







文章目录
一、基础
1.1) 安装
1)mac 下安装 scala
brew install coursier/formulas/coursier && cs setup
2) brew 安装
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
1.2)教程
二、 语法
2.1)Trait
Scala Trait(特征)
Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。
与接口不同的是,它还可以定义属性和方法的实现。
2.2) 数组
-
循环数组:
https://blog.csdn.net/hongchenshijie/article/details/104011381 -
scala的数组的大小的固定的
// 01 scala中的数组
var list1 = Array(1, 2)
// 02 数组值修改
list1(0) = 0
2.3)List -有序的对象集合
- scala的 list比较鸡肋,还不如其 数组强大,list中的长度不但是固定的,而且里边的元素还不让修改,不过里边的元素可以是重复的元素
如果要使用变长的,可以使用 ListBuffer
var list = List(1, 2, 3)
// 下面的操作是报错的
list(0) = 1
2.4)Set - 无序的不可重复对象集合
- scala 中的 Set 有 不可变和可变两个版本,分别是
scala.collectioin.immutable中 和scala.collection.mutable中的,默认是 不可变的,需要可变的,则需要导入前边说的这个包 - 虽然可变Set和不可变Set都有添加或删除元素的操作,但是有一个非常大的差别。对不可变Set进行操作,会产生一个新的set,原来的set并没有改变,这与List一样。 而对可变Set进行操作,改变的是该Set本身,与ListBuffer类似。
不可变 Set
scala> var immutableSet = scala.collection.immutable.Set(1,2)
immutableSet: scala.collection.immutable.Set[Int] = Set(1, 2)
scala> immutableSet.add(3)
<console>:30: error: value add is not a member of scala.collection.immutable.Set[Int]
immutableSet.add(3)
^
可变Set
scala> var mutableSet = scala.collection.mutable.Set(1, 2)
mutableSet: scala.collection.mutable.Set[Int] = Set(1, 2)
scala> mutableSet.add(3)
res24: Boolean = true
scala> mutableSet
res25: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
2.5) Seq
- Seq 是 Scala的集合之一,另外两个是
Set和Map,Seq也是有 可变和不可变两种 - 参考文档:https://blog.csdn.net/weixin_40161254/article/details/115738584
