







文章目录
一、Redis为什么快?
1、Redis基于内存
2、Redis给予Reactor模式开发了一套高效的事件处理模型
主要是单线程事件循环和IO多路复用。
3、内置多种优化过后的数据机构实现
二、为什么要用Redis/为什么要用缓存?
1、高性能
Redis直接操作缓存相对于从磁盘中访问数据库速度快得多。
2、高并发
操作缓存承受的数据库请求数量远远大于直接访问数据库,请求直接访问缓存不经过数据库就提高了系统整体并发量。
三、Redis的数据结构
5中基础数据结构
1、String(字符串)
(1)常用命令
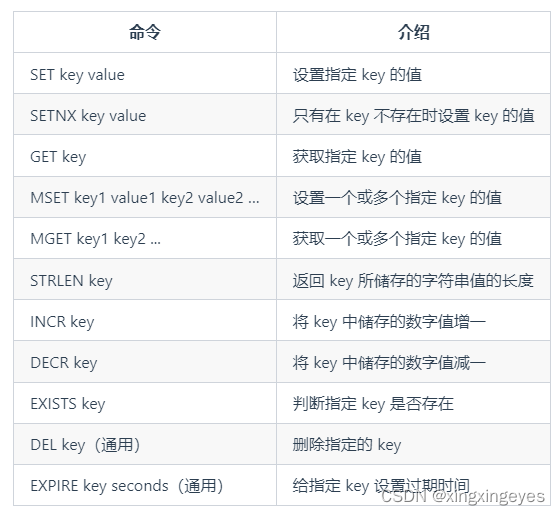
(2)应用场景
① 需要存储常规数据的场景
举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
相关命令:SET、GET。
② 需要计数的场景
举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
相关命令:SET、GET、 INCR、DECR 。
③ 分布式锁
利用 SETNX key value 命令可以实现一个最简易的分布式锁(存在一些缺陷,通常不建议这样实现分布式锁)。
2、List(l列表)
(1)常用命令
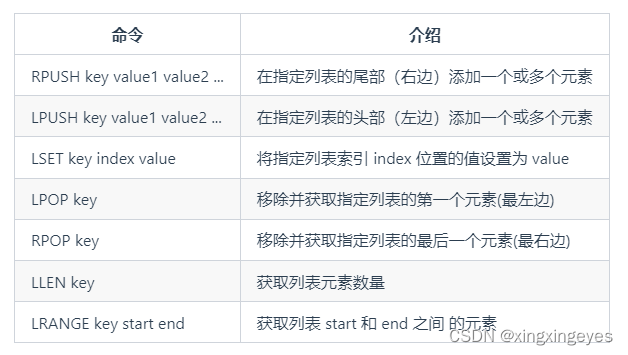
(2)应用场景
① 信息流展示
举例:最新文章、最新动态。
相关命令:LPUSH、LRANGE。
②消息队列
Redis List 数据结构可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
3、Hash(散列)
(1)常用命令

(2)应用场景
对象存储场景
举例:用户信息、商品信息、文章信息、购物车信息。
相关命令:HSET (设置单个字段的值)、HMSET(设置多个字段的值)、HGET(获取单个字段的值)、HMGET(获取多个字段的值)。
4、Set(集合)
(1)常用命令
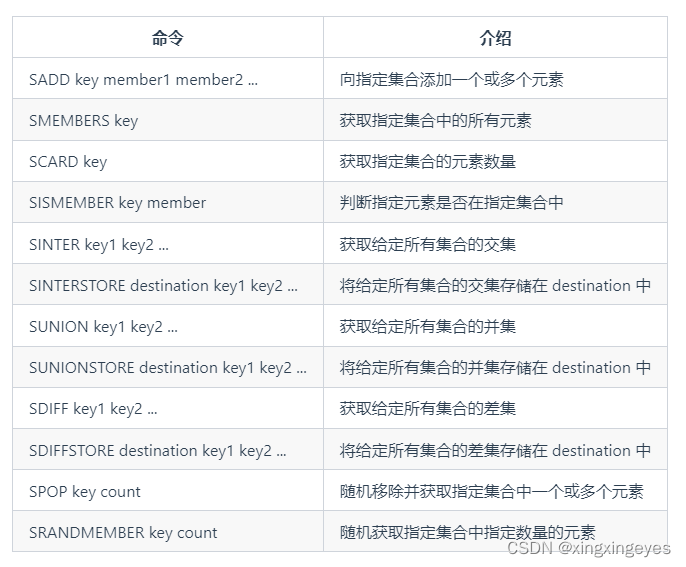
(2)应用场景
① 需要存放的数据不能重复的场景
举例:网站 UV 统计(数据量巨大的场景还是 HyperLogLog更适合一些)、文章点赞、动态点赞等场景。
相关命令:SCARD(获取集合数量) 。
② 需要获取多个数据源交集、并集和差集的场景
举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
相关命令:SINTER(交集)、SINTERSTORE (交集)、SUNION (并集)、SUNIONSTORE(并集)、SDIFF(差集)、SDIFFSTORE (差集)。
③ 抽奖系统。
5、Zset(有序集合)
(1)常用命令

(2)应用场景
① 需要随机获取数据源中的元素根据某个权重进行排序的场景
举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
相关命令:ZRANGE (从小到大排序)、 ZREVRANGE (从大到小排序)、ZREVRANK (指定元素排名)。
②需要存储的数据有优先级或者重要程度的场景 比如优先级任务队列。
举例:优先级任务队列。
相关命令:ZRANGE (从小到大排序)、 ZREVRANGE (从大到小排序)、ZREVRANK (指定元素排名)。
Redis 3 种特殊数据结构
1、Bitmap
需要保存状态信息(0/1 即可表示)的场景
举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
