.jpg
'''
filename = './image/' + name + '_' + str(count) + '.jpg'
with open(filename, 'wb') as f: #保存图片到指定文件夹
f.write(image_content)
print('保存成功,图片名为:{}'.format(filename))
count += 1 #完成,count+1
if __name__ == '__main__':
main()
四、运行结果
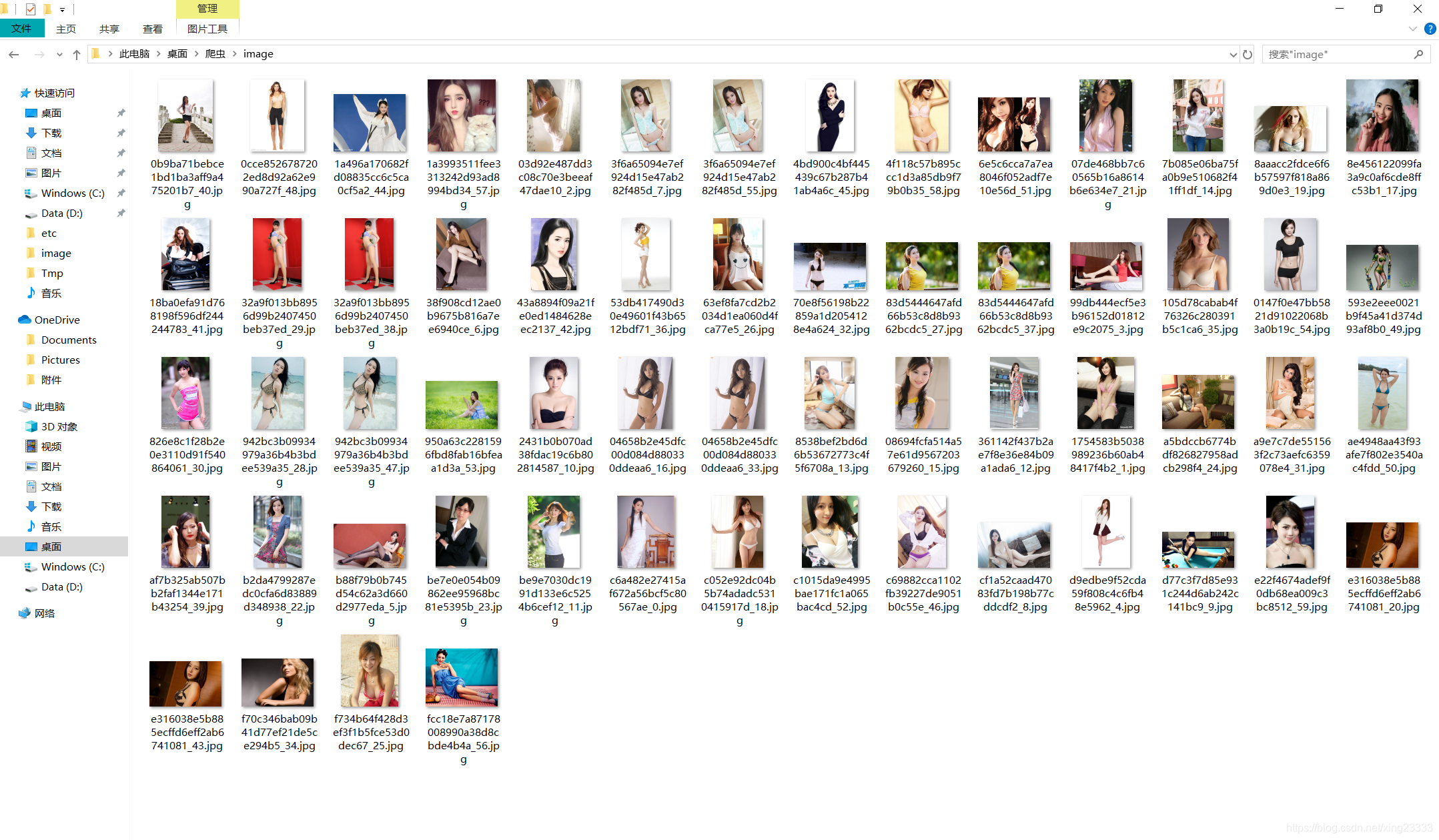
(手动捂脸
五、总结
这次的实验总的来说还行,也是通过这次才了解到还可以通过解析返回的json数据来进行数据爬取(之前的一次爬取数据我还傻傻地去模拟浏览器然后再获取数据,速度巨慢==),不过还是各有各的好处,比如必应的图片,就无法获取json数据,只能模拟浏览器等数据加载完成后再去爬取数据。















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