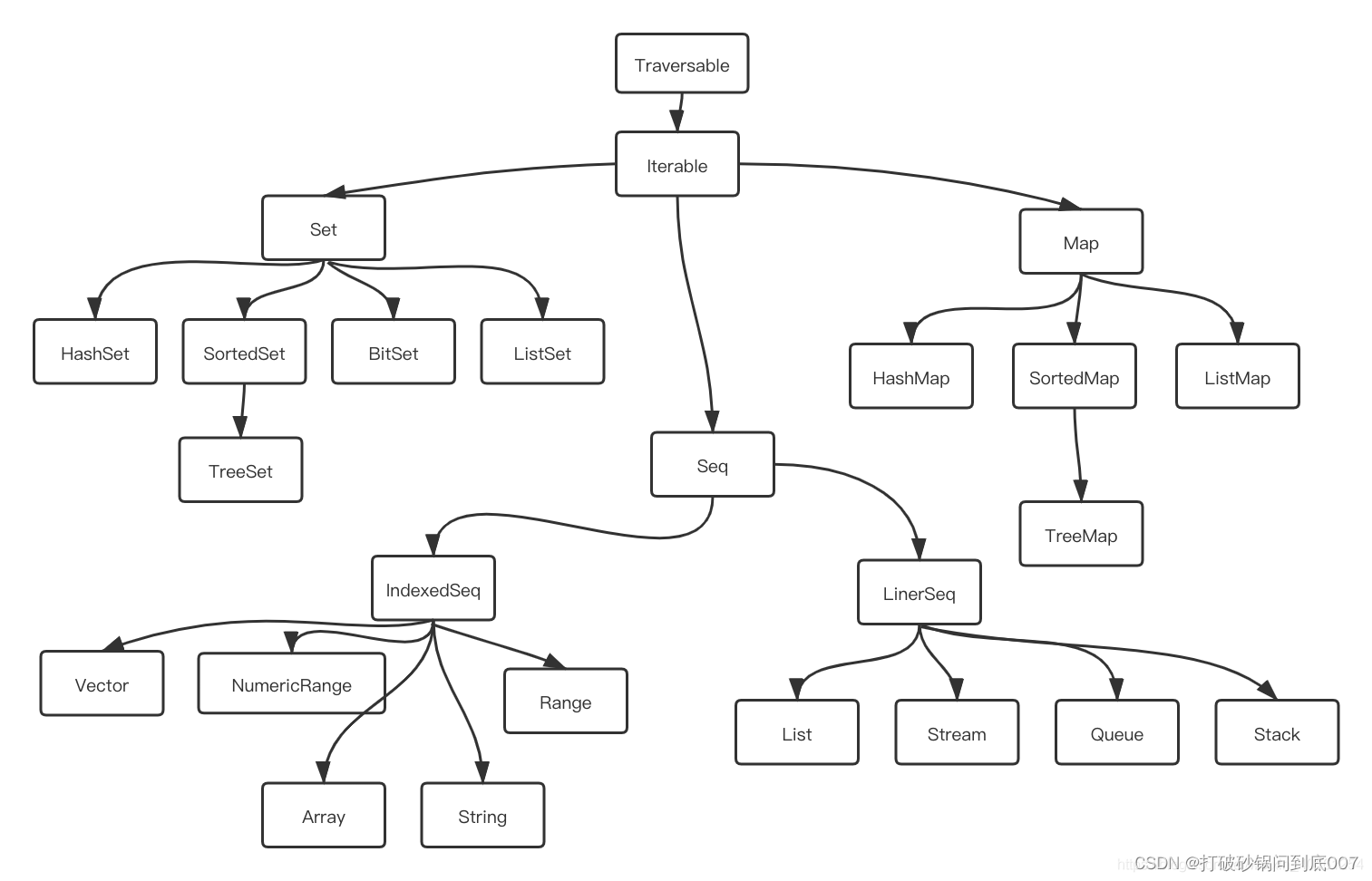
-说明: 序列表示一个以特定顺序排列的元素集合。因为该元素有个定义好的顺序,所以可以按照它们在集合中的位置进行访问。例如,可以请求序列中第n个元素。
Seq下包含了Range、ArrayBuffer、List等子trait。其中Range就代表了一个序列,通常可以使用“1 to10”这种语法来产生一个Range。 ArrayBuffer就类似于Java中的ArrayList。
序列有三个实现类,分别是Array、List和Vector。
Seq添加元素: https://blog.csdn.net/qq_39532946/article/details/77772865
scala> data :+ 6
res29: scala.collection.mutable.Seq[Int] = ArrayBuffer(1, 2, 3, 4, 5, 6)
2.6)元组
- Scala 可以返回多个参数,用元组就可以做到这一点
- info._1 访问元组中的第一个元素, info._2 是访问元组中的第2个元素
2.7) 其他语法
- 传递变长参数,在参数类型后加上 * 就行
- 可以为参数提供默认值
- scala 还支持 命名参数比如
power( base = 2, exponent = 3) - scala 还支持 隐式传参,由调用者确定传递的参数的默认值
三、Scala 与 Java 的区别
-
https://cloud.tencent.com/developer/article/1758874
-
- Scala中不支持break
使用return替代
在循环中使用if和布尔类型变量
导入Java中支持break的包
-
- 通配符
Java中使用*进行通配
Scala中使用_进行通配
-
3)Scala的 ==
Scala中的==等价于 Java的 equals() 方法;
Scala中的 操作符eq等价于 Java的==操作 -
4) Scala的初学者,可以先在代码中 使用 util.HashMap等 Java的类来实现自己的逻辑
四、Spark相关
4.1) RDD
4.1.1) RDD的创建
- 01 从 Driver 程序的数据集生成 RDD
val data = Seq(1, 2, 3, 4, 5)
// sc 指的是 saprk-shell已经创建好的 sparkContext
val rdd = sc.parallelize(data)
parallelize的理解: 第2个参数,代表了 partition RDD分区,Spark在运行时,一般 RDD操作会为每个RDD 分区运行一个 Job,关于 Job,可以简单理解为 Java的一个线程
- 02 从外部数据集生成 RDD
主要是使用 sparkContext的textFile()方法
4.1.2) RDD的使用
- Spark编程时,RDD操作的一个禁忌,就是 RDD操作不能嵌套吊影,即在 RDD 操作的传入的函数参数的函数体中,不可以出现 RDD的调用
foreach是 RDD的 Action 操作- rdd的求和,可以使用 rdd.sum, 或者
rdd.reduce(_+_)
4.1.2.1) 两类操作
-
Action操作- 这个的输入是 RDD, 输出不再是 RDD, 也就意味这输出不是分布式的,而是回送到