相关命令:SETBIT、GETBIT、BITCOUNT、BITOP。
2、HyperLogLog
数量量巨大(百万、千万级别以上)的计数场景
举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
相关命令:PFADD、PFCOUNT 。
3、Geospatial index
需要管理使用地理空间数据的场景
举例:附近的人。
相关命令: GEOADD、GEORADIUS、GEORADIUSBYMEMBER 。
四、Redis持久化机制
1、RDB持久化
Redis 可以通过创建快照来获得存储在内存里面的数据在 某个时间点 上的副本。
Redis 提供了两个命令来生成 RDB 快照文件:
save : 同步保存操作,会阻塞 Redis 主线程;
bgsave : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
2、AOF持久化
(1)概念
每执行一条更改Redis的数据的命令,先写入缓冲区在写到AOF文件中,再根据持久化方式写入磁盘。
(2)持久化方式
① 执行写操作后立即刷盘
② 每秒同步一次AOF文件
③ 操作系统决定何时同步,一般30秒一次
(3)Redis 4.0 对于持久化机制做了什么优化?
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭)。
优点:快速加载避免丢失过多数据。
缺点:可读性差。
(4)如何选择 RDB 和 AOF?
① Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
② 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 ③ AOF 引擎错误。
如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化。
五、Redis单线程模型
1、Redis6.0 之前为什么不使用多线程?
(1)单线程编程容易并且更容易维护。
(2)Redis 的性能瓶颈不在 CPU ,主要在内存和网络。
(3)多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
(4)Redis 在 4.0 之后的版本使用多线程来处一些对大键值对的删除操作的命令。
2、Redis6.0 之后为何引入了多线程?
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
六、Redis内存管理
(1)过期时间处理有助于缓解内存消耗,还可用于短信验证码1分钟失效功能。
(2)过期数据删除策略
① 惰性删除:取出key时过期检查(CPU友好)。
② 定时删除:每隔一段时间删除一批过期的key(内存友好)。
Redis 采用的是 定期删除+惰性/懒汉式删除 。
七、Redis性能优化
1、使用批量操作减少网络传输
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT(Round Trip Time往返时间)。
2、大量 key 集中过期问题
定期删除(主线程执行)完成才执行客户端请求,导致客户端响应速度慢。
解决:
① 给key设置随机过期时间。
② 开启lazy-free(惰性删除/延迟释放)子线程释放key使用的内存。
3、Redis bigkey
如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。
bigkey的危害:消耗更多内存和带宽,还会对性能造成较大影响。
如何发现bigkey?
① 使用 Redis 自带的 --bigkeys 参数来查找。
② 借助开源工具分析 RDB 文件。
③ 借助公有云的 Redis 分析服务。
如何处理bigkey?
① 分割 bigkey:将一个 bigkey 分割为多个小 key。这种方式需要修改业务层的代码,一般不推荐这样做。
② 手动清理:Redis 4.0+ 可以使用 UNLINK 命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用 SCAN 命令结合 DEL 命令来分批次删除。
③ 采用合适的数据结构:比如使用 HyperLogLog 统计页面 UV。
4、Redis hotkey(热 Key)
一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 hotkey。重大热搜、秒杀商品容易出现hotkey。
hotkey 有什么危害?
占用大量CPU和带宽,影响其它请求正常处理,访问超出Redis处理能力会直接宕机。请求落到数据库可能导致数据库崩溃。
如何发现 hotkey?
① 使用 Redis 自带的 --hotkeys 参数来查找。
② 使用monitor 命令。
③ 根据业务情况提前预估。
④ 业务代码中记录分析。
如何解决 hotkey?
读写分离:主节点处理写请求,从节点处理读请求。
使用 Redis Cluster:将热点数据分散存储在多个 Redis 节点上。
二级缓存:hotkey 采用二级缓存的方式进行处理,将 hotkey 存放一份到 JVM 本地内存中(可以用 Caffeine)。
5、Redis 内存碎片
为什么会有 Redis 内存碎片?
① Redis 存储存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。
② 频繁修改 Redis 中的数据也会产生内存碎片。当 Redis 中的某个数据删除时,Redis 通常不会轻易释放内存给操作系统。
如何查看 Redis 内存碎片的信息?
使用 info memory 命令即可查看 Redis 内存相关的信息。
如何清理 Redis 内存碎片?
① 直接通过 config set 命令将 activedefrag 配置项设置为 yes 即可。
② 重启节点可以做到内存碎片重新整理。
八、Redis生产问题(重要)
1、缓存穿透
大量请求的key不在缓存和数据库中,导致请求直接访问数据库,严重导致数据库宕机。
解决办法:
① 校验不合法的参数。
② 缓存无效key:将无效key写到Redis并设置和过期时间(大量不同的key无效)。
③ 布隆过滤器:把所有可能存在的请求的只放在布隆过滤器中,用户请求先判断是否在布隆过滤器中。
2、缓存击穿
请求的key时热点数据,不存在缓存中(通常已过期),导致大量请求打到数据库上,严重导致数据库宕机。例如缓存中某个秒杀商品数据突然过期。
有哪些解决办法?
(1)设置热点数据永不过期或者过期时间较长。
(2)针对热点数据提前预热,将过期时间延长到秒杀结束。
(3)获取互斥锁,保证只有一个请求落到数据库。
缓存穿透和缓存击穿有什么区别?
(1)缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
(2)缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。
3、缓存雪崩
缓存同一时间大面积失效,导致大量请求落到数据库上,对数据库造成巨大压力。缓存服务器宕机也会导致缓存雪崩现象。
有哪些解决办法?
(1)设置不同的失效时间比如随机设置缓存的失效时间。
(2)缓存永不失效(不太推荐,实用性太差)。
(3)设置二级缓存。
缓存雪崩和缓存击穿有什么区别?
缓存雪崩是缓存中大量数据失效,请求打到数据库中,缓存击穿时某个热点数据不在缓存中(通常数据过期),请求打到数据库中。
如何保证缓存和数据库数据的一致性?















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