Driver程序
- 这个的输入是 RDD, 输出不再是 RDD, 也就意味这输出不是分布式的,而是回送到
-
Transformation操作 -
算子操作
https://blog.csdn.net/yu0_zhang0/article/details/80095237
4.2) Spark SQL
- 概述: 使用方式。Spark SQL有两种使用方式:
== 一种是分布式 SQL引擎,此时主要是写 SQL就可以进行计算
== 一种是在 Spark 程序中,通过领域 API的形式来操作数据(被抽象为DataFrame)
4.2.1) DataFrame
4.2.1.1)创建DataFrame
- 有两种方法:
- 从 RDD创建:
== ① 使用反射的方法从 RDD 创建 DataFrame
== ② 使用程序动态从 RDD 创建 DataFrame
4.2.1.2)DataFrame的使用
- 可以通过 领域API的方式访问 DataFrame
- 可以将 DataFrame 注册成表,然后通过 SQL语句的方式来访问
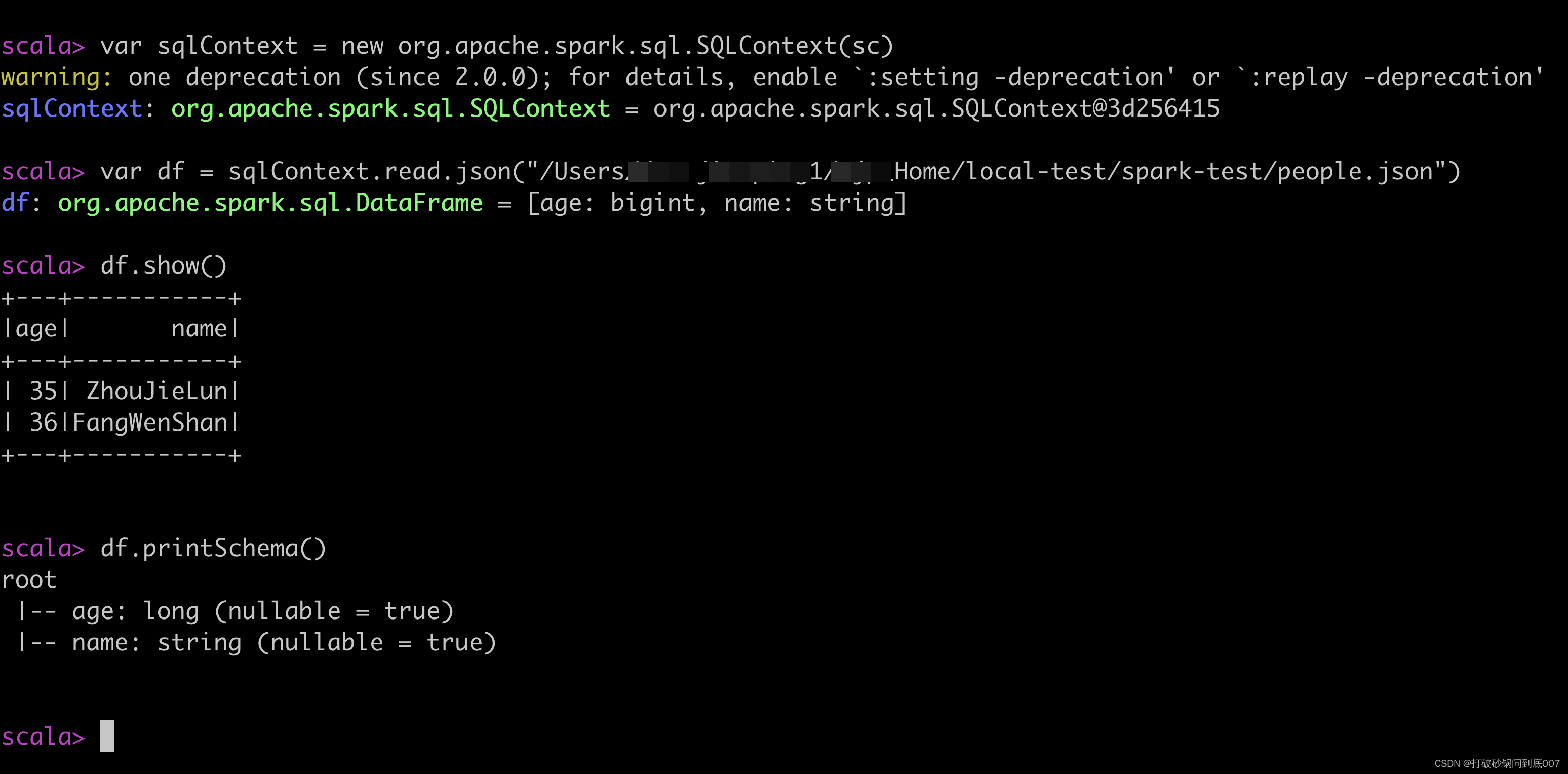
var sqlContext = new org.apache.spark.sql.SQLContext(sc)
scala> df.registerTempTable("people")
warning: one deprecation (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> sqlContext.sql("select * from people")
res21: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> var result = sqlContext.sql("select * from people")
result: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> result.show()
+---+-----------+
|age| name|
+---+-----------+
| 35| ZhouJieLun|
| 36|FangWenShan|
+---+-----------+

五、面向对象
- Scala Object对象本身就是 单实例的,它的方法都是静态方法。
- Scala 中,
Any类型是所有类型的父类型, 而Nothing则是一切类型的子类型
六、其他
6.1)以独立脚本方式运行 Scala 代码
- 文件名
hello.sh
#!/usr/bin/env scala
println("Hello " + args(0))
chomd +x hell0.sh
./hello.sh Scala
运行结果
Hello Scala
七、Spark优化
7.1)优化原则
- 尽量避免使用shuffle类算子
https://tech.meituan.com/2016/04/29/spark-tuning-basic.html- 比如reduceByKey、join等算子,都会触发shuffle操作。















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









